Self-Recognition in Language Models

0

Sign in to get full access
Overview
- This paper explores the concept of self-recognition in large language models (LLMs), which are AI systems trained on vast amounts of text data to generate human-like language.
- The researchers investigate whether LLMs can recognize their own generated text and distinguish it from text written by humans.
- They develop various experiments and testing methods to measure the degree of self-recognition in different LLM architectures.
Plain English Explanation
The paper examines whether large language models, which are AI systems trained on huge datasets of text, can recognize when they have generated text themselves. This is an interesting question because these AI models are becoming increasingly capable of producing human-like language that can be difficult to distinguish from text written by people.
The researchers devised various experiments to test the self-recognition abilities of different language model architectures. They wanted to see if the models could accurately identify their own generated text and differentiate it from text written by humans. Understanding the extent of self-recognition in these AI systems can provide insights into their inner workings and cognitive processes.
Technical Explanation
The researchers developed several methods to measure self-recognition in large language models, including:
- Evaluating model performance on a dedicated "self-identification" task, where the model must classify text as either model-generated or human-written
- Analyzing the model's confidence in its own generations versus human-written text
- Examining whether models exhibit a "self-recognition bias" by favoring their own generations over human-written text
- Investigating the model's ability to understand the meaning and coherence of its own generated text
The experiments were conducted across multiple LLM architectures, including GPT-3, InstructGPT, and GPT-NeoX, to explore the generalizability of the findings.
Critical Analysis
The paper acknowledges several limitations and caveats to the research:
- The self-identification tasks may not fully capture the nuanced ways in which models recognize their own generated text.
- The findings may be specific to the particular LLM architectures and datasets used in the experiments.
- Further research is needed to understand the cognitive processes underlying self-recognition in language models.
Additionally, one could question whether the ability to recognize one's own generated text is a reliable proxy for true self-awareness or self-cognition in AI systems. The paper's findings suggest that LLMs exhibit some degree of self-recognition, but the implications for their broader cognitive capabilities remain an open and complex question.
Conclusion
This paper provides valuable insights into the self-recognition abilities of large language models, shedding light on their inner workings and the extent to which they can distinguish their own generated text from human-written text. The research suggests that LLMs exhibit some degree of self-recognition, but also highlights the need for further exploration of this topic to fully understand the cognitive capabilities of these increasingly advanced AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-Recognition in Language Models
Tim R. Davidson, Viacheslav Surkov, Veniamin Veselovsky, Giuseppe Russo, Robert West, Caglar Gulcehre
A rapidly growing number of applications rely on a small set of closed-source language models (LMs). This dependency might introduce novel security risks if LMs develop self-recognition capabilities. Inspired by human identity verification methods, we propose a novel approach for assessing self-recognition in LMs using model-generated security questions. Our test can be externally administered to keep track of frontier models as it does not require access to internal model parameters or output probabilities. We use our test to examine self-recognition in ten of the most capable open- and closed-source LMs currently publicly available. Our extensive experiments found no empirical evidence of general or consistent self-recognition in any examined LM. Instead, our results suggest that given a set of alternatives, LMs seek to pick the best answer, regardless of its origin. Moreover, we find indications that preferences about which models produce the best answers are consistent across LMs. We additionally uncover novel insights on position bias considerations for LMs in multiple-choice settings.
