Reproducible scaling laws for contrastive language-image learning

0
🤿
Sign in to get full access
Overview
- Discusses scaling laws for contrastive language-image pre-training (CLIP) using the public LAION dataset and the open-source OpenCLIP repository
- Investigates power law scaling for multiple downstream tasks like zero-shot classification, retrieval, linear probing, and end-to-end fine-tuning
- Finds that the training distribution plays a key role in scaling laws, as the OpenAI and OpenCLIP models exhibit different scaling behavior despite similar architectures and training recipes
- Open-sources the evaluation workflow and all models, including the largest public CLIP models, to ensure reproducibility and make scaling laws research more accessible
Plain English Explanation
As neural networks have become larger and more powerful, researchers have noticed that their performance often follows predictable "scaling laws" - that is, their capabilities tend to improve in a consistent way as the model size, training data, and computational resources increase. This has provided valuable guidance for researchers and engineers who are building these large-scale AI systems, as running the experiments to test these scaling laws can be extremely expensive.
However, most of the previous work on scaling laws has used private datasets and models, or has focused only on language or vision tasks in isolation. This new paper aims to address those limitations by studying the scaling laws for a powerful AI model called CLIP that is trained on a large public dataset to perform both language and vision tasks.
The researchers trained CLIP models on up to 2 billion image-text pairs from the LAION dataset, and then evaluated how the models' performance scaled on a variety of downstream tasks, including zero-shot classification, retrieval, linear probing, and fine-tuning. They found that the models did indeed exhibit clear power law scaling relationships, meaning that the models' capabilities tended to improve in a predictable way as the training data and model size increased.
Interestingly, the researchers also found that the specific training dataset used played a big role in the scaling behavior - even when the model architectures were identical, the OpenAI and OpenCLIP models showed different scaling trends. This suggests that the content and structure of the training data can have a significant impact on how a large AI model's capabilities scale up.
To make this research more accessible, the researchers have open-sourced their evaluation workflow and all of the CLIP models they trained, including the largest public CLIP models to date. This will allow other researchers to build on their work and explore scaling laws in more depth.
Technical Explanation
The paper investigates scaling laws for contrastive language-image pre-training (CLIP) using the public LAION dataset and the open-source OpenCLIP repository. The researchers trained CLIP models on up to 2 billion image-text pairs and evaluated their performance on a range of downstream tasks, including zero-shot classification, retrieval, linear probing, and end-to-end fine-tuning.
Their experiments revealed clear power law scaling relationships, where the models' capabilities improved in a predictable way as the training data and model size increased. This aligns with previous findings on scaling laws for language models and scaling laws for dense retrieval.
Notably, the researchers found that the specific training distribution played a key role in the scaling behavior. Even when the OpenAI and OpenCLIP models had identical architectures and similar training recipes, they exhibited different scaling trends. This suggests that the content and structure of the training data can have a significant impact on how a model's capabilities scale up.
To ensure reproducibility and accessibility, the researchers have open-sourced their evaluation workflow and all of the CLIP models they trained, including the largest public CLIP models to date. This will allow other researchers to build on their work on unraveling the mysteries of scaling laws and explore these phenomena in more depth.
Critical Analysis
The paper provides valuable insights into the scaling behavior of large-scale contrastive language-image models, which is an important area of research as these models become increasingly prominent in AI applications. The open-sourcing of the evaluation workflow and models is a particularly commendable aspect, as it will enable other researchers to build on this work and verify the findings.
That said, the paper does not delve deeply into the potential limitations or caveats of the research. For example, it would be interesting to know more about the specific characteristics of the LAION dataset that may have influenced the scaling behavior, or how the results might differ with other large-scale datasets. Additionally, the paper does not explore the potential biases or ethical considerations that may arise from training such large-scale models on web-crawled data.
Furthermore, while the researchers have identified clear power law scaling relationships, the underlying reasons for these patterns are not fully explained. A more in-depth analysis of the factors driving the scaling behavior, such as the role of model architecture, optimization techniques, or pretraining strategies, could provide valuable insights for the field.
