Semantic Grouping Network for Audio Source Separation

0

Sign in to get full access
Overview
- Presents a Semantic Grouping Network (SGN) for audio source separation
- Uses visual cues to assist in separating audio sources
- Outperforms state-of-the-art audio-only and audio-visual methods on several benchmark datasets
Plain English Explanation
The paper introduces a new approach called the Semantic Grouping Network (SGN) for separating different audio sources, such as voices or musical instruments, from a single recorded audio clip. It does this by using both the audio information and visual cues related to the audio sources.
The key idea is that visual cues can provide useful information to help identify and separate the different sound sources. For example, seeing a person's mouth moving can help identify their voice in a mixed audio recording. The SGN model learns to exploit these audio-visual connections to isolate the individual sources more accurately than using audio alone.
The researchers show that the SGN model outperforms state-of-the-art audio-only and audio-visual methods on several benchmark datasets for audio source separation. This suggests the value of incorporating visual information to improve this important audio processing task.
Technical Explanation
The Semantic Grouping Network (SGN) is a deep learning model that takes as input a mixed audio recording and associated video frames, and outputs separated audio streams for each individual source.
The model consists of several key components:
- Audio Encoder: Encodes the input audio into a latent representation.
- Video Encoder: Encodes the video frames into a latent representation.
- Semantic Grouping Module: Learns to associate the audio and video latent representations, allowing the model to leverage visual cues to group the audio sources.
- Source Separation Module: Uses the grouped audio-visual features to generate the separated audio streams.
The researchers train the model end-to-end on audio-visual datasets, allowing it to learn the connections between the visual and auditory signals. During inference, the model can then use these learned associations to better isolate the individual sound sources in new, mixed audio recordings.
The experiments show that the SGN model achieves state-of-the-art performance on several audio source separation benchmarks, outperforming prior audio-only and audio-visual methods. This demonstrates the value of incorporating semantic visual information to improve this important audio processing task.
Critical Analysis
The paper presents a compelling approach to audio source separation that leverages both audio and visual cues. The Semantic Grouping Network architecture is well-designed and the empirical results are strong, suggesting the method is a valuable contribution to the field.
However, the paper does acknowledge some limitations. For example, the model's performance may degrade if the visual information is noisy or incomplete, such as in cases of occlusion or low video quality. Additionally, the approach may have difficulty separating sources that do not have distinct visual signatures, like two similar-sounding musical instruments.
Further research could explore ways to make the model more robust to visual noise and to handle a wider range of audio-visual scenarios. Incorporating self-supervised learning techniques may also help the model learn more generalizable audio-visual associations.
Overall, the Semantic Grouping Network represents an exciting step forward in leveraging multimodal information for audio source separation. With continued research and refinement, this approach could have significant real-world applications in areas like audio production, video conferencing, and assistive technology.
Conclusion
The Semantic Grouping Network (SGN) is a novel deep learning model that uses both audio and visual information to separate individual sound sources from a mixed audio recording. By learning to associate the audio and visual cues, the SGN model can leverage the semantic connections between the two modalities to isolate the different sound sources more accurately than using audio alone.
The empirical results show that the SGN outperforms state-of-the-art audio-only and audio-visual methods on several benchmark datasets, demonstrating the value of this multimodal approach to audio source separation. While the method has some limitations, the overall approach represents an exciting advancement in this important audio processing task with broad applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Semantic Grouping Network for Audio Source Separation
Shentong Mo, Yapeng Tian
Recently, audio-visual separation approaches have taken advantage of the natural synchronization between the two modalities to boost audio source separation performance. They extracted high-level semantics from visual inputs as the guidance to help disentangle sound representation for individual sources. Can we directly learn to disentangle the individual semantics from the sound itself? The dilemma is that multiple sound sources are mixed together in the original space. To tackle the difficulty, in this paper, we present a novel Semantic Grouping Network, termed as SGN, that can directly disentangle sound representations and extract high-level semantic information for each source from input audio mixture. Specifically, SGN aggregates category-wise source features through learnable class tokens of sounds. Then, the aggregated semantic features can be used as the guidance to separate the corresponding audio sources from the mixture. We conducted extensive experiments on music-only and universal sound separation benchmarks: MUSIC, FUSS, MUSDB18, and VGG-Sound. The results demonstrate that our SGN significantly outperforms previous audio-only methods and audio-visual models without utilizing additional visual cues.
