Safe Reinforcement Learning in Black-Box Environments via Adaptive Shielding

0
🏅
Sign in to get full access
Overview
- Reinforcement learning (RL) agents can pose safety risks when deployed in real-world environments, especially when the environment is unknown or "black-box".
- The paper introduces ADVICE, a novel technique to distinguish safe and unsafe features of state-action pairs during RL agent training, preventing the agent from taking potentially hazardous actions.
- ADVICE is evaluated against other state-of-the-art safe RL exploration methods, demonstrating its ability to significantly reduce safety violations while maintaining competitive outcome rewards.
Plain English Explanation
Reinforcement learning (RL) is a powerful technique that allows AI models to learn how to make decisions by interacting with their environment and receiving rewards or penalties. However, when these RL agents are deployed in the real world, they can pose significant safety risks, especially if the environment they're operating in is unknown or unpredictable.
The researchers behind this paper have developed a new tool called ADVICE (Adaptive Shielding with a Contrastive Autoencoder) to help make RL agents safer during the training process. ADVICE works by analyzing the state-action pairs the RL agent is considering and identifying which ones are potentially unsafe or hazardous. It then "shields" the agent, preventing it from taking those unsafe actions.
This is particularly important when training RL agents in unknown, "black-box" environments, where there may be limited prior knowledge about the domain or task. By using ADVICE, the researchers were able to show that RL agents could be trained to achieve good outcomes while significantly reducing the number of safety violations, compared to other state-of-the-art safe RL exploration techniques like dynamic model predictive shielding, adaptive control regularization, and learned non-Markovian safety.
Technical Explanation
The core idea behind ADVICE is to use a contrastive autoencoder to distinguish between safe and unsafe state-action pairs during the RL agent's training. The contrastive autoencoder is trained to encode the state-action pairs into a latent representation, where safe and unsafe pairs are separated as much as possible.
During training, the RL agent's policy is "shielded" by only allowing actions that correspond to state-action pairs that are classified as safe by the contrastive autoencoder. This helps the agent learn a policy that avoids hazardous actions, even in unknown environments.
The researchers conducted a comprehensive experimental evaluation of ADVICE, comparing it to other state-of-the-art safe RL exploration techniques. They found that ADVICE significantly reduced the number of safety violations during training while maintaining a competitive level of outcome reward, demonstrating its effectiveness in enabling safe exploration for RL agents.
Critical Analysis
The researchers acknowledge that ADVICE relies on the assumption that the contrastive autoencoder can accurately distinguish between safe and unsafe state-action pairs. This assumption may not always hold, especially in highly complex or ambiguous environments.
Additionally, the paper does not address the potential computational overhead of running the contrastive autoencoder during the RL agent's training, which could slow down the overall learning process.
Further research could explore ways to improve the robustness and efficiency of the ADVICE approach, such as by investigating alternative architectural choices for the contrastive autoencoder or exploring ways to integrate the safe exploration mechanism more seamlessly into the RL agent's policy learning.
Conclusion
The ADVICE technique presented in this paper represents an important step forward in enabling safe exploration for reinforcement learning agents, particularly in unknown or "black-box" environments. By leveraging a contrastive autoencoder to identify and shield against potentially hazardous actions, ADVICE can help RL agents achieve good outcomes while significantly reducing safety violations during the training process.
As RL continues to be applied to an increasingly wide range of real-world applications, techniques like ADVICE will become increasingly crucial in ensuring the safe and responsible deployment of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
Safe Reinforcement Learning in Black-Box Environments via Adaptive Shielding
Daniel Bethell, Simos Gerasimou, Radu Calinescu, Calum Imrie
Empowering safe exploration of reinforcement learning (RL) agents during training is a critical impediment towards deploying RL agents in many real-world scenarios. Training RL agents in unknown, black-box environments poses an even greater safety risk when prior knowledge of the domain/task is unavailable. We introduce ADVICE (Adaptive Shielding with a Contrastive Autoencoder), a novel post-shielding technique that distinguishes safe and unsafe features of state-action pairs during training, thus protecting the RL agent from executing actions that yield potentially hazardous outcomes. Our comprehensive experimental evaluation against state-of-the-art safe RL exploration techniques demonstrates how ADVICE can significantly reduce safety violations during training while maintaining a competitive outcome reward.
Read more5/29/2024

0
Safety through Permissibility: Shield Construction for Fast and Safe Reinforcement Learning
Alexander Politowicz, Sahisnu Mazumder, Bing Liu
Designing Reinforcement Learning (RL) solutions for real-life problems remains a significant challenge. A major area of concern is safety. Shielding is a popular technique to enforce safety in RL by turning user-defined safety specifications into safe agent behavior. However, these methods either suffer from extreme learning delays, demand extensive human effort in designing models and safe domains in the problem, or require pre-computation. In this paper, we propose a new permissibility-based framework to deal with safety and shield construction. Permissibility was originally designed for eliminating (non-permissible) actions that will not lead to an optimal solution to improve RL training efficiency. This paper shows that safety can be naturally incorporated into this framework, i.e. extending permissibility to include safety, and thereby we can achieve both safety and improved efficiency. Experimental evaluation using three standard RL applications shows the effectiveness of the approach.
Read more5/31/2024

