SCALM: Towards Semantic Caching for Automated Chat Services with Large Language Models

0

Sign in to get full access
Overview
- This paper proposes SCALM, a system for semantic caching to improve the performance of automated chat services powered by large language models (LLMs).
- SCALM aims to reduce the number of costly LLM inference calls by caching and retrieving relevant responses based on the semantic similarity of user queries.
- The system leverages techniques like semantic query processing and scenario extraction to enhance the caching mechanism.
Plain English Explanation
Large language models (LLMs) have revolutionized the field of automated chat services, allowing machines to engage in natural conversations. However, using these powerful models comes with a significant computational cost, as each user query requires a costly inference process.
SCALM tackles this challenge by introducing a semantic caching system. Instead of always running the LLM, SCALM attempts to match the user's query to previously cached responses that are semantically similar. This helps reduce the number of expensive LLM calls, thereby improving the overall performance and efficiency of the chat service.
The key idea behind SCALM is to leverage advanced techniques like semantic query processing and scenario extraction to enhance the caching process. By understanding the context and meaning of user queries, SCALM can more accurately identify relevant cached responses, leading to better results and a smoother user experience.
Technical Explanation
SCALM employs a multi-stage approach to achieve semantic caching for automated chat services. The first stage involves semantic query processing, where user queries are analyzed and transformed into a semantic representation. This allows SCALM to capture the underlying meaning and context of the query, going beyond simple keyword matching.
Next, SCALM leverages scenario extraction techniques to identify the specific user intent or scenario associated with the query. By understanding the user's goal or the type of information they are seeking, SCALM can more effectively match the query to relevant cached responses.
The cached responses themselves are also semantically organized, allowing for efficient retrieval based on the query's semantic representation. SCALM uses advanced similarity matching algorithms to identify the most relevant cached responses, minimizing the need for costly LLM inference.
In cases where no suitable cached response is available, SCALM falls back to the LLM for generating a new response. However, this new response is then added to the cache, expanding the system's knowledge base and improving its future performance.
Critical Analysis
The SCALM system presents a promising approach to improving the efficiency of automated chat services powered by LLMs. By leveraging semantic caching, the system can potentially reduce the computational burden and latency associated with constantly relying on the LLM for every user query.
However, the paper does not provide detailed information on the performance evaluation of SCALM or the specific techniques used for semantic query processing and scenario extraction. Further research and empirical validation would be necessary to assess the system's effectiveness and practicality in real-world scenarios.
Additionally, the paper does not address potential issues related to privacy-aware caching or the cascade-aware training of language models, which could be important considerations for deploying SCALM in production environments.
Conclusion
The SCALM system proposed in this paper represents a significant step towards improving the efficiency and performance of automated chat services powered by large language models. By leveraging semantic caching and advanced techniques like semantic query processing and scenario extraction, SCALM has the potential to reduce the computational cost and latency associated with LLM-based chat services.
While further research and validation are needed, the core ideas behind SCALM showcase the importance of exploring innovative approaches to optimizing the use of large language models in interactive user applications, such as voice-based interfaces. As the field of conversational AI continues to evolve, systems like SCALM may play a crucial role in making these technologies more accessible and efficient for real-world deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SCALM: Towards Semantic Caching for Automated Chat Services with Large Language Models
Jiaxing Li, Chi Xu, Feng Wang, Isaac M von Riedemann, Cong Zhang, Jiangchuan Liu
Large Language Models (LLMs) have become increasingly popular, transforming a wide range of applications across various domains. However, the real-world effectiveness of their query cache systems has not been thoroughly investigated. In this work, we for the first time conducted an analysis on real-world human-to-LLM interaction data, identifying key challenges in existing caching solutions for LLM-based chat services. Our findings reveal that current caching methods fail to leverage semantic connections, leading to inefficient cache performance and extra token costs. To address these issues, we propose SCALM, a new cache architecture that emphasizes semantic analysis and identifies significant cache entries and patterns. We also detail the implementations of the corresponding cache storage and eviction strategies. Our evaluations show that SCALM increases cache hit ratios and reduces operational costs for LLMChat services. Compared with other state-of-the-art solutions in GPTCache, SCALM shows, on average, a relative increase of 63% in cache hit ratio and a relative improvement of 77% in tokens savings.
