Safety Alignment in NLP Tasks: Weakly Aligned Summarization as an In-Context Attack

0
✨
Sign in to get full access
Overview
- The paper explores the alignment between the safety of Large Language Models (LLMs) and the usefulness of mainstream Natural Language Processing (NLP) tasks.
- Researchers examined how well various NLP tasks, such as summarization, translation, and question-answering, are aligned with safety considerations when using LLMs.
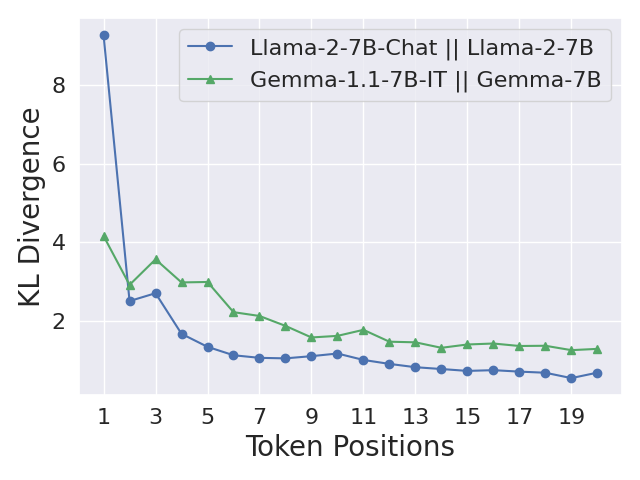
- The study found significant disparities in safety alignment, with some tasks (like summarization) allowing LLMs to effectively process malicious content, while others (like translation) often refusing to do so.
- This discrepancy highlights a vulnerability where attacks on less safety-aligned tasks could compromise the integrity of more traditionally robust tasks.
- The concurrent use of multiple NLP tasks with weaker safety alignment increases the risk of LLMs inadvertently processing harmful content.
- The paper demonstrates these vulnerabilities in several safety-aligned LLMs, including Llama2 models, Gemini and GPT-4, indicating an urgent need to strengthen safety alignments across a broad spectrum of NLP tasks.
Plain English Explanation
The researchers wanted to understand how well the common tasks that language models are used for, like summarizing text or answering questions, match up with the goal of keeping these models safe and not allowing them to do harmful things. They looked at what happens when you try to get language models to work with documents that contain malicious or dangerous content.
The study found that language models can sometimes summarize these malicious documents effectively, but they may refuse to translate them. This mismatch is a problem because it means that attackers could potentially exploit the tasks that have weaker safety protections, like summarization, to get the language model to engage with harmful content. And if you use multiple less-safe tasks together, the risk of the language model processing dangerous information goes up even more.
The researchers demonstrated these vulnerabilities in several state-of-the-art language models, including Llama2, Gemini, and GPT-4. This shows that there is an urgent need to improve the safety alignment across a wide range of language model tasks, not just the most obvious or high-risk ones.
Technical Explanation
The paper examines the alignment between the usefulness and safety of Large Language Models (LLMs) across mainstream Natural Language Processing (NLP) tasks. Researchers obtained safety-sensitive documents through adversarial attacks and evaluated how well various NLP tasks, such as summarization, translation, and question-answering (QA), are aligned with safety considerations.
The study found significant disparities in safety alignment across different tasks. For instance, LLMs could effectively summarize malicious long documents but often refused to translate them. This discrepancy highlights a vulnerability where attacks exploiting tasks with weaker safety alignment, like summarization, could potentially compromise the integrity of traditionally more robust tasks, such as translation and QA.
Furthermore, the researchers demonstrated that the concurrent use of multiple NLP tasks with lesser safety alignment increases the risk of LLMs inadvertently processing harmful content. These vulnerabilities were observed in several safety-aligned LLMs, including Llama2 models, Gemini, and GPT-4, indicating an urgent need to strengthen safety alignments across a broad spectrum of NLP tasks.
Critical Analysis
The paper raises important concerns about the safety implications of mainstream NLP tasks, particularly in the context of adversarial attacks. While the researchers demonstrate these vulnerabilities in several state-of-the-art language models, it's worth noting that the specific models and techniques used in the study may have evolved or been updated since the paper was published.
Additionally, the paper does not provide a comprehensive solution or framework for addressing these safety alignment issues. It primarily highlights the problem and calls for a broader effort to strengthen safety alignments across NLP tasks. Further research may be needed to develop more robust and comprehensive approaches to realign safety and usefulness in large language models or pioneering AI safety through smaller language models.
It's also essential to consider potential trade-offs and practical constraints when implementing safety-focused measures. Attempts to robustify safety-aligned language models could, for example, impact the models' performance or usability in certain applications. Striking the right balance between safety and utility remains a significant challenge in the development of large language models.
Conclusion
This study highlights a critical issue in the field of large language models: the need to ensure that the usefulness of mainstream NLP tasks is adequately aligned with safety considerations. The findings reveal significant disparities in safety alignment, where attacks on less safety-aligned tasks could compromise the integrity of more traditionally robust tasks.
The paper's insights underscore the urgency of strengthening safety alignments across a broad spectrum of NLP tasks, as the concurrent use of multiple less-safe tasks can increase the risk of language models inadvertently processing harmful content. The vulnerabilities demonstrated in models like Llama2, Gemini, and GPT-4 emphasize the importance of ongoing research and development to address these challenges.
As the adoption of large language models continues to grow, ensuring their safe and responsible use becomes increasingly crucial. This study serves as a valuable contribution to the ongoing efforts to balance the usefulness and safety of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
0
Safety Alignment in NLP Tasks: Weakly Aligned Summarization as an In-Context Attack
Yu Fu, Yufei Li, Wen Xiao, Cong Liu, Yue Dong
Recent developments in balancing the usefulness and safety of Large Language Models (LLMs) have raised a critical question: Are mainstream NLP tasks adequately aligned with safety consideration? Our study, focusing on safety-sensitive documents obtained through adversarial attacks, reveals significant disparities in the safety alignment of various NLP tasks. For instance, LLMs can effectively summarize malicious long documents but often refuse to translate them. This discrepancy highlights a previously unidentified vulnerability: attacks exploiting tasks with weaker safety alignment, like summarization, can potentially compromise the integrity of tasks traditionally deemed more robust, such as translation and question-answering (QA). Moreover, the concurrent use of multiple NLP tasks with lesser safety alignment increases the risk of LLMs inadvertently processing harmful content. We demonstrate these vulnerabilities in various safety-aligned LLMs, particularly Llama2 models, Gemini and GPT-4, indicating an urgent need for strengthening safety alignments across a broad spectrum of NLP tasks.
Read more6/10/2024
0
Safety Alignment Should Be Made More Than Just a Few Tokens Deep
Xiangyu Qi, Ashwinee Panda, Kaifeng Lyu, Xiao Ma, Subhrajit Roy, Ahmad Beirami, Prateek Mittal, Peter Henderson
The safety alignment of current Large Language Models (LLMs) is vulnerable. Relatively simple attacks, or even benign fine-tuning, can jailbreak aligned models. We argue that many of these vulnerabilities are related to a shared underlying issue: safety alignment can take shortcuts, wherein the alignment adapts a model's generative distribution primarily over only its very first few output tokens. We refer to this issue as shallow safety alignment. In this paper, we present case studies to explain why shallow safety alignment can exist and provide evidence that current aligned LLMs are subject to this issue. We also show how these findings help explain multiple recently discovered vulnerabilities in LLMs, including the susceptibility to adversarial suffix attacks, prefilling attacks, decoding parameter attacks, and fine-tuning attacks. Importantly, we discuss how this consolidated notion of shallow safety alignment sheds light on promising research directions for mitigating these vulnerabilities. For instance, we show that deepening the safety alignment beyond just the first few tokens can often meaningfully improve robustness against some common exploits. Finally, we design a regularized finetuning objective that makes the safety alignment more persistent against fine-tuning attacks by constraining updates on initial tokens. Overall, we advocate that future safety alignment should be made more than just a few tokens deep.
Read more6/11/2024

