Self-supervised network distillation: an effective approach to exploration in sparse reward environments

0
🌐
Sign in to get full access
Overview
- Reinforcement learning can solve decision-making problems, but can struggle when the reward is too sparse for the agent to encounter during exploration
- The paper presents "Self-supervised Network Distillation (SND)", a class of intrinsic motivation algorithms that use distillation error as a novelty indicator to guide exploration
- The authors adapted three existing self-supervised methods and tested them on environments with sparse rewards, finding improved exploration and higher external rewards compared to baseline models
Plain English Explanation
Reinforcement learning is a powerful technique for training an agent to make good decisions in an environment, based on a reward system. However, if the reward is very rare or hard to find, the agent may struggle to learn effectively. The solution proposed in this paper is to give the agent an "intrinsic motivation" - an internal drive to explore novel or surprising things, which can help it discover the external rewards more reliably.
The key idea is to use "novelty detection" to identify when the agent is encountering something new or unfamiliar. The authors developed a class of algorithms called "Self-supervised Network Distillation (SND)" that use the "distillation error" - how well a predictive model can match a target model - as a signal of novelty. This builds on prior work in intrinsic motivation and self-supervised exploration.
The authors tested this approach on a set of challenging environments with very sparse rewards. They found that their SND algorithms were able to explore more effectively and achieve higher external rewards than baseline models, suggesting the intrinsic motivation provided by novelty detection can be a powerful tool for overcoming exploration challenges. This relates to other research on using intrinsic rewards for safe and effective exploration and avoiding harmful exploration behaviors.
Technical Explanation
The paper presents "Self-supervised Network Distillation (SND)", a class of intrinsic motivation algorithms for reinforcement learning. The key idea is to use the error in predicting the output of a "target" neural network model as a signal of novelty or surprise, which can then be used to guide the agent's exploration.
The authors adapted three existing self-supervised methods for this purpose: Random Network Distillation (RND), Variational Information Distillation (VID), and Surprisal Adaptive Intrinsic Motivation (SAIM). In each case, the agent is trained with both an external reward signal and an intrinsic reward signal based on the distillation error.