Overall, this paper represents an important contribution to the growing body of research on scaling laws in AI, and the open-source approach is a commendable step towards making this line of inquiry more accessible and reproducible. However, there are opportunities for future work to build on these findings and explore the implications and limitations of scaling laws in greater depth.
Conclusion
This paper investigates the scaling laws for contrastive language-image pre-training (CLIP) using the public LAION dataset and the open-source OpenCLIP repository. The researchers trained CLIP models on up to 2 billion image-text pairs and found clear power law scaling relationships for multiple downstream tasks, including zero-shot classification, retrieval, linear probing, and end-to-end fine-tuning.
Importantly, the researchers discovered that the training distribution plays a key role in the scaling behavior, as the OpenAI and OpenCLIP models exhibited different scaling trends despite having identical architectures and similar training recipes. This suggests that the content and structure of the training data can significantly impact how a model's capabilities scale up.
By open-sourcing their evaluation workflow and all of the CLIP models they trained, including the largest public CLIP models to date, the researchers have made this line of scaling laws research more accessible and reproducible. This will allow other researchers to build on their work and explore these phenomena in greater depth, potentially leading to a better understanding of the fundamental drivers of scaling in large-scale AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Reproducible scaling laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, Jenia Jitsev
Scaling up neural networks has led to remarkable performance across a wide range of tasks. Moreover, performance often follows reliable scaling laws as a function of training set size, model size, and compute, which offers valuable guidance as large-scale experiments are becoming increasingly expensive. However, previous work on scaling laws has primarily used private data & models or focused on uni-modal language or vision learning. To address these limitations, we investigate scaling laws for contrastive language-image pre-training (CLIP) with the public LAION