Read more7/8/2024
0
Weakly-supervised Audio Separation via Bi-modal Semantic Similarity
Tanvir Mahmud, Saeed Amizadeh, Kazuhito Koishida, Diana Marculescu
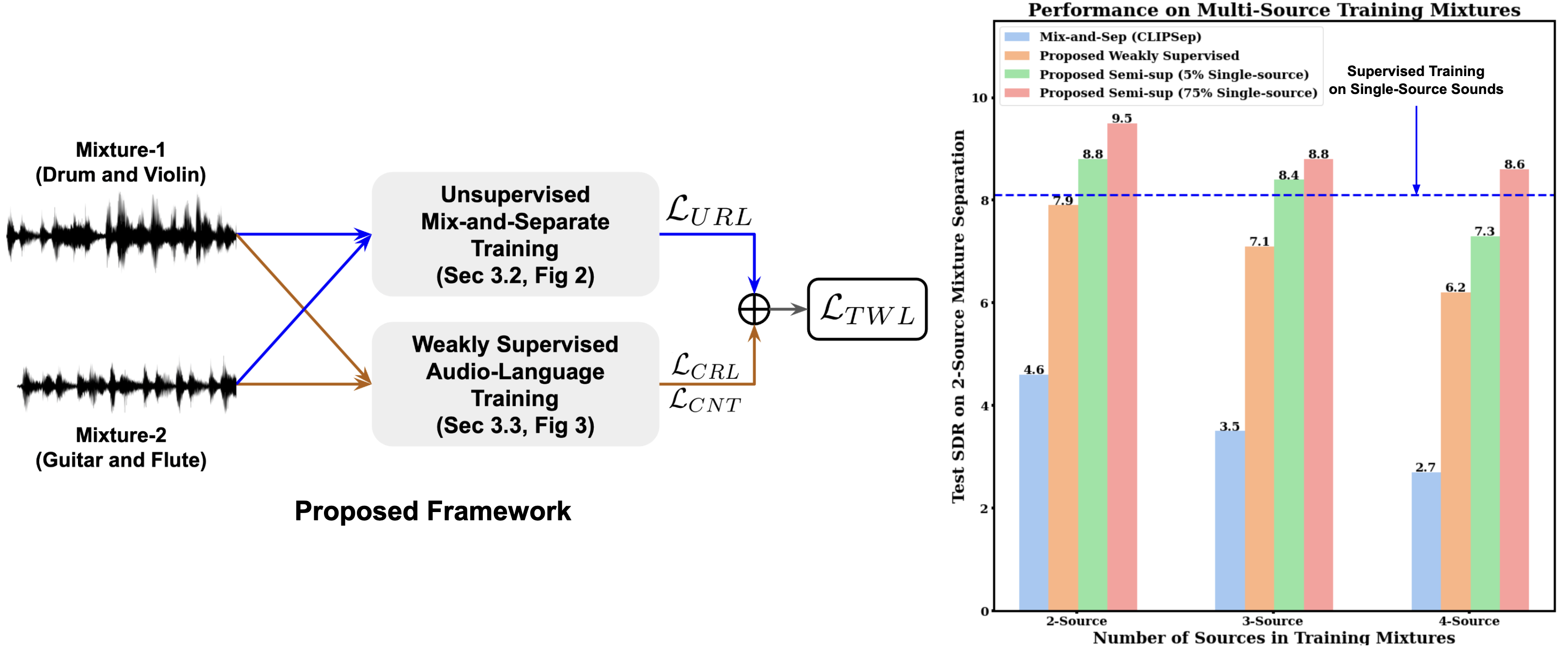
Conditional sound separation in multi-source audio mixtures without having access to single source sound data during training is a long standing challenge. Existing mix-and-separate based methods suffer from significant performance drop with multi-source training mixtures due to the lack of supervision signal for single source separation cases during training. However, in the case of language-conditional audio separation, we do have access to corresponding text descriptions for each audio mixture in our training data, which can be seen as (rough) representations of the audio samples in the language modality. To this end, in this paper, we propose a generic bi-modal separation framework which can enhance the existing unsupervised frameworks to separate single-source signals in a target modality (i.e., audio) using the easily separable corresponding signals in the conditioning modality (i.e., language), without having access to single-source samples in the target modality during training. We empirically show that this is well within reach if we have access to a pretrained joint embedding model between the two modalities (i.e., CLAP). Furthermore, we propose to incorporate our framework into two fundamental scenarios to enhance separation performance. First, we show that our proposed methodology significantly improves the performance of purely unsupervised baselines by reducing the distribution shift between training and test samples. In particular, we show that our framework can achieve 71% boost in terms of Signal-to-Distortion Ratio (SDR) over the baseline, reaching 97.5% of the supervised learning performance. Second, we show that we can further improve the performance of the supervised learning itself by 17% if we augment it by our proposed weakly-supervised framework, that enables a powerful semi-supervised framework for audio separation.
