Self-Supervised Models in Automatic Whispered Speech Recognition

0

Sign in to get full access
Overview
- Explores the use of self-supervised models for automatic whispered speech recognition
- Investigates the challenges of whispered speech and how self-supervised learning can address them
- Presents an empirical evaluation of different self-supervised models on whispered speech recognition tasks
Plain English Explanation
Whispered speech, where people speak softly without using their vocal cords, poses unique challenges for automatic speech recognition systems. This paper explores how self-supervised learning, a technique where models learn from unlabeled data, can help improve whispered speech recognition.
The researchers tested different self-supervised models on whispered speech datasets. Self-supervised models are trained on large amounts of unlabeled speech data, allowing them to learn general speech patterns without the need for manual transcription. The paper evaluates how well these self-supervised models perform on the specific task of recognizing whispered speech, which has different acoustic properties compared to normal speech.
By using self-supervised learning, the models can capture the nuances of whispered speech and adapt better than models trained only on labeled data. This could lead to more accurate and robust whispered speech recognition systems, with applications in areas like voice assistants, transcription, and accessibility for people with vocal impairments.
Technical Explanation
The paper investigates the use of self-supervised models for automatic whispered speech recognition. Self-supervised learning is a technique where models learn representations from unlabeled data, which can then be fine-tuned for specific tasks.
The researchers evaluated the performance of various self-supervised models, including Wav2Vec 2.0, HuBERT, and Whisper, on whispered speech recognition tasks. They used several whispered speech datasets to assess the models' ability to adapt to the unique characteristics of whispered speech, such as the lack of vocal cord vibration.
The results demonstrate that self-supervised models can effectively capture the nuances of whispered speech and outperform models trained solely on labeled data. This suggests that self-supervised learning is a promising approach for developing robust and accurate whispered speech recognition systems.
Critical Analysis
The paper provides a valuable contribution to the field of automatic speech recognition, particularly in the context of whispered speech. The researchers present a thorough empirical evaluation of various self-supervised models, which is important given the unique challenges posed by whispered speech.
However, the paper does not address potential limitations or caveats of the self-supervised approach. For example, the performance of these models may be dependent on the quality and diversity of the unlabeled data used for pretraining. Additionally, the paper does not explore the computational and resource requirements of fine-tuning self-supervised models for whispered speech recognition, which could be an important consideration for real-world deployment.
Further research could investigate the robustness of self-supervised models to different accents, speaking styles, and environmental conditions, as well as explore potential ways to optimize the fine-tuning process for whispered speech recognition.
Conclusion
This paper demonstrates the effectiveness of self-supervised models in addressing the challenges of automatic whispered speech recognition. By leveraging large amounts of unlabeled speech data, self-supervised models can learn general speech patterns and adapt better to the unique characteristics of whispered speech.
The findings suggest that self-supervised learning is a promising approach for developing robust and accurate whispered speech recognition systems, with potential applications in voice assistants, transcription services, and accessibility solutions for individuals with vocal impairments. As the research in this area continues to evolve, it will be important to address the potential limitations and explore ways to further optimize the performance of these models in real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-Supervised Models in Automatic Whispered Speech Recognition
Aref Farhadipour, Homa Asadi, Volker Dellwo
In automatic speech recognition, any factor that alters the acoustic properties of speech can pose a challenge to the system's performance. This paper presents a novel approach for automatic whispered speech recognition in the Irish dialect using the self-supervised WavLM model. Conventional automatic speech recognition systems often fail to accurately recognise whispered speech due to its distinct acoustic properties and the scarcity of relevant training data. To address this challenge, we utilized a pre-trained WavLM model, fine-tuned with a combination of whispered and normal speech data from the wTIMIT and CHAINS datasets, which include the English language in Singaporean and Irish dialects, respectively. Our baseline evaluation with the OpenAI Whisper model highlighted its limitations, achieving a Word Error Rate (WER) of 18.8% on whispered speech. In contrast, the proposed WavLM-based system significantly improved performance, achieving a WER of 9.22%. These results demonstrate the efficacy of our approach in recognising whispered speech and underscore the importance of tailored acoustic modeling for robust automatic speech recognition systems. This study provides valuable insights into developing effective automatic speech recognition solutions for challenging speech affected by whisper and dialect. The source codes for this paper are freely available.
Read more8/1/2024
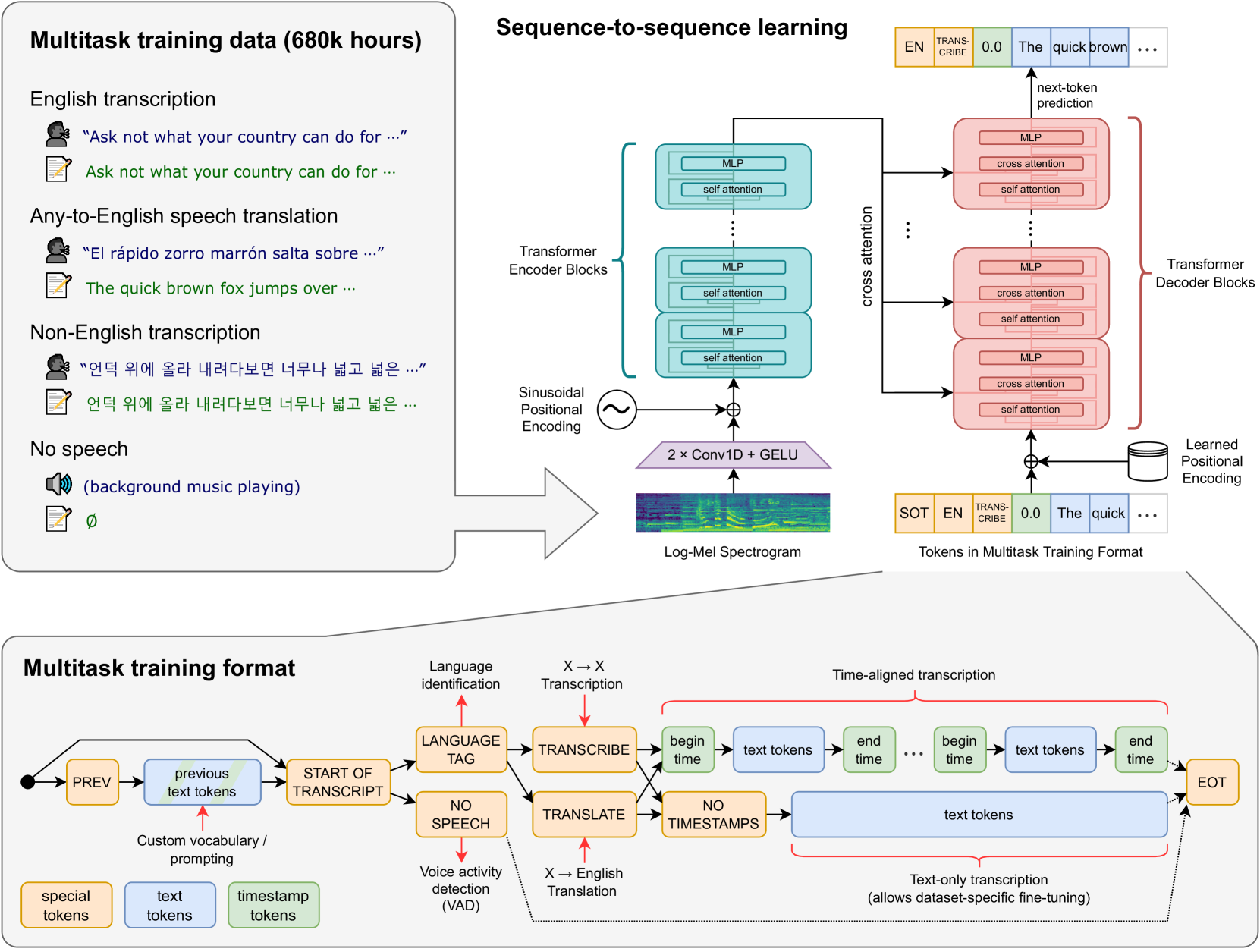
0
Efficient Compression of Multitask Multilingual Speech Models
Thomas Palmeira Ferraz
Whisper is a multitask and multilingual speech model covering 99 languages. It yields commendable automatic speech recognition (ASR) results in a subset of its covered languages, but the model still underperforms on a non-negligible number of under-represented languages, a problem exacerbated in smaller model versions. In this work, we examine its limitations, demonstrating the presence of speaker-related (gender, age) and model-related (resourcefulness and model size) bias. Despite that, we show that only model-related bias are amplified by quantization, impacting more low-resource languages and smaller models. Searching for a better compression approach, we propose DistilWhisper, an approach that is able to bridge the performance gap in ASR for these languages while retaining the advantages of multitask and multilingual capabilities. Our approach involves two key strategies: lightweight modular ASR fine-tuning of whisper-small using language-specific experts, and knowledge distillation from whisper-large-v2. This dual approach allows us to effectively boost ASR performance while keeping the robustness inherited from the multitask and multilingual pre-training. Results demonstrate that our approach is more effective than standard fine-tuning or LoRA adapters, boosting performance in the targeted languages for both in- and out-of-domain test sets, while introducing only a negligible parameter overhead at inference.
Read more5/3/2024