dataset and the open-source OpenCLIP repository. Our large-scale experiments involve models trained on up to two billion image-text pairs and identify power law scaling for multiple downstream tasks including zero-shot classification, retrieval, linear probing, and end-to-end fine-tuning. We find that the training distribution plays a key role in scaling laws as the OpenAI and OpenCLIP models exhibit different scaling behavior despite identical model architectures and similar training recipes. We open-source our evaluation workflow and all models, including the largest public CLIP models, to ensure reproducibility and make scaling laws research more accessible. Source code and instructions to reproduce this study will be available at https://github.com/LAION-AI/scaling-laws-openclip
Read more7/16/2024
1
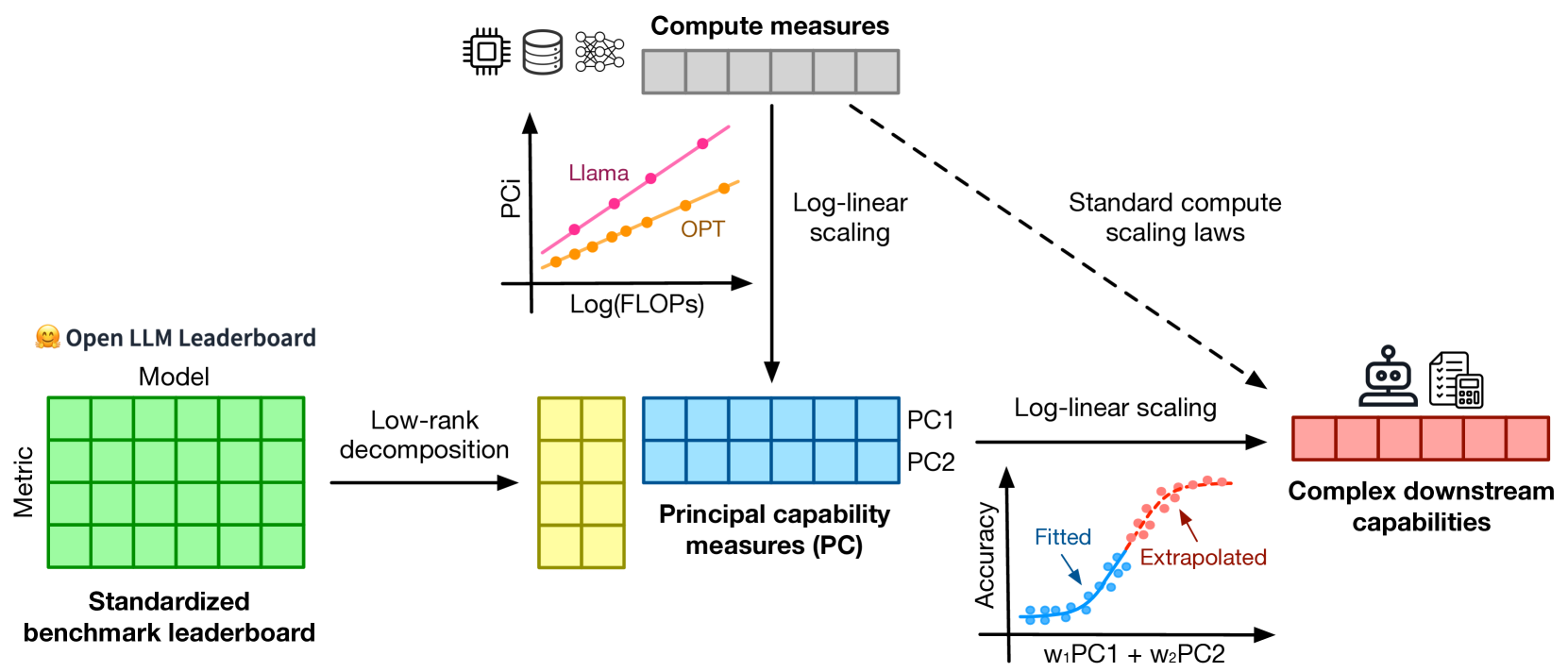
Observational Scaling Laws and the Predictability of Language Model Performance
Yangjun Ruan, Chris J. Maddison, Tatsunori Hashimoto
Understanding how language model performance varies with scale is critical to benchmark and algorithm development. Scaling laws are one approach to building this understanding, but the requirement of training models across many different scales has limited their use. We propose an alternative, observational approach that bypasses model training and instead builds scaling laws from ~80 publically available models. Building a single scaling law from multiple model families is challenging due to large variations in their training compute efficiencies and capabilities. However, we show that these variations are consistent with a simple, generalized scaling law where language model performance is a function of a low-dimensional capability space, and model families only vary in their efficiency in converting training compute to capabilities. Using this approach, we show the surprising predictability of complex scaling phenomena: we show that several emergent phenomena follow a smooth, sigmoidal behavior and are predictable from small models; we show that the agent performance of models such as GPT-4 can be precisely predicted from simpler non-agentic benchmarks; and we show how to predict the impact of post-training interventions like Chain-of-Thought and Self-Consistency as language model capabilities continue to improve.