Read more7/10/2024
0
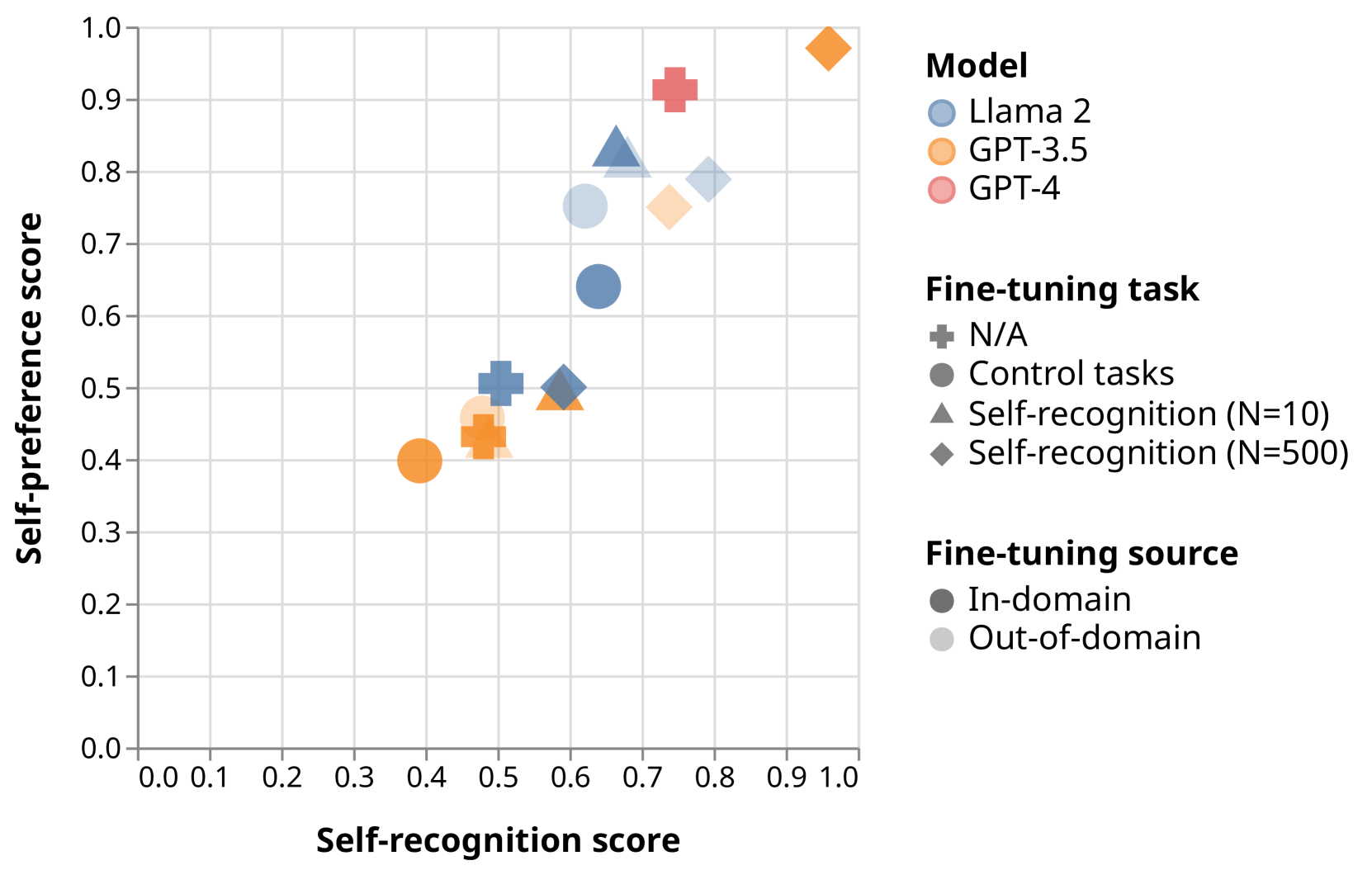
LLM Evaluators Recognize and Favor Their Own Generations
Arjun Panickssery, Samuel R. Bowman, Shi Feng
Self-evaluation using large language models (LLMs) has proven valuable not only in benchmarking but also methods like reward modeling, constitutional AI, and self-refinement. But new biases are introduced due to the same LLM acting as both the evaluator and the evaluatee. One such bias is self-preference, where an LLM evaluator scores its own outputs higher than others' while human annotators consider them of equal quality. But do LLMs actually recognize their own outputs when they give those texts higher scores, or is it just a coincidence? In this paper, we investigate if self-recognition capability contributes to self-preference. We discover that, out of the box, LLMs such as GPT-4 and Llama 2 have non-trivial accuracy at distinguishing themselves from other LLMs and humans. By fine-tuning LLMs, we discover a linear correlation between self-recognition capability and the strength of self-preference bias; using controlled experiments, we show that the causal explanation resists straightforward confounders. We discuss how self-recognition can interfere with unbiased evaluations and AI safety more generally.
