DisfluencySpeech -- Single-Speaker Conversational Speech Dataset with Paralanguage

0

Sign in to get full access
Overview
• This paper introduces the DisfluencySpeech dataset, a single-speaker conversational speech dataset with paralanguage features. • The dataset was created to support research in areas like speech synthesis, text-to-speech, and emotion modeling. • The dataset contains recordings of a single speaker engaging in natural conversations, including disfluencies, filled pauses, and other paralinguistic cues.
Plain English Explanation
The researchers have created a new dataset of recorded conversations by a single speaker. This dataset is designed to help researchers working on technologies like text-to-speech systems and emotion modeling in speech.
The key feature of this dataset is that it contains natural, conversational speech, including things like stutters, filler words, and other subtle vocal cues that people use in real conversations. This type of data can be very helpful for developing more realistic and expressive speech synthesis systems, as it allows the AI to learn from examples of how people actually speak.
By having a single speaker across all the recordings, the dataset provides a consistent voice that researchers can use to study individual speaking patterns and paralinguistic elements. This makes it a valuable resource for advancing the state-of-the-art in areas like speech recognition and emotional speech synthesis.
Technical Explanation
The DisfluencySpeech dataset consists of audio recordings of a single English speaker engaged in spontaneous conversations. The recordings capture a variety of paralinguistic elements, such as filled pauses (e.g., "um," "uh"), repetitions, restarts, and other disfluencies that are common in natural speech.
The dataset was collected in a controlled environment, with the speaker conversing with an interlocutor not present in the recordings. This setup was designed to elicit more natural and expressive speech compared to typical read-aloud or scripted speech datasets.
The audio data is accompanied by detailed transcripts that include annotations for the various disfluency and paralanguage phenomena observed. This allows researchers to study the relationship between the acoustic signal and the linguistic and paralinguistic content.
The dataset consists of approximately 20 hours of audio data, with each conversation lasting around 10-15 minutes. The speaker is a native English speaker with a standard North American accent.
Critical Analysis
The DisfluencySpeech dataset provides a valuable resource for researchers working on speech technologies, particularly in areas like text-to-speech and emotion modeling. By capturing natural, spontaneous speech, it offers a more realistic and diverse dataset compared to many existing speech corpora.
However, the dataset is limited to a single speaker, which may limit its generalizability to other voices and speaking styles. Additionally, the controlled recording setup, while aimed at eliciting natural speech, may still introduce some artificiality compared to truly spontaneous, unscripted conversations.
Further research could explore expanding the dataset to include multiple speakers, or even incorporating more diverse conversational scenarios, such as multi-party interactions or task-oriented dialogues. Analyzing the dataset's performance on specific speech technology tasks would also help to better understand its strengths and limitations.
Conclusion
The DisfluencySpeech dataset provides a valuable resource for researchers working on speech synthesis, text-to-speech, and emotion modeling in speech. By capturing natural, spontaneous speech with a variety of paralinguistic elements, it offers a more realistic dataset for developing and evaluating advanced speech technologies. The dataset's potential to support research in these areas makes it a significant contribution to the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DisfluencySpeech -- Single-Speaker Conversational Speech Dataset with Paralanguage
Kyra Wang, Dorien Herremans
Laughing, sighing, stuttering, and other forms of paralanguage do not contribute any direct lexical meaning to speech, but they provide crucial propositional context that aids semantic and pragmatic processes such as irony. It is thus important for artificial social agents to both understand and be able to generate speech with semantically-important paralanguage. Most speech datasets do not include transcribed non-lexical speech sounds and disfluencies, while those that do are typically multi-speaker datasets where each speaker provides relatively little audio. This makes it challenging to train conversational Text-to-Speech (TTS) synthesis models that include such paralinguistic components. We thus present DisfluencySpeech, a studio-quality labeled English speech dataset with paralanguage. A single speaker recreates nearly 10 hours of expressive utterances from the Switchboard-1 Telephone Speech Corpus (Switchboard), simulating realistic informal conversations. To aid the development of a TTS model that is able to predictively synthesise paralanguage from text without such components, we provide three different transcripts at different levels of information removal (removal of non-speech events, removal of non-sentence elements, and removal of false starts), as well as benchmark TTS models trained on each of these levels.
Read more6/14/2024

