Safety through Permissibility: Shield Construction for Fast and Safe Reinforcement Learning

0

Sign in to get full access
Overview
- This paper presents a novel approach called "shield construction" for fast and safe reinforcement learning in black-box environments.
- The proposed method aims to enable rapid learning while ensuring safety by restricting the agent's actions to a "safe" subset defined by a permissibility function.
- The authors demonstrate the effectiveness of their approach through experiments in various environments, including classical control tasks and safety-critical robotics applications.
Plain English Explanation
The paper discusses a new technique called "shield construction" that helps artificial intelligence (AI) agents learn quickly and safely in complex, unknown environments. The key idea is to have the AI agent follow a set of rules or "permissions" that define what actions are safe to take. This "shield" of permissions allows the agent to explore the environment and learn rapidly, while ensuring it doesn't take actions that could be dangerous or harmful.
The researchers tested their approach in a variety of simulated environments, including classic control problems like balancing a pole and safety-critical robotics tasks. The results showed that the shield construction method enabled the AI agents to learn faster than traditional reinforcement learning techniques, while also keeping the agents within the bounds of safe behavior.
This is an important advancement in the field of safe reinforcement learning, which aims to develop AI systems that can learn and operate in the real world without posing risks to humans or the environment. By combining rapid learning with strong safety guarantees, the shield construction approach could pave the way for more capable and trustworthy AI assistants in the future.
Technical Explanation
The paper introduces a novel technique called "shield construction" for safe reinforcement learning in black-box environments. The key idea is to define a "permissibility function" that specifies a set of "safe" actions the agent is allowed to take at each state. This permissibility function acts as a "shield" that restricts the agent's exploration to the safe subset of the action space, enabling rapid learning while ensuring safety.
The authors formalize the shield construction problem as a multi-objective optimization task, where the objective is to maximize the agent's performance while minimizing the deviation from the permissibility function. They propose an efficient algorithm to solve this optimization problem and construct the shield in an online fashion as the agent interacts with the environment.
The researchers evaluate their approach in a variety of environments, including classical control tasks (e.g., pole balancing) and safety-critical robotics applications. The results demonstrate that the shield construction method enables faster learning compared to traditional reinforcement learning techniques, while also ensuring the agent's actions remain within the safe subset defined by the permissibility function.
Critical Analysis
The paper presents a promising approach for safe reinforcement learning in black-box environments, with a strong focus on balancing learning performance and safety guarantees. The authors' formulation of the shield construction problem as a multi-objective optimization task is a clever and principled way to approach this challenge.
However, the paper does not address several important limitations and potential issues. For example, the reliance on a well-defined permissibility function may be a significant challenge in real-world applications, where the safe action space may be complex or even difficult to specify a priori. Approaches that learn the safety constraints directly from data could be a fruitful direction for further research.
Additionally, the paper does not provide a comprehensive survey of constraint formulations for safe reinforcement learning, which could offer valuable insights into alternative ways of ensuring safety during the learning process.
Overall, the shield construction approach is a promising step towards more capable and trustworthy AI systems, but further research is needed to address the limitations and expand the applicability of this technique to more complex, real-world scenarios.
Conclusion
This paper presents a novel "shield construction" method for fast and safe reinforcement learning in black-box environments. The key idea is to define a permissibility function that restricts the agent's actions to a safe subset, enabling rapid learning while ensuring safety. The authors demonstrate the effectiveness of their approach through experiments in various environments, including classical control tasks and safety-critical robotics applications.
The shield construction technique is a promising step towards more capable and trustworthy AI systems, as it combines the benefits of fast learning with strong safety guarantees. However, the reliance on a well-defined permissibility function and the lack of a comprehensive survey of alternative constraint formulations present potential limitations that warrant further research. Continuing to advance the field of safe reinforcement learning will be crucial for the responsible development and deployment of AI in real-world, safety-critical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Safety through Permissibility: Shield Construction for Fast and Safe Reinforcement Learning
Alexander Politowicz, Sahisnu Mazumder, Bing Liu
Designing Reinforcement Learning (RL) solutions for real-life problems remains a significant challenge. A major area of concern is safety. Shielding is a popular technique to enforce safety in RL by turning user-defined safety specifications into safe agent behavior. However, these methods either suffer from extreme learning delays, demand extensive human effort in designing models and safe domains in the problem, or require pre-computation. In this paper, we propose a new permissibility-based framework to deal with safety and shield construction. Permissibility was originally designed for eliminating (non-permissible) actions that will not lead to an optimal solution to improve RL training efficiency. This paper shows that safety can be naturally incorporated into this framework, i.e. extending permissibility to include safety, and thereby we can achieve both safety and improved efficiency. Experimental evaluation using three standard RL applications shows the effectiveness of the approach.
Read more5/31/2024
🏅
0
Safe Reinforcement Learning in Black-Box Environments via Adaptive Shielding
Daniel Bethell, Simos Gerasimou, Radu Calinescu, Calum Imrie
Empowering safe exploration of reinforcement learning (RL) agents during training is a critical impediment towards deploying RL agents in many real-world scenarios. Training RL agents in unknown, black-box environments poses an even greater safety risk when prior knowledge of the domain/task is unavailable. We introduce ADVICE (Adaptive Shielding with a Contrastive Autoencoder), a novel post-shielding technique that distinguishes safe and unsafe features of state-action pairs during training, thus protecting the RL agent from executing actions that yield potentially hazardous outcomes. Our comprehensive experimental evaluation against state-of-the-art safe RL exploration techniques demonstrates how ADVICE can significantly reduce safety violations during training while maintaining a competitive outcome reward.
Read more5/29/2024

