SALSA: Swift Adaptive Lightweight Self-Attention for Enhanced LiDAR Place Recognition

0

Sign in to get full access
Overview
- This paper introduces SALSA (Swift Adaptive Lightweight Self-Attention), a novel approach for enhanced LiDAR place recognition.
- SALSA utilizes a lightweight self-attention mechanism to efficiently capture long-range dependencies in LiDAR point cloud data.
- The proposed method aims to improve the performance of LiDAR-based place recognition tasks, which are crucial for applications like autonomous navigation and mapping.
Plain English Explanation
LiDAR (Light Detection and Ranging) is a technology used to create detailed 3D maps of the environment. It works by sending out laser pulses and measuring the time it takes for the light to bounce back, allowing the system to determine the distance to objects. This information is then used to construct a 3D point cloud representation of the surroundings.
One important application of LiDAR is place recognition, which involves identifying and matching locations based on the LiDAR data. This is essential for autonomous vehicles and robots to navigate and understand their environment. However, traditional place recognition methods can struggle with capturing the long-range dependencies and contextual information in the complex LiDAR point clouds.
The SALSA approach proposed in this paper aims to address this challenge by using a lightweight self-attention mechanism. Self-attention allows the model to focus on and emphasize the most relevant features in the data, enabling it to better recognize and match places based on the LiDAR point clouds. This lightweight approach is designed to be computationally efficient, making it suitable for real-time applications like autonomous navigation and visual place recognition.
Technical Explanation
The key components of the SALSA architecture are:
-
Lightweight Self-Attention Module: SALSA employs a novel self-attention mechanism that is computationally efficient and can effectively capture long-range dependencies in the LiDAR point cloud data. This is achieved by using a lightweight attention formulation and a spatial pyramid pooling approach to aggregate multi-scale features.
-
Adaptive Fusion: SALSA adaptively fuses the output of the self-attention module with the original point cloud features, allowing the model to selectively emphasize the most relevant information for place recognition.
-
Efficient Encoding: The SALSA network uses a compact encoding strategy to generate a concise and discriminative representation of the LiDAR point cloud, enabling efficient place matching and retrieval.
The authors evaluate the performance of SALSA on various standard LiDAR place recognition benchmarks, including KITTI and Oxford RobotCar. The results demonstrate that SALSA outperforms state-of-the-art LiDAR place recognition methods in terms of accuracy and computational efficiency.
Critical Analysis
The authors acknowledge that the performance of SALSA may be influenced by the quality and diversity of the training data, as well as the specific characteristics of the LiDAR sensors and environments used in the experiments. Further research could explore the robustness of SALSA to different sensor modalities, environmental conditions, and real-world deployment scenarios.
Additionally, the paper does not provide a detailed analysis of the memory and latency requirements of the SALSA model, which are crucial for real-time applications. Investigating the scalability and resource efficiency of SALSA in more depth could help to better understand its practical limitations and potential use cases.
Conclusion
The SALSA approach presented in this paper demonstrates the potential of lightweight self-attention mechanisms for enhancing LiDAR-based place recognition. By efficiently capturing long-range dependencies in the point cloud data, SALSA can generate more discriminative place representations, leading to improved performance on standard benchmarks. This research contributes to the ongoing efforts to develop robust and efficient perception systems for autonomous systems, which could have significant implications for applications such as self-driving cars, robot navigation, and mapping.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SALSA: Swift Adaptive Lightweight Self-Attention for Enhanced LiDAR Place Recognition
Raktim Gautam Goswami, Naman Patel, Prashanth Krishnamurthy, Farshad Khorrami
Large-scale LiDAR mappings and localization leverage place recognition techniques to mitigate odometry drifts, ensuring accurate mapping. These techniques utilize scene representations from LiDAR point clouds to identify previously visited sites within a database. Local descriptors, assigned to each point within a point cloud, are aggregated to form a scene representation for the point cloud. These descriptors are also used to re-rank the retrieved point clouds based on geometric fitness scores. We propose SALSA, a novel, lightweight, and efficient framework for LiDAR place recognition. It consists of a Sphereformer backbone that uses radial window attention to enable information aggregation for sparse distant points, an adaptive self-attention layer to pool local descriptors into tokens, and a multi-layer-perceptron Mixer layer for aggregating the tokens to generate a scene descriptor. The proposed framework outperforms existing methods on various LiDAR place recognition datasets in terms of both retrieval and metric localization while operating in real-time.
