Scaling Laws For Dense Retrieval

0
Sign in to get full access
Overview
- This paper explores the scaling laws that govern the performance of dense retrieval models, which are a type of neural network used for information retrieval tasks.
- The authors analyze how the accuracy of dense retrieval models scales as the size of the model and training dataset are increased.
- The findings provide insights into the fundamental properties of dense retrieval systems and how they can be optimized for different applications.
Plain English Explanation
The paper focuses on dense retrieval models, which are a type of artificial intelligence system used to quickly find relevant information from large databases. These models are trained on huge amounts of data to learn patterns and relationships, allowing them to efficiently search through and retrieve information.
The researchers in this study looked at how the performance of these dense retrieval models changes as the models and the training datasets get larger. They found that there are scaling laws - mathematical rules that describe how the accuracy of the models improves as the models and datasets grow in size.
Understanding these scaling laws is important because it helps us predict the potential of dense retrieval systems and how to design them most effectively for different use cases. For example, the findings could inform decisions around how large to make the models and datasets for a particular application, in order to achieve the desired level of performance.
Overall, this research provides valuable insights into the fundamental properties of dense retrieval systems, which can guide the development of increasingly powerful AI-powered search and information retrieval capabilities. The insights build on previous work exploring scaling laws in language models and computer vision.
Technical Explanation
The paper begins by providing background on dense retrieval, which is a technique that uses neural networks to map queries and documents into a shared vector space. This allows for efficient nearest-neighbor search to find the most relevant documents for a given query.
The key focus of the study is analyzing the scaling laws that govern the performance of these dense retrieval models. The authors investigate how the accuracy of the models, as measured by standard retrieval metrics like Recall@k, scales as a function of:
- The model size, i.e. the number of parameters in the neural network.
- The dataset size, i.e. the amount of training data used.
Through extensive experiments on large-scale datasets, the researchers find that the performance of dense retrieval models follows well-defined power-law scaling relationships. Specifically, they observe that:
- Model accuracy scales as a power-law function of model size, with an exponent around 0.2-0.3.
- Accuracy also scales as a power-law function of dataset size, with an exponent around 0.1-0.2.
These scaling laws are consistent with prior work on scaling laws in language models and computer vision, suggesting common underlying principles.
The authors also analyze the computational complexity of dense retrieval, finding that the inference time scales linearly with model size. This contrasts with sparse retrieval methods, whose complexity typically scales logarithmically.
Critical Analysis
The paper provides a rigorous empirical analysis of the scaling properties of dense retrieval models, which is an important contribution to our understanding of this class of AI systems.
However, the study is limited to a specific set of dense retrieval architectures and datasets. It would be valuable to see if the observed scaling laws hold true across a wider range of model architectures, training regimes, and application domains.
Additionally, the paper does not delve into the underlying reasons why dense retrieval models exhibit these particular scaling relationships. Further theoretical and conceptual work is needed to fully unravel the mystery of scaling laws in this context.
It would also be interesting to explore the implications of the linear computational complexity finding. While this property is advantageous compared to sparse retrieval methods, the authors do not discuss potential limitations or trade-offs that may arise as model and dataset sizes continue to grow at scale.
Overall, this research represents an important step forward in understanding the fundamental characteristics of dense retrieval systems. The insights can help guide the development of more powerful and efficient AI-powered search and information retrieval capabilities.
Conclusion
This paper presents a comprehensive study of the scaling laws that govern the performance of dense retrieval models. The key findings show that model accuracy scales as a power-law function of both model size and dataset size, with the exponents providing quantitative insights into these relationships.
The linear computational complexity of dense retrieval is also a noteworthy discovery, contrasting with the logarithmic scaling of traditional sparse retrieval methods. These insights can inform the design and optimization of dense retrieval systems for a wide range of applications, from web search to scientific literature curation.
Overall, this research contributes to our growing understanding of the fundamental properties of AI systems, building on previous work on scaling laws in language models and computer vision. By uncovering the scaling laws of dense retrieval, the authors pave the way for the development of increasingly powerful and efficient AI-powered information retrieval capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Scaling Laws For Dense Retrieval
Yan Fang, Jingtao Zhan, Qingyao Ai, Jiaxin Mao, Weihang Su, Jia Chen, Yiqun Liu
Scaling up neural models has yielded significant advancements in a wide array of tasks, particularly in language generation. Previous studies have found that the performance of neural models frequently adheres to predictable scaling laws, correlated with factors such as training set size and model size. This insight is invaluable, especially as large-scale experiments grow increasingly resource-intensive. Yet, such scaling law has not been fully explored in dense retrieval due to the discrete nature of retrieval metrics and complex relationships between training data and model sizes in retrieval tasks. In this study, we investigate whether the performance of dense retrieval models follows the scaling law as other neural models. We propose to use contrastive log-likelihood as the evaluation metric and conduct extensive experiments with dense retrieval models implemented with different numbers of parameters and trained with different amounts of annotated data. Results indicate that, under our settings, the performance of dense retrieval models follows a precise power-law scaling related to the model size and the number of annotations. Additionally, we examine scaling with prevalent data augmentation methods to assess the impact of annotation quality, and apply the scaling law to find the best resource allocation strategy under a budget constraint. We believe that these insights will significantly contribute to understanding the scaling effect of dense retrieval models and offer meaningful guidance for future research endeavors.