Read more4/3/2024

0
Integrating Audio, Visual, and Semantic Information for Enhanced Multimodal Speaker Diarization
Luyao Cheng, Hui Wang, Siqi Zheng, Yafeng Chen, Rongjie Huang, Qinglin Zhang, Qian Chen, Xihao Li
Speaker diarization, the process of segmenting an audio stream or transcribed speech content into homogenous partitions based on speaker identity, plays a crucial role in the interpretation and analysis of human speech. Most existing speaker diarization systems rely exclusively on unimodal acoustic information, making the task particularly challenging due to the innate ambiguities of audio signals. Recent studies have made tremendous efforts towards audio-visual or audio-semantic modeling to enhance performance. However, even the incorporation of up to two modalities often falls short in addressing the complexities of spontaneous and unstructured conversations. To exploit more meaningful dialogue patterns, we propose a novel multimodal approach that jointly utilizes audio, visual, and semantic cues to enhance speaker diarization. Our method elegantly formulates the multimodal modeling as a constrained optimization problem. First, we build insights into the visual connections among active speakers and the semantic interactions within spoken content, thereby establishing abundant pairwise constraints. Then we introduce a joint pairwise constraint propagation algorithm to cluster speakers based on these visual and semantic constraints. This integration effectively leverages the complementary strengths of different modalities, refining the affinity estimation between individual speaker embeddings. Extensive experiments conducted on multiple multimodal datasets demonstrate that our approach consistently outperforms state-of-the-art speaker diarization methods.
Read more8/23/2024
0