Read more7/31/2024
🔄
0
Attention-Guided Lidar Segmentation and Odometry Using Image-to-Point Cloud Saliency Transfer
Guanqun Ding, Nevrez Imamoglu, Ali Caglayan, Masahiro Murakawa, Ryosuke Nakamura
LiDAR odometry estimation and 3D semantic segmentation are crucial for autonomous driving, which has achieved remarkable advances recently. However, these tasks are challenging due to the imbalance of points in different semantic categories for 3D semantic segmentation and the influence of dynamic objects for LiDAR odometry estimation, which increases the importance of using representative/salient landmarks as reference points for robust feature learning. To address these challenges, we propose a saliency-guided approach that leverages attention information to improve the performance of LiDAR odometry estimation and semantic segmentation models. Unlike in the image domain, only a few studies have addressed point cloud saliency information due to the lack of annotated training data. To alleviate this, we first present a universal framework to transfer saliency distribution knowledge from color images to point clouds, and use this to construct a pseudo-saliency dataset (i.e. FordSaliency) for point clouds. Then, we adopt point cloud-based backbones to learn saliency distribution from pseudo-saliency labels, which is followed by our proposed SalLiDAR module. SalLiDAR is a saliency-guided 3D semantic segmentation model that integrates saliency information to improve segmentation performance. Finally, we introduce SalLONet, a self-supervised saliency-guided LiDAR odometry network that uses the semantic and saliency predictions of SalLiDAR to achieve better odometry estimation. Our extensive experiments on benchmark datasets demonstrate that the proposed SalLiDAR and SalLONet models achieve state-of-the-art performance against existing methods, highlighting the effectiveness of image-to-LiDAR saliency knowledge transfer. Source code will be available at https://github.com/nevrez/SalLONet.
Read more6/18/2024
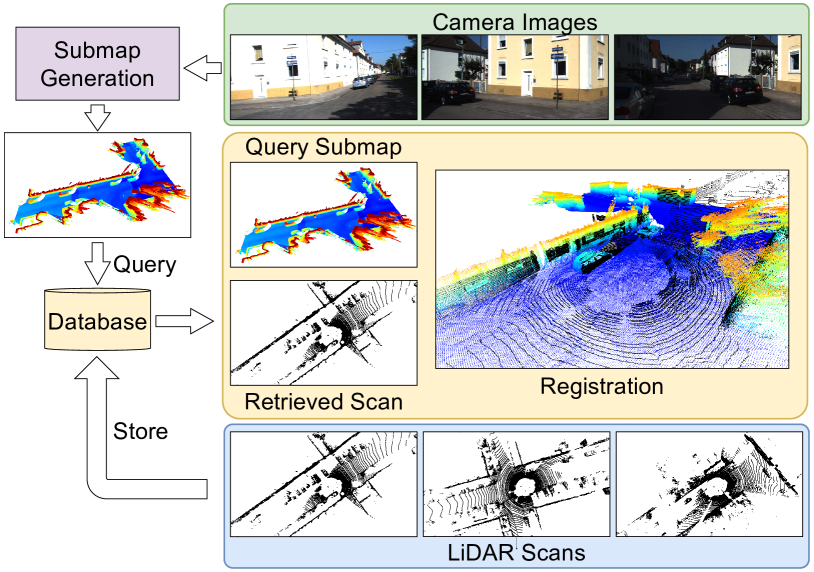
0
New!SOLVR: Submap Oriented LiDAR-Visual Re-Localisation
Joshua Knights, Sebasti'an Barbas Laina, Peyman Moghadam, Stefan Leutenegger
This paper proposes SOLVR, a unified pipeline for learning based LiDAR-Visual re-localisation which performs place recognition and 6-DoF registration across sensor modalities. We propose a strategy to align the input sensor modalities by leveraging stereo image streams to produce metric depth predictions with pose information, followed by fusing multiple scene views from a local window using a probabilistic occupancy framework to expand the limited field-of-view of the camera. Additionally, SOLVR adopts a flexible definition of what constitutes positive examples for different training losses, allowing us to simultaneously optimise place recognition and registration performance. Furthermore, we replace RANSAC with a registration function that weights a simple least-squares fitting with the estimated inlier likelihood of sparse keypoint correspondences, improving performance in scenarios with a low inlier ratio between the query and retrieved place. Our experiments on the KITTI and KITTI360 datasets show that SOLVR achieves state-of-the-art performance for LiDAR-Visual place recognition and registration, particularly improving registration accuracy over larger distances between the query and retrieved place.
Read more9/17/2024

0
Matched Filtering based LiDAR Place Recognition for Urban and Natural Environments
Therese Joseph, Tobias Fischer, Michael Milford
Place recognition is an important task within autonomous navigation, involving the re-identification of previously visited locations from an initial traverse. Unlike visual place recognition (VPR), LiDAR place recognition (LPR) is tolerant to changes in lighting, seasons, and textures, leading to high performance on benchmark datasets from structured urban environments. However, there is a growing need for methods that can operate in diverse environments with high performance and minimal training. In this paper, we propose a handcrafted matching strategy that performs roto-translation invariant place recognition and relative pose estimation for both urban and unstructured natural environments. Our approach constructs Birds Eye View (BEV) global descriptors and employs a two-stage search using matched filtering -- a signal processing technique for detecting known signals amidst noise. Extensive testing on the NCLT, Oxford Radar, and WildPlaces datasets consistently demonstrates state-of-the-art (SoTA) performance across place recognition and relative pose estimation metrics, with up to 15% higher recall than previous SoTA.
Read more9/9/2024