Read more7/16/2024
0
Unraveling the Mystery of Scaling Laws: Part I
Hui Su, Zhi Tian, Xiaoyu Shen, Xunliang Cai
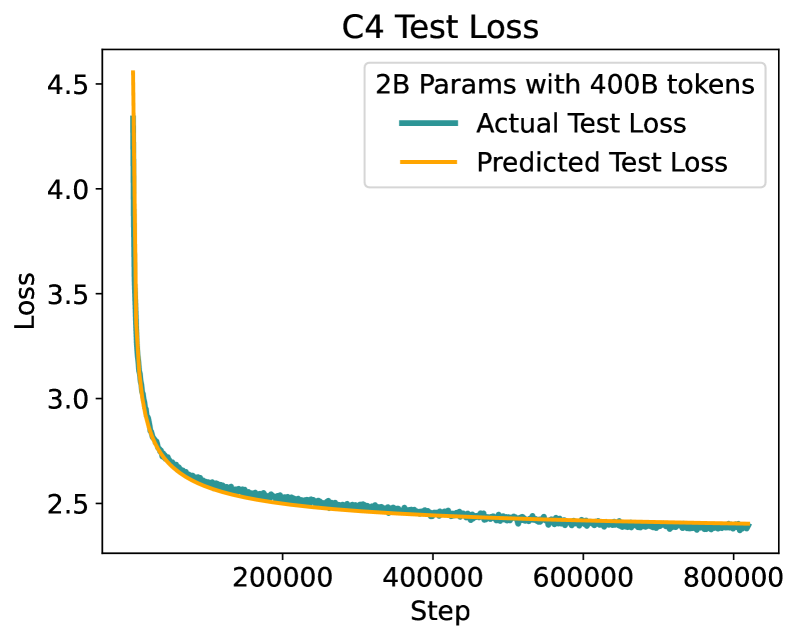
Scaling law principles indicate a power-law correlation between loss and variables such as model size, dataset size, and computational resources utilized during training. These principles play a vital role in optimizing various aspects of model pre-training, ultimately contributing to the success of large language models such as GPT-4, Llama and Gemini. However, the original scaling law paper by OpenAI did not disclose the complete details necessary to derive the precise scaling law formulas, and their conclusions are only based on models containing up to 1.5 billion parameters. Though some subsequent works attempt to unveil these details and scale to larger models, they often neglect the training dependency of important factors such as the learning rate, context length and batch size, leading to their failure to establish a reliable formula for predicting the test loss trajectory. In this technical report, we confirm that the scaling law formulations proposed in the original OpenAI paper remain valid when scaling the model size up to 33 billion, but the constant coefficients in these formulas vary significantly with the experiment setup. We meticulously identify influential factors and provide transparent, step-by-step instructions to estimate all constant terms in scaling-law formulas by training on models with only 1M~60M parameters. Using these estimated formulas, we showcase the capability to accurately predict various attributes for models with up to 33B parameters before their training, including (1) the minimum possible test loss; (2) the minimum required training steps and processed tokens to achieve a specific loss; (3) the critical batch size with an optimal time/computation trade-off at any loss value; and (4) the complete test loss trajectory with arbitrary batch size.
Read more4/8/2024
🤿
0
Reproducible scaling laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, Jenia Jitsev
Scaling up neural networks has led to remarkable performance across a wide range of tasks. Moreover, performance often follows reliable scaling laws as a function of training set size, model size, and compute, which offers valuable guidance as large-scale experiments are becoming increasingly expensive. However, previous work on scaling laws has primarily used private data & models or focused on uni-modal language or vision learning. To address these limitations, we investigate scaling laws for contrastive language-image pre-training (CLIP) with the public LAION dataset and the open-source OpenCLIP repository. Our large-scale experiments involve models trained on up to two billion image-text pairs and identify power law scaling for multiple downstream tasks including zero-shot classification, retrieval, linear probing, and end-to-end fine-tuning. We find that the training distribution plays a key role in scaling laws as the OpenAI and OpenCLIP models exhibit different scaling behavior despite identical model architectures and similar training recipes. We open-source our evaluation workflow and all models, including the largest public CLIP models, to ensure reproducibility and make scaling laws research more accessible. Source code and instructions to reproduce this study will be available at https://github.com/LAION-AI/scaling-laws-openclip
Read more7/16/2024

0
Scaling Retrieval-Based Language Models with a Trillion-Token Datastore
Rulin Shao, Jacqueline He, Akari Asai, Weijia Shi, Tim Dettmers, Sewon Min, Luke Zettlemoyer, Pang Wei Koh
Scaling laws with respect to the amount of training data and the number of parameters allow us to predict the cost-benefit trade-offs of pretraining language models (LMs) in different configurations. In this paper, we consider another dimension of scaling: the amount of data available at inference time. Specifically, we find that increasing the size of the datastore used by a retrieval-based LM monotonically improves language modeling and several downstream tasks without obvious saturation, such that a smaller model augmented with a large datastore outperforms a larger LM-only model on knowledge-intensive tasks. By plotting compute-optimal scaling curves with varied datastore, model, and pretraining data sizes, we show that using larger datastores can significantly improve model performance for the same training compute budget. We carry out our study by constructing a 1.4 trillion-token datastore named MassiveDS, which is the largest and the most diverse open-sourced datastore for retrieval-based LMs to date, and designing an efficient pipeline for studying datastore scaling in a computationally accessible manner. Finally, we analyze the effect of improving the retriever, datastore quality filtering, and other design choices on our observed scaling trends. Overall, our results show that datastore size should be considered as an integral part of LM efficiency and performance trade-offs. To facilitate future research, we open-source our datastore and code at https://github.com/RulinShao/retrieval-scaling.
Read more7/19/2024