0
Keyword-Guided Adaptation of Automatic Speech Recognition
Aviv Shamsian, Aviv Navon, Neta Glazer, Gill Hetz, Joseph Keshet
Automatic Speech Recognition (ASR) technology has made significant progress in recent years, providing accurate transcription across various domains. However, some challenges remain, especially in noisy environments and specialized jargon. In this paper, we propose a novel approach for improved jargon word recognition by contextual biasing Whisper-based models. We employ a keyword spotting model that leverages the Whisper encoder representation to dynamically generate prompts for guiding the decoder during the transcription process. We introduce two approaches to effectively steer the decoder towards these prompts: KG-Whisper, which is aimed at fine-tuning the Whisper decoder, and KG-Whisper-PT, which learns a prompt prefix. Our results show a significant improvement in the recognition accuracy of specified keywords and in reducing the overall word error rates. Specifically, in unseen language generalization, we demonstrate an average WER improvement of 5.1% over Whisper.
Read more6/6/2024

0
Prompting Whisper for QA-driven Zero-shot End-to-end Spoken Language Understanding
Mohan Li, Simon Keizer, Rama Doddipatla
Zero-shot spoken language understanding (SLU) enables systems to comprehend user utterances in new domains without prior exposure to training data. Recent studies often rely on large language models (LLMs), leading to excessive footprints and complexity. This paper proposes the use of Whisper, a standalone speech processing model, for zero-shot end-to-end (E2E) SLU. To handle unseen semantic labels, SLU tasks are integrated into a question-answering (QA) framework, which prompts the Whisper decoder for semantics deduction. The system is efficiently trained with prefix-tuning, optimising a minimal set of parameters rather than the entire Whisper model. We show that the proposed system achieves a 40.7% absolute gain for slot filling (SLU-F1) on SLURP compared to a recently introduced zero-shot benchmark. Furthermore, it performs comparably to a Whisper-GPT-2 modular system under both in-corpus and cross-corpus evaluation settings, but with a relative 34.8% reduction in model parameters.
Read more6/24/2024