Read more4/23/2024

0
Self-Cognition in Large Language Models: An Exploratory Study
Dongping Chen, Jiawen Shi, Yao Wan, Pan Zhou, Neil Zhenqiang Gong, Lichao Sun
While Large Language Models (LLMs) have achieved remarkable success across various applications, they also raise concerns regarding self-cognition. In this paper, we perform a pioneering study to explore self-cognition in LLMs. Specifically, we first construct a pool of self-cognition instruction prompts to evaluate where an LLM exhibits self-cognition and four well-designed principles to quantify LLMs' self-cognition. Our study reveals that 4 of the 48 models on Chatbot Arena--specifically Command R, Claude3-Opus, Llama-3-70b-Instruct, and Reka-core--demonstrate some level of detectable self-cognition. We observe a positive correlation between model size, training data quality, and self-cognition level. Additionally, we also explore the utility and trustworthiness of LLM in the self-cognition state, revealing that the self-cognition state enhances some specific tasks such as creative writing and exaggeration. We believe that our work can serve as an inspiration for further research to study the self-cognition in LLMs.
Read more7/2/2024
0
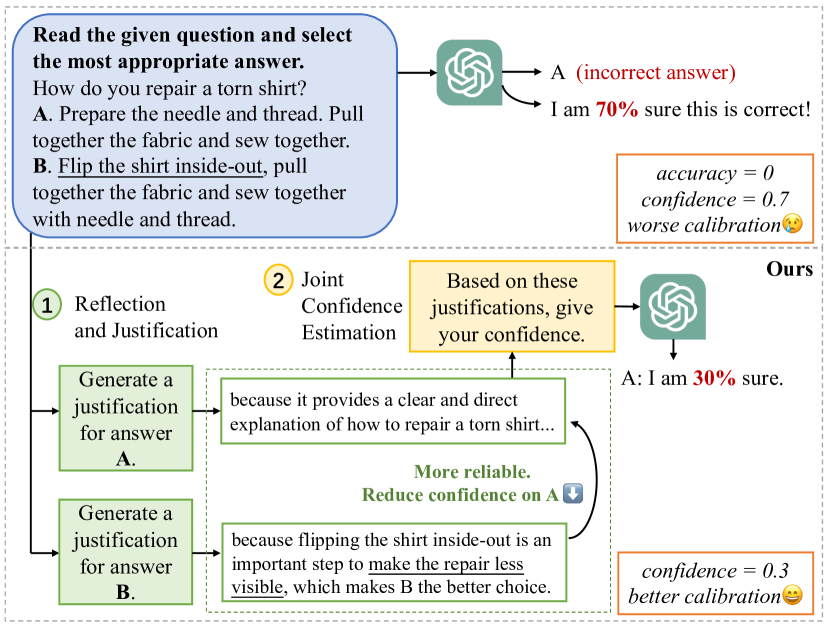
Think Twice Before Trusting: Self-Detection for Large Language Models through Comprehensive Answer Reflection
Moxin Li, Wenjie Wang, Fuli Feng, Fengbin Zhu, Qifan Wang, Tat-Seng Chua
Self-detection for Large Language Model (LLM) seeks to evaluate the LLM output trustability by leveraging LLM's own capabilities, alleviating the output hallucination issue. However, existing self-detection approaches only retrospectively evaluate answers generated by LLM, typically leading to the over-trust in incorrectly generated answers. To tackle this limitation, we propose a novel self-detection paradigm that considers the comprehensive answer space beyond LLM-generated answers. It thoroughly compares the trustability of multiple candidate answers to mitigate the over-trust in LLM-generated incorrect answers. Building upon this paradigm, we introduce a two-step framework, which firstly instructs LLM to reflect and provide justifications for each candidate answer, and then aggregates the justifications for comprehensive target answer evaluation. This framework can be seamlessly integrated with existing approaches for superior self-detection. Extensive experiments on six datasets spanning three tasks demonstrate the effectiveness of the proposed framework.
Read more6/5/2024