Read more5/20/2024
0
Unraveling the Mystery of Scaling Laws: Part I
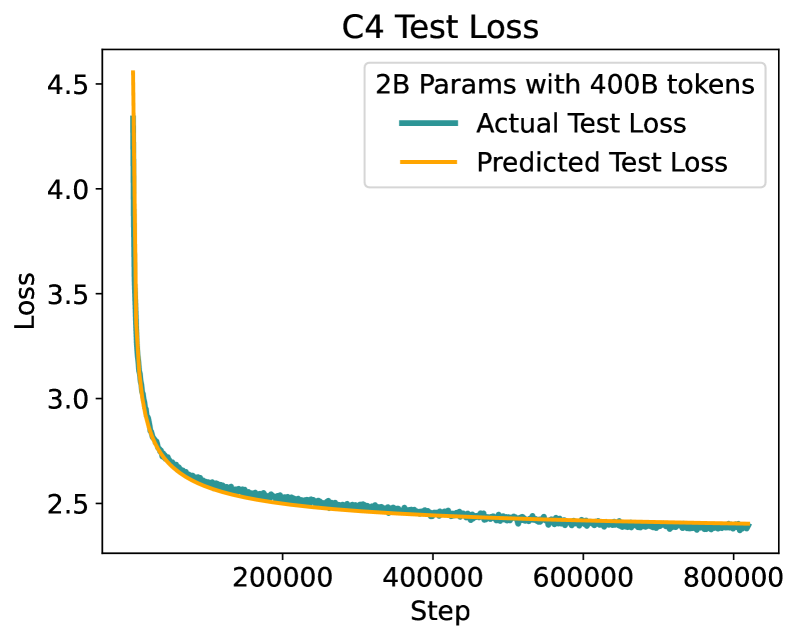
Hui Su, Zhi Tian, Xiaoyu Shen, Xunliang Cai
Scaling law principles indicate a power-law correlation between loss and variables such as model size, dataset size, and computational resources utilized during training. These principles play a vital role in optimizing various aspects of model pre-training, ultimately contributing to the success of large language models such as GPT-4, Llama and Gemini. However, the original scaling law paper by OpenAI did not disclose the complete details necessary to derive the precise scaling law formulas, and their conclusions are only based on models containing up to 1.5 billion parameters. Though some subsequent works attempt to unveil these details and scale to larger models, they often neglect the training dependency of important factors such as the learning rate, context length and batch size, leading to their failure to establish a reliable formula for predicting the test loss trajectory. In this technical report, we confirm that the scaling law formulations proposed in the original OpenAI paper remain valid when scaling the model size up to 33 billion, but the constant coefficients in these formulas vary significantly with the experiment setup. We meticulously identify influential factors and provide transparent, step-by-step instructions to estimate all constant terms in scaling-law formulas by training on models with only 1M~60M parameters. Using these estimated formulas, we showcase the capability to accurately predict various attributes for models with up to 33B parameters before their training, including (1) the minimum possible test loss; (2) the minimum required training steps and processed tokens to achieve a specific loss; (3) the critical batch size with an optimal time/computation trade-off at any loss value; and (4) the complete test loss trajectory with arbitrary batch size.
Read more4/8/2024

0
Language models scale reliably with over-training and on downstream tasks
Samir Yitzhak Gadre, Georgios Smyrnis, Vaishaal Shankar, Suchin Gururangan, Mitchell Wortsman, Rulin Shao, Jean Mercat, Alex Fang, Jeffrey Li, Sedrick Keh, Rui Xin, Marianna Nezhurina, Igor Vasiljevic, Jenia Jitsev, Luca Soldaini, Alexandros G. Dimakis, Gabriel Ilharco, Pang Wei Koh, Shuran Song, Thomas Kollar, Yair Carmon, Achal Dave, Reinhard Heckel, Niklas Muennighoff, Ludwig Schmidt
Scaling laws are useful guides for derisking expensive training runs, as they predict performance of large models using cheaper, small-scale experiments. However, there remain gaps between current scaling studies and how language models are ultimately trained and evaluated. For instance, scaling is usually studied in the compute-optimal training regime (i.e., Chinchilla optimal regime). In contrast, models are often over-trained to reduce inference costs. Moreover, scaling laws mostly predict loss on next-token prediction, but models are usually compared on downstream task performance. To address both shortcomings, we create a testbed of 104 models with 0.011B to 6.9B parameters trained with various numbers of tokens on three data distributions. First, we fit scaling laws that extrapolate in both the amount of over-training and the number of model parameters. This enables us to predict the validation loss of a 1.4B parameter, 900B token run (i.e., 32$times$ over-trained) and a 6.9B parameter, 138B token run (i.e., a compute-optimal run)$unicode{x2014}$each from experiments that take 300$times$ less compute. Second, we relate the perplexity of a language model to its downstream task performance by proposing a power law. We use this law to predict top-1 error averaged over downstream tasks for the two aforementioned models, using experiments that take 20$times$ less compute. Our experiments are available at https://github.com/mlfoundations/scaling.
Read more6/18/2024