Self-Supervised Interpretable End-to-End Learning via Latent Functional Modularity

0
Sign in to get full access
Overview
• This paper introduces a novel approach to self-supervised interpretable sensorimotor learning that relies on latent functional modularity. • The proposed method aims to learn modular, interpretable representations that can be used for downstream robotic control tasks. • Key ideas include leveraging unsupervised learning to discover latent functional modules and using these modules to enable interpretable sensorimotor control.
Plain English Explanation
This research explores a new way for robots to learn how to move and interact with their environment through self-discovery, without explicit instructions. The core idea is to let the robot figure out on its own how different parts of its "body" (sensors and actuators) work together to produce various movements and behaviors.
The researchers developed a system that can automatically identify these functional modules - essentially, the robot's "building blocks" for movement. By understanding how these modules are connected and interact, the robot can then use this knowledge to control its movements in a more interpretable and effective way. This is an important step towards making robots that are not only skilled at physical tasks, but also transparent and understandable to the humans working with them.
The key benefits of this approach are: • Self-discovery: The robot learns the connections between its sensors and movements on its own, without needing to be explicitly programmed. • Interpretability: The modular structure provides insight into how the robot is accomplishing its tasks, making the system more transparent and understandable. • Flexible control: The identified functional modules can be recombined in different ways to enable a wide range of movements and behaviors.
Overall, this research aims to advance the field of robotics and AI by developing more interpretable and explainable AI systems that can learn and operate in a more modular and intuitive way.
Technical Explanation
The paper proposes a self-supervised learning framework for discovering latent functional modules that can be used for interpretable sensorimotor control. The key components include:
-
Unsupervised Representation Learning: The system uses an autoencoder-based approach to learn a modular, interpretable latent representation of the robot's sensory inputs and motor outputs.
-
Functional Module Discovery: The latent representation is structured to encourage the discovery of distinct functional modules that capture the underlying sensorimotor relationships. This is achieved through a novel regularization term that promotes latent code orthogonality.
-
Interpretable Sensorimotor Control: The identified functional modules can be directly mapped to individual motor commands, enabling the robot to execute complex behaviors by recombining the learned modules in a transparent and intuitive way.
The system was evaluated on several simulated robotic manipulation tasks, demonstrating improved performance and interpretability compared to traditional end-to-end control approaches. The modular structure was shown to provide better generalization to novel tasks and enable more flexible and modular control.
Critical Analysis
The proposed approach represents a promising step towards more interpretable and explainable AI systems for robotics. By emphasizing the discovery of modular, interpretable representations, the researchers have addressed an important challenge in the field.
However, the paper does not fully explore the limitations and potential issues with this approach. For example, the reliance on simulated environments raises questions about how well the method would translate to real-world robotic systems with noisy and uncertain sensory inputs. Additionally, the scalability of the approach to more complex robotic platforms and tasks remains an open question.
Further research is needed to understand the broader applicability and constraints of this self-supervised interpretable sensorimotor learning framework. Rigorous evaluations on physical robots and more diverse task domains would help to validate the approach and uncover potential areas for improvement.
Conclusion
This paper presents a novel self-supervised learning framework for discovering latent functional modules that can be used for interpretable sensorimotor control. By emphasizing the importance of modular, interpretable representations, the researchers have made an important contribution to the field of robotics and AI.
The proposed method has the potential to enable more flexible, intuitive, and explainable robotic control systems, which could have significant implications for a wide range of applications, from industrial automation to assistive technologies. As the field continues to advance, it will be crucial to address the remaining challenges and limitations to ensure the widespread adoption and real-world impact of these innovative approaches.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-Supervised Interpretable End-to-End Learning via Latent Functional Modularity
Hyunki Seong, David Hyunchul Shim
We introduce MoNet, a novel functionally modular network for self-supervised and interpretable end-to-end learning. By leveraging its functional modularity with a latent-guided contrastive loss function, MoNet efficiently learns task-specific decision-making processes in latent space without requiring task-level supervision. Moreover, our method incorporates an online, post-hoc explainability approach that enhances the interpretability of end-to-end inferences without compromising sensorimotor control performance. In real-world indoor environments, MoNet demonstrates effective visual autonomous navigation, outperforming baseline models by 7% to 28% in task specificity analysis. We further explore the interpretability of our network through post-hoc analysis of perceptual saliency maps and latent decision vectors. This provides valuable insights into the incorporation of explainable artificial intelligence into robotic learning, encompassing both perceptual and behavioral perspectives. Supplementary materials are available at https://sites.google.com/view/monet-lgc.