0
LearnerVoice: A Dataset of Non-Native English Learners' Spontaneous Speech
Haechan Kim, Junho Myung, Seoyoung Kim, Sungpah Lee, Dongyeop Kang, Juho Kim
Prevalent ungrammatical expressions and disfluencies in spontaneous speech from second language (L2) learners pose unique challenges to Automatic Speech Recognition (ASR) systems. However, few datasets are tailored to L2 learner speech. We publicly release LearnerVoice, a dataset consisting of 50.04 hours of audio and transcriptions of L2 learners' spontaneous speech. Our linguistic analysis reveals that transcriptions in our dataset contain L2S (L2 learner's Spontaneous speech) features, consisting of ungrammatical expressions and disfluencies (e.g., filler words, word repetitions, self-repairs, false starts), significantly more than native speech datasets. Fine-tuning whisper-small.en with LearnerVoice achieves a WER of 10.26%, 44.2% lower than vanilla whisper-small.en. Furthermore, our qualitative analysis indicates that 54.2% of errors from the vanilla model on LearnerVoice are attributable to L2S features, with 48.1% of them being reduced in the fine-tuned model.
Read more7/8/2024
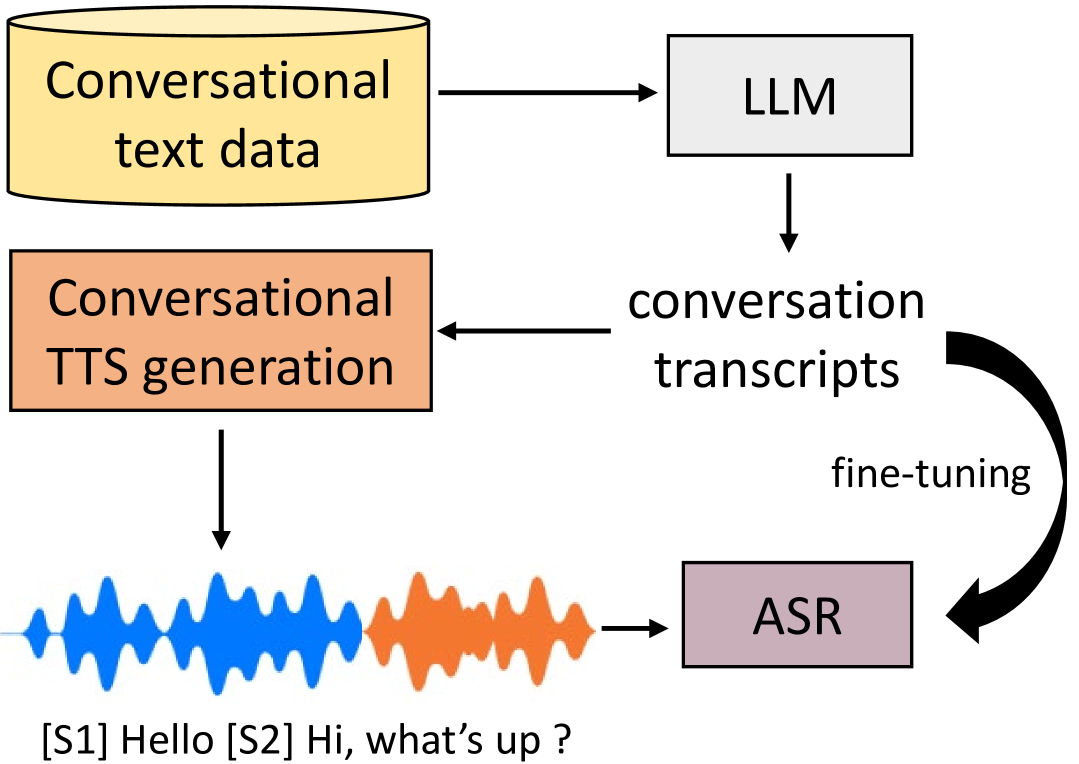
0
Generating Data with Text-to-Speech and Large-Language Models for Conversational Speech Recognition
Samuele Cornell, Jordan Darefsky, Zhiyao Duan, Shinji Watanabe
Currently, a common approach in many speech processing tasks is to leverage large scale pre-trained models by fine-tuning them on in-domain data for a particular application. Yet obtaining even a small amount of such data can be problematic, especially for sensitive domains and conversational speech scenarios, due to both privacy issues and annotation costs. To address this, synthetic data generation using single speaker datasets has been employed. Yet, for multi-speaker cases, such an approach often requires extensive manual effort and is prone to domain mismatches. In this work, we propose a synthetic data generation pipeline for multi-speaker conversational ASR, leveraging a large language model (LLM) for content creation and a conversational multi-speaker text-to-speech (TTS) model for speech synthesis. We conduct evaluation by fine-tuning the Whisper ASR model for telephone and distant conversational speech settings, using both in-domain data and generated synthetic data. Our results show that the proposed method is able to significantly outperform classical multi-speaker generation approaches that use external, non-conversational speech datasets.
Read more8/20/2024
💬
0
Integrating Paralinguistics in Speech-Empowered Large Language Models for Natural Conversation
Heeseung Kim, Soonshin Seo, Kyeongseok Jeong, Ohsung Kwon, Soyoon Kim, Jungwhan Kim, Jaehong Lee, Eunwoo Song, Myungwoo Oh, Jung-Woo Ha, Sungroh Yoon, Kang Min Yoo
Recent work shows promising results in expanding the capabilities of large language models (LLM) to directly understand and synthesize speech. However, an LLM-based strategy for modeling spoken dialogs remains elusive, calling for further investigation. This paper introduces an extensive speech-text LLM framework, the Unified Spoken Dialog Model (USDM), designed to generate coherent spoken responses with naturally occurring prosodic features relevant to the given input speech without relying on explicit automatic speech recognition (ASR) or text-to-speech (TTS) systems. We have verified the inclusion of prosody in speech tokens that predominantly contain semantic information and have used this foundation to construct a prosody-infused speech-text model. Additionally, we propose a generalized speech-text pretraining scheme that enhances the capture of cross-modal semantics. To construct USDM, we fine-tune our speech-text model on spoken dialog data using a multi-step spoken dialog template that stimulates the chain-of-reasoning capabilities exhibited by the underlying LLM. Automatic and human evaluations on the DailyTalk dataset demonstrate that our approach effectively generates natural-sounding spoken responses, surpassing previous and cascaded baselines. We will make our code and checkpoints publicly available.
Read more8/28/2024