T-VSL: Text-Guided Visual Sound Source Localization in Mixtures
Tanvir Mahmud, Yapeng Tian, Diana Marculescu
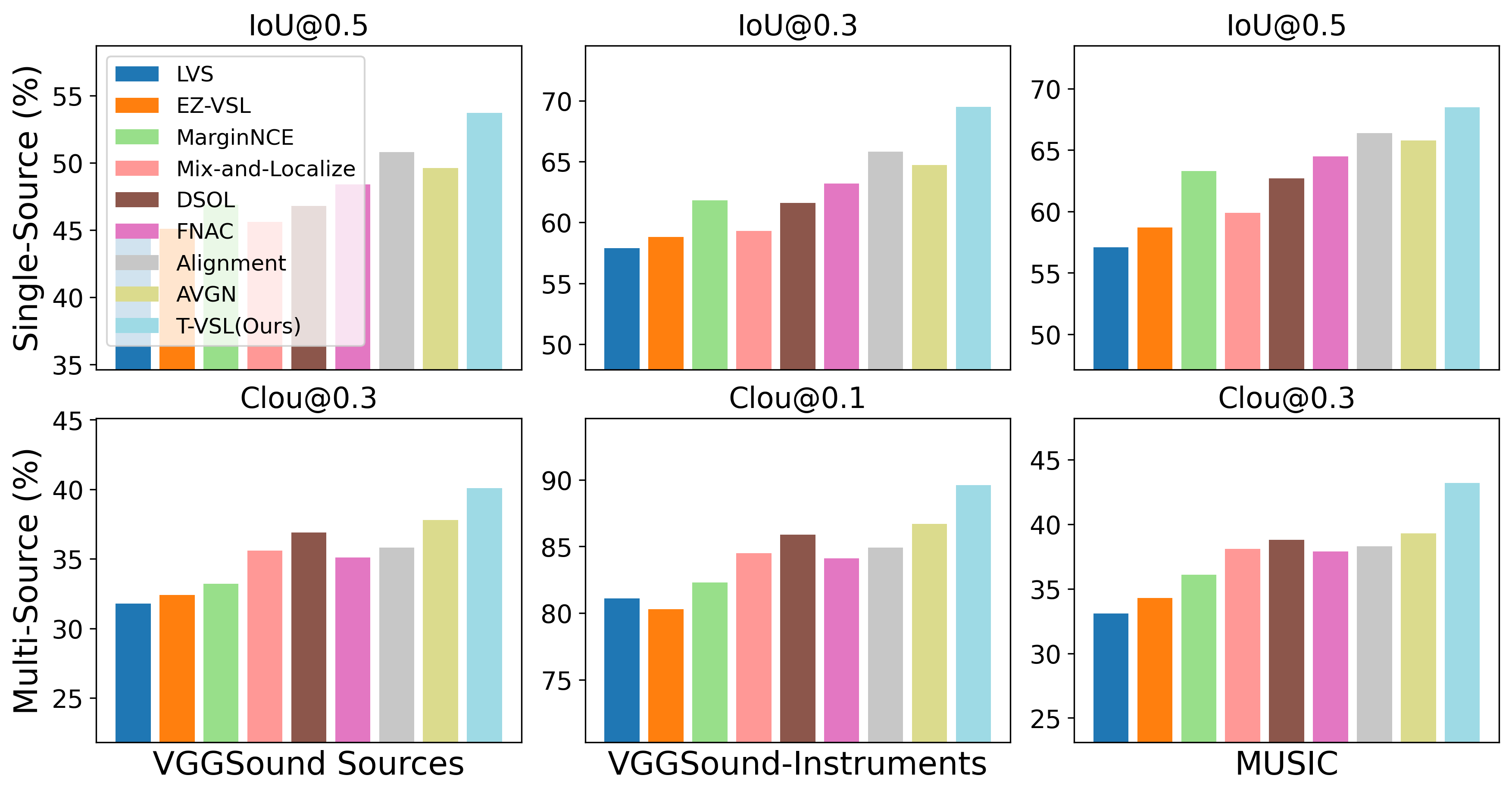
Visual sound source localization poses a significant challenge in identifying the semantic region of each sounding source within a video. Existing self-supervised and weakly supervised source localization methods struggle to accurately distinguish the semantic regions of each sounding object, particularly in multi-source mixtures. These methods often rely on audio-visual correspondence as guidance, which can lead to substantial performance drops in complex multi-source localization scenarios. The lack of access to individual source sounds in multi-source mixtures during training exacerbates the difficulty of learning effective audio-visual correspondence for localization. To address this limitation, in this paper, we propose incorporating the text modality as an intermediate feature guide using tri-modal joint embedding models (e.g., AudioCLIP) to disentangle the semantic audio-visual source correspondence in multi-source mixtures. Our framework, dubbed T-VSL, begins by predicting the class of sounding entities in mixtures. Subsequently, the textual representation of each sounding source is employed as guidance to disentangle fine-grained audio-visual source correspondence from multi-source mixtures, leveraging the tri-modal AudioCLIP embedding. This approach enables our framework to handle a flexible number of sources and exhibits promising zero-shot transferability to unseen classes during test time. Extensive experiments conducted on the MUSIC, VGGSound, and VGGSound-Instruments datasets demonstrate significant performance improvements over state-of-the-art methods. Code is released at https://github.com/enyac-group/T-VSL/tree/main
Read more7/9/2024