SDPose: Tokenized Pose Estimation via Circulation-Guide Self-Distillation

0
Sign in to get full access
Overview
- This paper introduces SDPose, a novel approach for tokenized pose estimation using circulation-guided self-distillation.
- The key innovations include a circulation-guided self-distillation mechanism and a tokenized representation for human poses.
- The proposed method aims to improve the accuracy and efficiency of human pose estimation tasks.
Plain English Explanation
The researchers have developed a new technique called SDPose for estimating the positions of different parts of the human body in an image or video. This is known as "pose estimation," and it's an important task in computer vision with many applications, such as human-computer interaction, motion capture, and activity recognition.
The core idea behind SDPose is to use a "tokenized" representation of the human pose. This means breaking down the pose information into discrete units or "tokens" that the model can more easily process. The researchers also introduce a novel "circulation-guided self-distillation" mechanism, which helps the model learn more efficiently by having it teach itself.
By using this tokenized representation and self-distillation approach, the SDPose method is able to achieve higher accuracy and efficiency compared to previous pose estimation techniques. [This could lead to improvements in applications like robotics and video analysis.]
Technical Explanation
The key technical innovations in this paper are:
-
Tokenized Pose Representation: The human pose is represented as a sequence of tokens, where each token encodes information about the location and orientation of a particular body part. This tokenized representation allows the model to more easily capture the structural and spatial relationships between different parts of the body.
-
Circulation-Guided Self-Distillation: The researchers propose a self-distillation mechanism where the model learns to predict its own outputs, guided by a "circulation" module that encourages the model to explore different regions of the pose space. This self-supervised learning approach helps the model learn more robust and generalizable features for pose estimation.
-
Network Architecture: The SDPose model consists of a backbone network that encodes the input image into visual features, a circulation module that guides the self-distillation process, and a pose prediction head that outputs the final tokenized pose estimates.
The authors evaluate SDPose on several standard human pose estimation benchmarks and show that it outperforms previous state-of-the-art methods in terms of both accuracy and inference speed. The improvements are particularly notable for challenging scenarios, such as occluded or partially visible poses.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated approach for human pose estimation. The key strengths of the work include the innovative tokenized pose representation and the effective self-distillation mechanism, which together contribute to the model's strong performance.
However, the paper does not discuss some potential limitations or areas for further research. For example, it is unclear how the model would perform on highly complex or articulated poses, or how it would scale to multi-person scenarios. [Additionally, the authors do not explore the potential trade-offs between the tokenized representation and more traditional, dense pose representations, as seen in previous work.]
It would also be valuable to understand the computational and memory requirements of the SDPose model, as well as its robustness to noisy or low-quality input data. [These aspects could be important for real-world deployments, particularly in edge computing or resource-constrained applications.]
Overall, the SDPose method represents a significant advancement in human pose estimation, and the authors have made a valuable contribution to the field. Further research to address the potential limitations and expand the capabilities of the approach would be a logical next step.
Conclusion
The SDPose paper introduces a novel tokenized pose estimation technique that leverages circulation-guided self-distillation to achieve impressive results on standard benchmarks. The key innovations, including the tokenized pose representation and the self-distillation mechanism, demonstrate the potential for improving the accuracy and efficiency of human pose estimation.