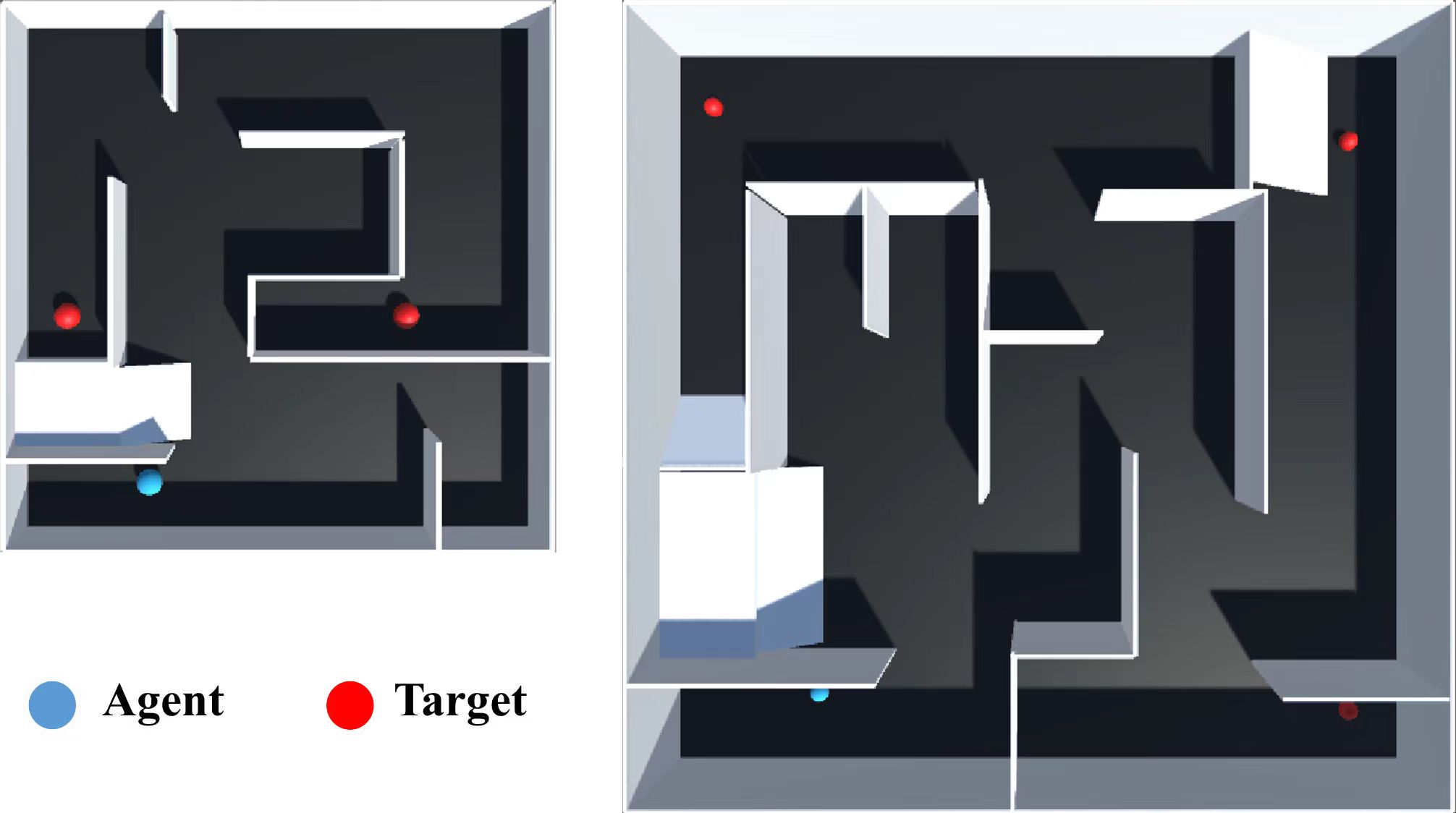
The authors tested these SND algorithms on a suite of 10 challenging exploration environments with sparse rewards. They found that the SND agents achieved faster growth in external rewards and higher final rewards compared to baseline agents using only the external rewards. This suggests the intrinsic motivation provided by novelty detection can significantly improve exploration in sparse reward settings.
The authors also applied analytical methods to provide insights into the behavior of their proposed models. This includes visualizing the novelty signals generated during exploration and examining how the intrinsic and external rewards interact to shape the agent's behavior.
Critical Analysis
The paper presents a novel and promising approach to overcoming exploration challenges in reinforcement learning. By using novelty detection as an intrinsic motivation signal, the SND algorithms were able to guide the agent towards discovering valuable rewards more efficiently.
However, the paper does not deeply explore the limitations or potential downsides of this approach. For example, it's unclear how sensitive the performance is to the specific implementation details of the distillation-based novelty detection. There may also be concerns about reward hacking, where the agent learns to maximize the intrinsic reward signal in ways that don't align with the intended objectives.
Additionally, the paper focuses on a relatively narrow set of environments, and more research would be needed to understand how well the SND approach generalizes to other problem domains. The authors acknowledge this and suggest further testing on "harder exploration problems" as an area for future work.
Overall, the research is technically sound and the results are compelling, but readers should think critically about the potential caveats and areas for improvement. As with any machine learning technique, the real-world applicability and safety of SND algorithms will require careful consideration and ongoing evaluation.
Conclusion
This paper introduces "Self-supervised Network Distillation (SND)", a novel class of intrinsic motivation algorithms that use distillation error as a novelty signal to guide exploration in reinforcement learning. The authors' experiments demonstrate that this approach can significantly improve an agent's ability to discover sparse rewards, compared to baseline models.
The technical insights and analytical methods provided in the paper offer valuable contributions to the field of intrinsic motivation and exploration in reinforcement learning. While the results are promising, further research is needed to fully understand the limitations and potential issues with this approach.