Read more6/6/2024
0
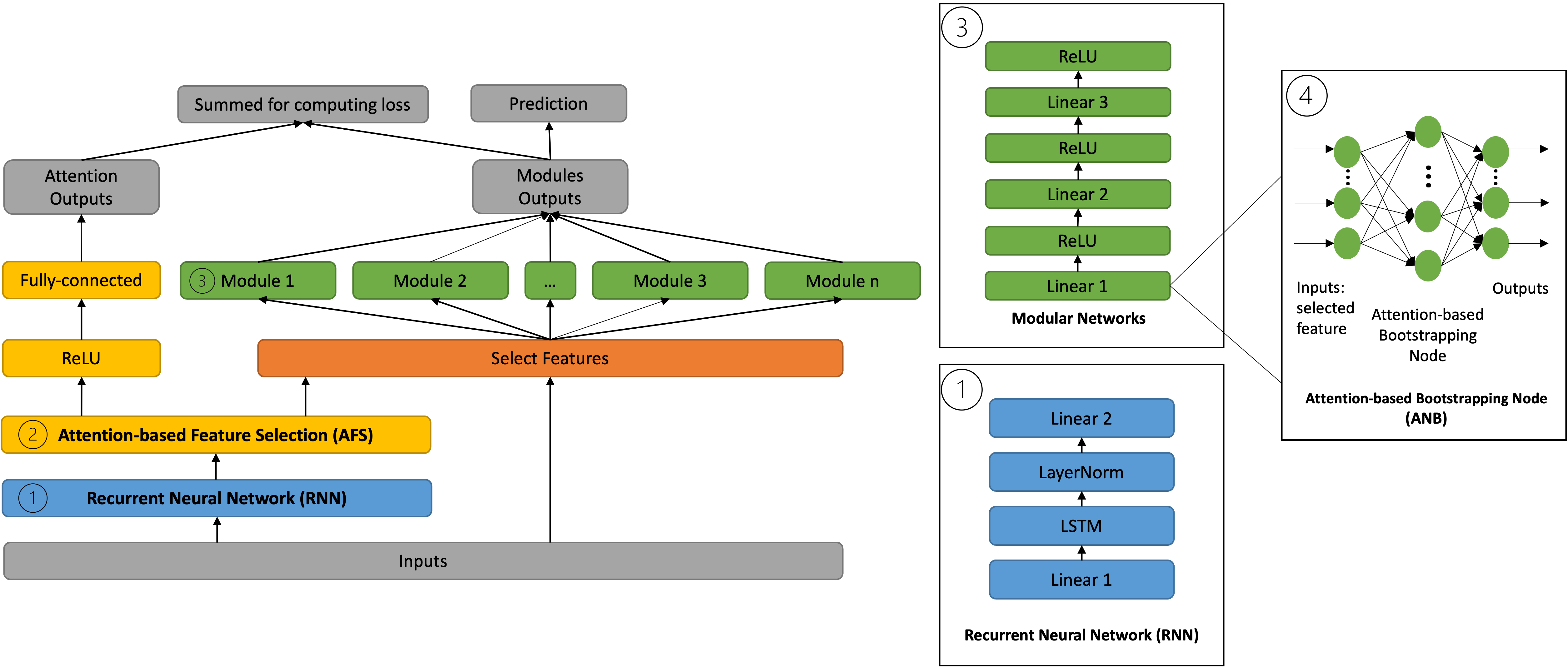
FocusLearn: Fully-Interpretable, High-Performance Modular Neural Networks for Time Series
Qiqi Su, Christos Kloukinas, Artur d'Avila Garcez
Multivariate time series have many applications, from healthcare and meteorology to life science. Although deep learning models have shown excellent predictive performance for time series, they have been criticised for being black-boxes or non-interpretable. This paper proposes a novel modular neural network model for multivariate time series prediction that is interpretable by construction. A recurrent neural network learns the temporal dependencies in the data while an attention-based feature selection component selects the most relevant features and suppresses redundant features used in the learning of the temporal dependencies. A modular deep network is trained from the selected features independently to show the users how features influence outcomes, making the model interpretable. Experimental results show that this approach can outperform state-of-the-art interpretable Neural Additive Models (NAM) and variations thereof in both regression and classification of time series tasks, achieving a predictive performance that is comparable to the top non-interpretable methods for time series, LSTM and XGBoost.