0
Verification-Guided Shielding for Deep Reinforcement Learning
Davide Corsi, Guy Amir, Andoni Rodriguez, Cesar Sanchez, Guy Katz, Roy Fox
In recent years, Deep Reinforcement Learning (DRL) has emerged as an effective approach to solving real-world tasks. However, despite their successes, DRL-based policies suffer from poor reliability, which limits their deployment in safety-critical domains. Various methods have been put forth to address this issue by providing formal safety guarantees. Two main approaches include shielding and verification. While shielding ensures the safe behavior of the policy by employing an external online component (i.e., a ``shield'') that overrides potentially dangerous actions, this approach has a significant computational cost as the shield must be invoked at runtime to validate every decision. On the other hand, verification is an offline process that can identify policies that are unsafe, prior to their deployment, yet, without providing alternative actions when such a policy is deemed unsafe. In this work, we present verification-guided shielding -- a novel approach that bridges the DRL reliability gap by integrating these two methods. Our approach combines both formal and probabilistic verification tools to partition the input domain into safe and unsafe regions. In addition, we employ clustering and symbolic representation procedures that compress the unsafe regions into a compact representation. This, in turn, allows to temporarily activate the shield solely in (potentially) unsafe regions, in an efficient manner. Our novel approach allows to significantly reduce runtime overhead while still preserving formal safety guarantees. We extensively evaluate our approach on two benchmarks from the robotic navigation domain, as well as provide an in-depth analysis of its scalability and completeness.
Read more6/24/2024
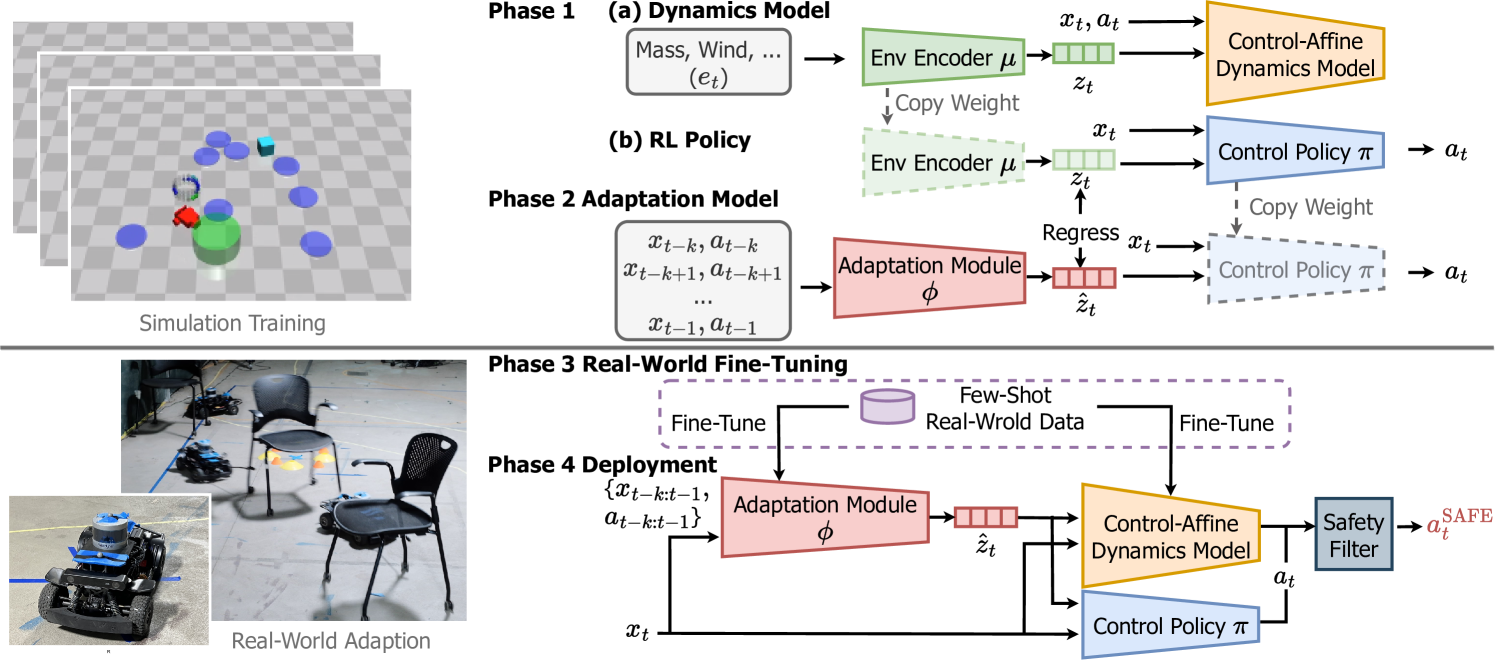
0
Safe Deep Policy Adaptation
Wenli Xiao, Tairan He, John Dolan, Guanya Shi
A critical goal of autonomy and artificial intelligence is enabling autonomous robots to rapidly adapt in dynamic and uncertain environments. Classic adaptive control and safe control provide stability and safety guarantees but are limited to specific system classes. In contrast, policy adaptation based on reinforcement learning (RL) offers versatility and generalizability but presents safety and robustness challenges. We propose SafeDPA, a novel RL and control framework that simultaneously tackles the problems of policy adaptation and safe reinforcement learning. SafeDPA jointly learns adaptive policy and dynamics models in simulation, predicts environment configurations, and fine-tunes dynamics models with few-shot real-world data. A safety filter based on the Control Barrier Function (CBF) on top of the RL policy is introduced to ensure safety during real-world deployment. We provide theoretical safety guarantees of SafeDPA and show the robustness of SafeDPA against learning errors and extra perturbations. Comprehensive experiments on (1) classic control problems (Inverted Pendulum), (2) simulation benchmarks (Safety Gym), and (3) a real-world agile robotics platform (RC Car) demonstrate great superiority of SafeDPA in both safety and task performance, over state-of-the-art baselines. Particularly, SafeDPA demonstrates notable generalizability, achieving a 300% increase in safety rate compared to the baselines, under unseen disturbances in real-world experiments.
Read more4/30/2024