While the paper does not address all possible limitations, the proposed approach represents an important step forward in the field of computer vision, with potential applications in areas such as human-computer interaction, motion analysis, and activity recognition. As the research in this domain continues to evolve, the insights and techniques presented in this work are likely to inspire further advancements and drive progress in the understanding and analysis of human movement.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SDPose: Tokenized Pose Estimation via Circulation-Guide Self-Distillation
Sichen Chen, Yingyi Zhang, Siming Huang, Ran Yi, Ke Fan, Ruixin Zhang, Peixian Chen, Jun Wang, Shouhong Ding, Lizhuang Ma
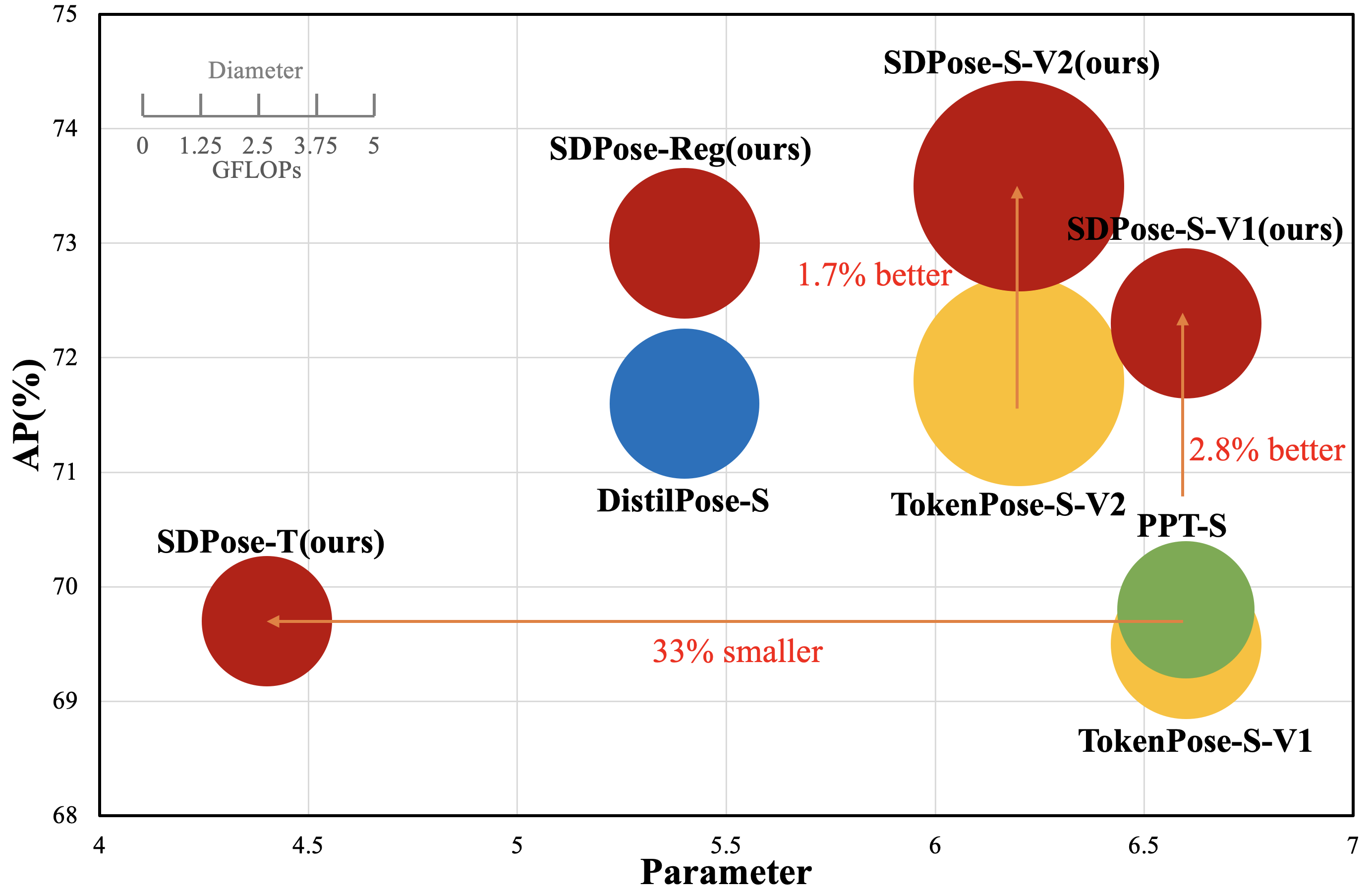
Recently, transformer-based methods have achieved state-of-the-art prediction quality on human pose estimation(HPE). Nonetheless, most of these top-performing transformer-based models are too computation-consuming and storage-demanding to deploy on edge computing platforms. Those transformer-based models that require fewer resources are prone to under-fitting due to their smaller scale and thus perform notably worse than their larger counterparts. Given this conundrum, we introduce SDPose, a new self-distillation method for improving the performance of small transformer-based models. To mitigate the problem of under-fitting, we design a transformer module named Multi-Cycled Transformer(MCT) based on multiple-cycled forwards to more fully exploit the potential of small model parameters. Further, in order to prevent the additional inference compute-consuming brought by MCT, we introduce a self-distillation scheme, extracting the knowledge from the MCT module to a naive forward model. Specifically, on the MSCOCO validation dataset, SDPose-T obtains 69.7% mAP with 4.4M parameters and 1.8 GFLOPs. Furthermore, SDPose-S-V2 obtains 73.5% mAP on the MSCOCO validation dataset with 6.2M parameters and 4.7 GFLOPs, achieving a new state-of-the-art among predominant tiny neural network methods. Our code is available at https://github.com/MartyrPenink/SDPose.