Overall, the SND algorithms represent an interesting and potentially impactful development in the quest to create more efficient and effective reinforcement learning agents, particularly for challenging exploration problems. As the field continues to advance, techniques like this may play an important role in expanding the capabilities of AI systems to tackle complex real-world decision-making tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
0
Self-supervised network distillation: an effective approach to exploration in sparse reward environments
Matej Pech'av{c}, Michal Chovanec, Igor Farkav{s}
Reinforcement learning can solve decision-making problems and train an agent to behave in an environment according to a predesigned reward function. However, such an approach becomes very problematic if the reward is too sparse and so the agent does not come across the reward during the environmental exploration. The solution to such a problem may be to equip the agent with an intrinsic motivation that will provide informed exploration during which the agent is likely to also encounter external reward. Novelty detection is one of the promising branches of intrinsic motivation research. We present Self-supervised Network Distillation (SND), a class of intrinsic motivation algorithms based on the distillation error as a novelty indicator, where the predictor model and the target model are both trained. We adapted three existing self-supervised methods for this purpose and experimentally tested them on a set of ten environments that are considered difficult to explore. The results show that our approach achieves faster growth and higher external reward for the same training time compared to the baseline models, which implies improved exploration in a very sparse reward environment. In addition, the analytical methods we applied provide valuable explanatory insights into our proposed models.
Read more6/12/2024

0
Exploration and Anti-Exploration with Distributional Random Network Distillation
Kai Yang, Jian Tao, Jiafei Lyu, Xiu Li
Exploration remains a critical issue in deep reinforcement learning for an agent to attain high returns in unknown environments. Although the prevailing exploration Random Network Distillation (RND) algorithm has been demonstrated to be effective in numerous environments, it often needs more discriminative power in bonus allocation. This paper highlights the bonus inconsistency issue within RND, pinpointing its primary limitation. To address this issue, we introduce the Distributional RND (DRND), a derivative of the RND. DRND enhances the exploration process by distilling a distribution of random networks and implicitly incorporating pseudo counts to improve the precision of bonus allocation. This refinement encourages agents to engage in more extensive exploration. Our method effectively mitigates the inconsistency issue without introducing significant computational overhead. Both theoretical analysis and experimental results demonstrate the superiority of our approach over the original RND algorithm. Our method excels in challenging online exploration scenarios and effectively serves as an anti-exploration mechanism in D4RL offline tasks. Our code is publicly available at https://github.com/yk7333/DRND.
Read more5/21/2024
0
Random Network Distillation Based Deep Reinforcement Learning for AGV Path Planning
Huilin Yin, Shengkai Su, Yinjia Lin, Pengju Zhen, Karin Festl, Daniel Watzenig
With the flourishing development of intelligent warehousing systems, the technology of Automated Guided Vehicle (AGV) has experienced rapid growth. Within intelligent warehousing environments, AGV is required to safely and rapidly plan an optimal path in complex and dynamic environments. Most research has studied deep reinforcement learning to address this challenge. However, in the environments with sparse extrinsic rewards, these algorithms often converge slowly, learn inefficiently or fail to reach the target. Random Network Distillation (RND), as an exploration enhancement, can effectively improve the performance of proximal policy optimization, especially enhancing the additional intrinsic rewards of the AGV agent which is in sparse reward environments. Moreover, most of the current research continues to use 2D grid mazes as experimental environments. These environments have insufficient complexity and limited action sets. To solve this limitation, we present simulation environments of AGV path planning with continuous actions and positions for AGVs, so that it can be close to realistic physical scenarios. Based on our experiments and comprehensive analysis of the proposed method, the results demonstrate that our proposed method enables AGV to more rapidly complete path planning tasks with continuous actions in our environments. A video of part of our experiments can be found at https://youtu.be/lwrY9YesGmw.
Read more4/22/2024
🤿
0
Variational Dynamic for Self-Supervised Exploration in Deep Reinforcement Learning
Chenjia Bai, Peng Liu, Kaiyu Liu, Lingxiao Wang, Yingnan Zhao, Lei Han
Efficient exploration remains a challenging problem in reinforcement learning, especially for tasks where extrinsic rewards from environments are sparse or even totally disregarded. Significant advances based on intrinsic motivation show promising results in simple environments but often get stuck in environments with multimodal and stochastic dynamics. In this work, we propose a variational dynamic model based on the conditional variational inference to model the multimodality and stochasticity. We consider the environmental state-action transition as a conditional generative process by generating the next-state prediction under the condition of the current state, action, and latent variable, which provides a better understanding of the dynamics and leads a better performance in exploration. We derive an upper bound of the negative log-likelihood of the environmental transition and use such an upper bound as the intrinsic reward for exploration, which allows the agent to learn skills by self-supervised exploration without observing extrinsic rewards. We evaluate the proposed method on several image-based simulation tasks and a real robotic manipulating task. Our method outperforms several state-of-the-art environment model-based exploration approaches.
Read more4/3/2024