Read more5/6/2024

0
Restyling Unsupervised Concept Based Interpretable Networks with Generative Models
Jayneel Parekh, Quentin Bouniot, Pavlo Mozharovskyi, Alasdair Newson, Florence d'Alch'e-Buc
Developing inherently interpretable models for prediction has gained prominence in recent years. A subclass of these models, wherein the interpretable network relies on learning high-level concepts, are valued because of closeness of concept representations to human communication. However, the visualization and understanding of the learnt unsupervised dictionary of concepts encounters major limitations, specially for large-scale images. We propose here a novel method that relies on mapping the concept features to the latent space of a pretrained generative model. The use of a generative model enables high quality visualization, and naturally lays out an intuitive and interactive procedure for better interpretation of the learnt concepts. Furthermore, leveraging pretrained generative models has the additional advantage of making the training of the system more efficient. We quantitatively ascertain the efficacy of our method in terms of accuracy of the interpretable prediction network, fidelity of reconstruction, as well as faithfulness and consistency of learnt concepts. The experiments are conducted on multiple image recognition benchmarks for large-scale images. Project page available at https://jayneelparekh.github.io/VisCoIN_project_page/
Read more7/2/2024
0
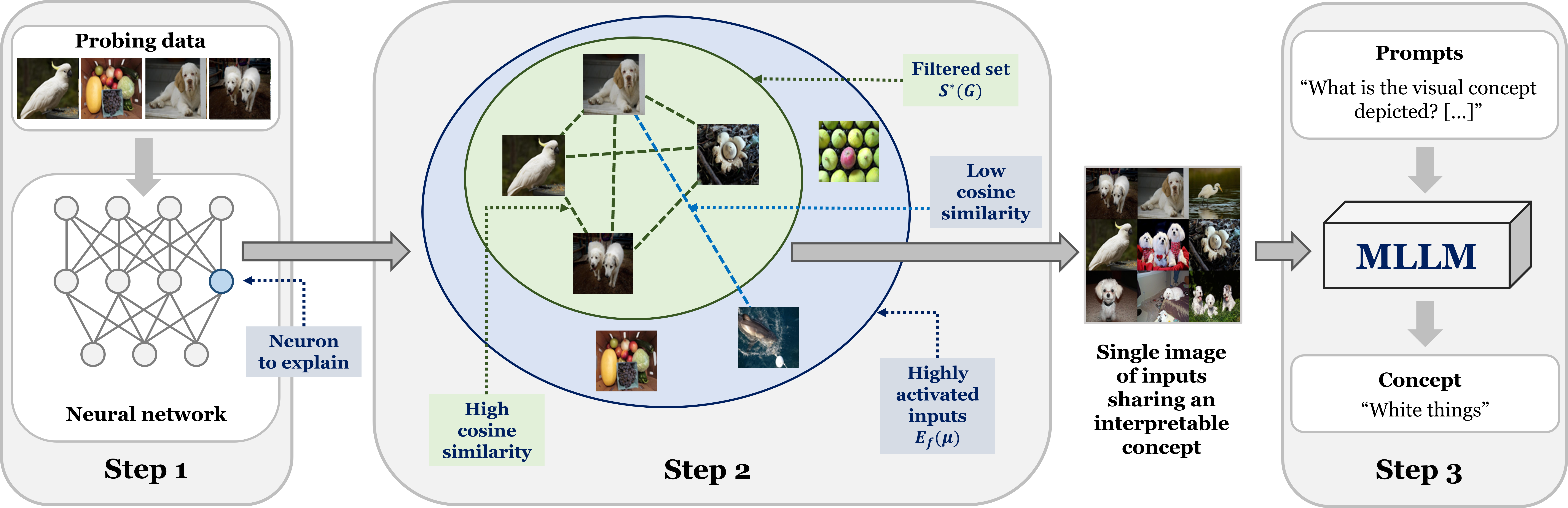
LLM-assisted Concept Discovery: Automatically Identifying and Explaining Neuron Functions
Nhat Hoang-Xuan, Minh Vu, My T. Thai
Providing textual concept-based explanations for neurons in deep neural networks (DNNs) is of importance in understanding how a DNN model works. Prior works have associated concepts with neurons based on examples of concepts or a pre-defined set of concepts, thus limiting possible explanations to what the user expects, especially in discovering new concepts. Furthermore, defining the set of concepts requires manual work from the user, either by directly specifying them or collecting examples. To overcome these, we propose to leverage multimodal large language models for automatic and open-ended concept discovery. We show that, without a restricted set of pre-defined concepts, our method gives rise to novel interpretable concepts that are more faithful to the model's behavior. To quantify this, we validate each concept by generating examples and counterexamples and evaluating the neuron's response on this new set of images. Collectively, our method can discover concepts and simultaneously validate them, providing a credible automated tool to explain deep neural networks.
Read more6/14/2024