Read more4/5/2024

0
Estimating Human Poses Across Datasets: A Unified Skeleton and Multi-Teacher Distillation Approach
Muhammad Saif Ullah Khan, Dhavalkumar Limbachiya, Didier Stricker, Muhammad Zeshan Afzal
Human pose estimation is a key task in computer vision with various applications such as activity recognition and interactive systems. However, the lack of consistency in the annotated skeletons across different datasets poses challenges in developing universally applicable models. To address this challenge, we propose a novel approach integrating multi-teacher knowledge distillation with a unified skeleton representation. Our networks are jointly trained on the COCO and MPII datasets, containing 17 and 16 keypoints, respectively. We demonstrate enhanced adaptability by predicting an extended set of 21 keypoints, 4 (COCO) and 5 (MPII) more than original annotations, improving cross-dataset generalization. Our joint models achieved an average accuracy of 70.89 and 76.40, compared to 53.79 and 55.78 when trained on a single dataset and evaluated on both. Moreover, we also evaluate all 21 predicted points by our two models by reporting an AP of 66.84 and 72.75 on the Halpe dataset. This highlights the potential of our technique to address one of the most pressing challenges in pose estimation research and application - the inconsistency in skeletal annotations.
Read more5/31/2024

0
PoseMamba: Monocular 3D Human Pose Estimation with Bidirectional Global-Local Spatio-Temporal State Space Model
Yunlong Huang, Junshuo Liu, Ke Xian, Robert Caiming Qiu
Transformers have significantly advanced the field of 3D human pose estimation (HPE). However, existing transformer-based methods primarily use self-attention mechanisms for spatio-temporal modeling, leading to a quadratic complexity, unidirectional modeling of spatio-temporal relationships, and insufficient learning of spatial-temporal correlations. Recently, the Mamba architecture, utilizing the state space model (SSM), has exhibited superior long-range modeling capabilities in a variety of vision tasks with linear complexity. In this paper, we propose PoseMamba, a novel purely SSM-based approach with linear complexity for 3D human pose estimation in monocular video. Specifically, we propose a bidirectional global-local spatio-temporal SSM block that comprehensively models human joint relations within individual frames as well as temporal correlations across frames. Within this bidirectional global-local spatio-temporal SSM block, we introduce a reordering strategy to enhance the local modeling capability of the SSM. This strategy provides a more logical geometric scanning order and integrates it with the global SSM, resulting in a combined global-local spatial scan. We have quantitatively and qualitatively evaluated our approach using two benchmark datasets: Human3.6M and MPI-INF-3DHP. Extensive experiments demonstrate that PoseMamba achieves state-of-the-art performance on both datasets while maintaining a smaller model size and reducing computational costs. The code and models will be released.
Read more8/9/2024

0
Stable-Pose: Leveraging Transformers for Pose-Guided Text-to-Image Generation
Jiajun Wang, Morteza Ghahremani, Yitong Li, Bjorn Ommer, Christian Wachinger
Controllable text-to-image (T2I) diffusion models have shown impressive performance in generating high-quality visual content through the incorporation of various conditions. Current methods, however, exhibit limited performance when guided by skeleton human poses, especially in complex pose conditions such as side or rear perspectives of human figures. To address this issue, we present Stable-Pose, a novel adapter model that introduces a coarse-to-fine attention masking strategy into a vision Transformer (ViT) to gain accurate pose guidance for T2I models. Stable-Pose is designed to adeptly handle pose conditions within pre-trained Stable Diffusion, providing a refined and efficient way of aligning pose representation during image synthesis. We leverage the query-key self-attention mechanism of ViTs to explore the interconnections among different anatomical parts in human pose skeletons. Masked pose images are used to smoothly refine the attention maps based on target pose-related features in a hierarchical manner, transitioning from coarse to fine levels. Additionally, our loss function is formulated to allocate increased emphasis to the pose region, thereby augmenting the model's precision in capturing intricate pose details. We assessed the performance of Stable-Pose across five public datasets under a wide range of indoor and outdoor human pose scenarios. Stable-Pose achieved an AP score of 57.1 in the LAION-Human dataset, marking around 13% improvement over the established technique ControlNet. The project link and code is available at https://github.com/ai-med/StablePose.
Read more6/5/2024