0
Cross-Task Defense: Instruction-Tuning LLMs for Content Safety
Yu Fu, Wen Xiao, Jia Chen, Jiachen Li, Evangelos Papalexakis, Aichi Chien, Yue Dong
Recent studies reveal that Large Language Models (LLMs) face challenges in balancing safety with utility, particularly when processing long texts for NLP tasks like summarization and translation. Despite defenses against malicious short questions, the ability of LLMs to safely handle dangerous long content, such as manuals teaching illicit activities, remains unclear. Our work aims to develop robust defenses for LLMs in processing malicious documents alongside benign NLP task queries. We introduce a defense dataset comprised of safety-related examples and propose single-task and mixed-task losses for instruction tuning. Our empirical results demonstrate that LLMs can significantly enhance their capacity to safely manage dangerous content with appropriate instruction tuning. Additionally, strengthening the defenses of tasks most susceptible to misuse is effective in protecting LLMs against processing harmful information. We also observe that trade-offs between utility and safety exist in defense strategies, where Llama2, utilizing our proposed approach, displays a significantly better balance compared to Llama1.
Read more5/27/2024

0
Multilingual Blending: LLM Safety Alignment Evaluation with Language Mixture
Jiayang Song, Yuheng Huang, Zhehua Zhou, Lei Ma
As safety remains a crucial concern throughout the development lifecycle of Large Language Models (LLMs), researchers and industrial practitioners have increasingly focused on safeguarding and aligning LLM behaviors with human preferences and ethical standards. LLMs, trained on extensive multilingual corpora, exhibit powerful generalization abilities across diverse languages and domains. However, current safety alignment practices predominantly focus on single-language scenarios, which leaves their effectiveness in complex multilingual contexts, especially for those complex mixed-language formats, largely unexplored. In this study, we introduce Multilingual Blending, a mixed-language query-response scheme designed to evaluate the safety alignment of various state-of-the-art LLMs (e.g., GPT-4o, GPT-3.5, Llama3) under sophisticated, multilingual conditions. We further investigate language patterns such as language availability, morphology, and language family that could impact the effectiveness of Multilingual Blending in compromising the safeguards of LLMs. Our experimental results show that, without meticulously crafted prompt templates, Multilingual Blending significantly amplifies the detriment of malicious queries, leading to dramatically increased bypass rates in LLM safety alignment (67.23% on GPT-3.5 and 40.34% on GPT-4o), far exceeding those of single-language baselines. Moreover, the performance of Multilingual Blending varies notably based on intrinsic linguistic properties, with languages of different morphology and from diverse families being more prone to evading safety alignments. These findings underscore the necessity of evaluating LLMs and developing corresponding safety alignment strategies in a complex, multilingual context to align with their superior cross-language generalization capabilities.
Read more7/11/2024