Read more6/4/2024
💬
0
Privacy-Aware Semantic Cache for Large Language Models
Waris Gill (Virginia Tech, USA), Mohamed Elidrisi (Cisco, USA), Pallavi Kalapatapu (Cisco, USA), Ammar Ahmed (University of Minnesota, Minneapolis, USA), Ali Anwar (University of Minnesota, Minneapolis, USA), Muhammad Ali Gulzar (Virginia Tech, USA)
Large Language Models (LLMs) like ChatGPT and Llama have revolutionized natural language processing and search engine dynamics. However, these models incur exceptionally high computational costs. For instance, GPT-3 consists of 175 billion parameters, where inference demands billions of floating-point operations. Caching is a natural solution to reduce LLM inference costs on repeated queries, which constitute about 31% of the total queries. However, existing caching methods are incapable of finding semantic similarities among LLM queries nor do they operate on contextual queries, leading to unacceptable false hit-and-miss rates. This paper introduces MeanCache, a user-centric semantic cache for LLM-based services that identifies semantically similar queries to determine cache hit or miss. Using MeanCache, the response to a user's semantically similar query can be retrieved from a local cache rather than re-querying the LLM, thus reducing costs, service provider load, and environmental impact. MeanCache leverages Federated Learning (FL) to collaboratively train a query similarity model without violating user privacy. By placing a local cache in each user's device and using FL, MeanCache reduces the latency and costs and enhances model performance, resulting in lower false hit rates. MeanCache also encodes context chains for every cached query, offering a simple yet highly effective mechanism to discern contextual query responses from standalone. Our experiments benchmarked against the state-of-the-art caching method, reveal that MeanCache attains an approximately 17% higher F-score and a 20% increase in precision during semantic cache hit-and-miss decisions while performing even better on contextual queries. It also reduces the storage requirement by 83% and accelerates semantic cache hit-and-miss decisions by 11%.
Read more7/17/2024
💬
80
Enhancing Large Language Model with Self-Controlled Memory Framework
Bing Wang, Xinnian Liang, Jian Yang, Hui Huang, Shuangzhi Wu, Peihao Wu, Lu Lu, Zejun Ma, Zhoujun Li
Large Language Models (LLMs) are constrained by their inability to process lengthy inputs, resulting in the loss of critical historical information. To address this limitation, in this paper, we propose the Self-Controlled Memory (SCM) framework to enhance the ability of LLMs to maintain long-term memory and recall relevant information. Our SCM framework comprises three key components: an LLM-based agent serving as the backbone of the framework, a memory stream storing agent memories, and a memory controller updating memories and determining when and how to utilize memories from memory stream. Additionally, the proposed SCM is able to process ultra-long texts without any modification or fine-tuning, which can integrate with any instruction following LLMs in a plug-and-play paradigm. Furthermore, we annotate a dataset to evaluate the effectiveness of SCM for handling lengthy inputs. The annotated dataset covers three tasks: long-term dialogues, book summarization, and meeting summarization. Experimental results demonstrate that our method achieves better retrieval recall and generates more informative responses compared to competitive baselines in long-term dialogues. (https://github.com/wbbeyourself/SCM4LLMs)
Read more9/20/2024
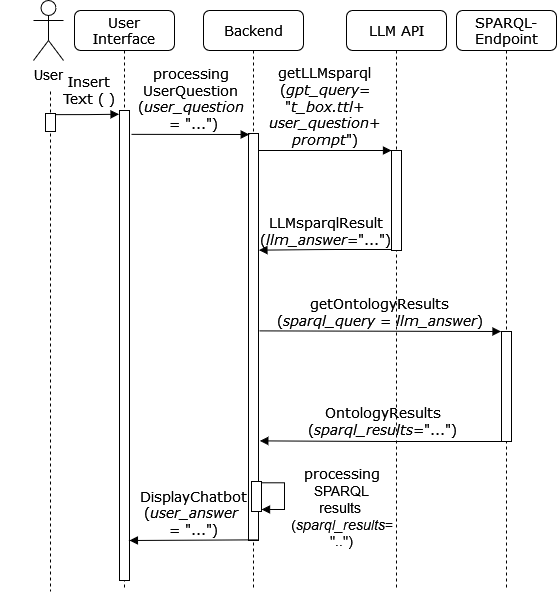
0
Chatbot-Based Ontology Interaction Using Large Language Models and Domain-Specific Standards
Jonathan Reif, Tom Jeleniewski, Milapji Singh Gill, Felix Gehlhoff, Alexander Fay
The following contribution introduces a concept that employs Large Language Models (LLMs) and a chatbot interface to enhance SPARQL query generation for ontologies, thereby facilitating intuitive access to formalized knowledge. Utilizing natural language inputs, the system converts user inquiries into accurate SPARQL queries that strictly query the factual content of the ontology, effectively preventing misinformation or fabrication by the LLM. To enhance the quality and precision of outcomes, additional textual information from established domain-specific standards is integrated into the ontology for precise descriptions of its concepts and relationships. An experimental study assesses the accuracy of generated SPARQL queries, revealing significant benefits of using LLMs for querying ontologies and highlighting areas for future research.
Read more8/6/2024