0
Verification-Guided Shielding for Deep Reinforcement Learning
Davide Corsi, Guy Amir, Andoni Rodriguez, Cesar Sanchez, Guy Katz, Roy Fox
In recent years, Deep Reinforcement Learning (DRL) has emerged as an effective approach to solving real-world tasks. However, despite their successes, DRL-based policies suffer from poor reliability, which limits their deployment in safety-critical domains. Various methods have been put forth to address this issue by providing formal safety guarantees. Two main approaches include shielding and verification. While shielding ensures the safe behavior of the policy by employing an external online component (i.e., a ``shield'') that overrides potentially dangerous actions, this approach has a significant computational cost as the shield must be invoked at runtime to validate every decision. On the other hand, verification is an offline process that can identify policies that are unsafe, prior to their deployment, yet, without providing alternative actions when such a policy is deemed unsafe. In this work, we present verification-guided shielding -- a novel approach that bridges the DRL reliability gap by integrating these two methods. Our approach combines both formal and probabilistic verification tools to partition the input domain into safe and unsafe regions. In addition, we employ clustering and symbolic representation procedures that compress the unsafe regions into a compact representation. This, in turn, allows to temporarily activate the shield solely in (potentially) unsafe regions, in an efficient manner. Our novel approach allows to significantly reduce runtime overhead while still preserving formal safety guarantees. We extensively evaluate our approach on two benchmarks from the robotic navigation domain, as well as provide an in-depth analysis of its scalability and completeness.
Read more6/24/2024
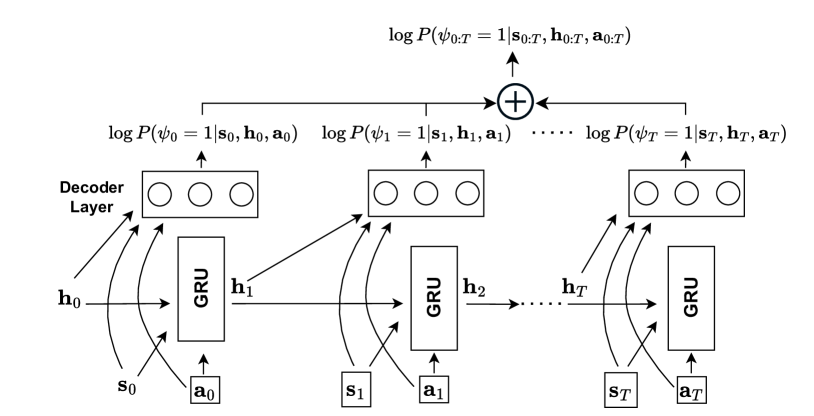
0
Safe Reinforcement Learning with Learned Non-Markovian Safety Constraints
Siow Meng Low, Akshat Kumar
In safe Reinforcement Learning (RL), safety cost is typically defined as a function dependent on the immediate state and actions. In practice, safety constraints can often be non-Markovian due to the insufficient fidelity of state representation, and safety cost may not be known. We therefore address a general setting where safety labels (e.g., safe or unsafe) are associated with state-action trajectories. Our key contributions are: first, we design a safety model that specifically performs credit assignment to assess contributions of partial state-action trajectories on safety. This safety model is trained using a labeled safety dataset. Second, using RL-as-inference strategy we derive an effective algorithm for optimizing a safe policy using the learned safety model. Finally, we devise a method to dynamically adapt the tradeoff coefficient between reward maximization and safety compliance. We rewrite the constrained optimization problem into its dual problem and derive a gradient-based method to dynamically adjust the tradeoff coefficient during training. Our empirical results demonstrate that this approach is highly scalable and able to satisfy sophisticated non-Markovian safety constraints.
Read more5/7/2024