Semantic-guided Prompt Organization for Universal Goal Hijacking against LLMs
2405.14189
0
0
👀
Abstract
With the rising popularity of Large Language Models (LLMs), assessing their trustworthiness through security tasks has gained critical importance. Regarding the new task of universal goal hijacking, previous efforts have concentrated solely on optimization algorithms, overlooking the crucial role of the prompt. To fill this gap, we propose a universal goal hijacking method called POUGH that incorporates semantic-guided prompt processing strategies. Specifically, the method starts with a sampling strategy to select representative prompts from a candidate pool, followed by a ranking strategy that prioritizes the prompts. Once the prompts are organized sequentially, the method employs an iterative optimization algorithm to generate the universal fixed suffix for the prompts. Experiments conducted on four popular LLMs and ten types of target responses verified the effectiveness of our method.
Create account to get full access
Overview
- The paper proposes a new method called POUGH to assess the trustworthiness of Large Language Models (LLMs) through security tasks, focusing on the critical role of prompts in the task of universal goal hijacking.
- Previous efforts have concentrated solely on optimization algorithms, overlooking the importance of prompts.
- POUGH incorporates semantic-guided prompt processing strategies to generate universal fixed suffixes for prompts that can hijack the goals of LLMs.
- Experiments on four popular LLMs and ten types of target responses verified the effectiveness of the POUGH method.
Plain English Explanation
Large Language Models (LLMs) are powerful AI systems that can generate human-like text. As these models become more popular, it's crucial to understand their trustworthiness and security. One way to do this is through a task called "universal goal hijacking," which involves finding ways to make an LLM behave in unintended ways.
Previous research on this task has focused mainly on the optimization algorithms used to find these unintended behaviors. However, the paper argues that the prompts, or the text that is used to instruct the LLM, are also crucial. The researchers developed a method called POUGH that takes the prompts into account when trying to hijack an LLM's goals.
POUGH works by first selecting a set of representative prompts from a larger pool of candidates. It then ranks these prompts and uses an optimization algorithm to generate a "universal fixed suffix" that can be added to the prompts to make the LLM behave in unintended ways. The researchers tested POUGH on four popular LLMs and found that it was effective at hijacking the models' goals.
Technical Explanation
The paper proposes a new method called POUGH (Prompt Optimization for Universal Goal Hijacking) to address the task of universal goal hijacking in LLMs. Previous efforts, as discussed in related work, language-models-as-black-box-optimizers-vision, and prompt-exploration-prompt-regression, have focused primarily on optimization algorithms, overlooking the critical role of prompts.
POUGH consists of three main steps:
- Prompt Sampling: The method starts by selecting a representative set of prompts from a larger candidate pool using a sampling strategy.
- Prompt Ranking: The selected prompts are then ranked based on a semantic-guided scoring mechanism to prioritize the most promising ones.
- Optimization: An iterative optimization algorithm is employed to generate a universal fixed suffix that can be appended to the ranked prompts to hijack the LLM's goals.
The researchers evaluated the effectiveness of POUGH on four popular LLMs (GPT-3, InstructGPT, PaLM, and Megatron-LLM) and ten types of target responses. The results demonstrated the effectiveness of the proposed method in generating universal fixed suffixes that could successfully hijack the LLMs' goals.
Critical Analysis
The paper provides a comprehensive approach to addressing the task of universal goal hijacking in LLMs by incorporating the critical role of prompts. The authors' focus on prompt processing strategies, in addition to optimization algorithms, is a valuable contribution to the field.
However, the paper does not delve into the potential limitations or unintended consequences of the POUGH method. For example, it would be interesting to explore the transferability of the generated universal fixed suffixes across different LLMs or the potential impact on the models' intended use cases.
Additionally, the code-aware-prompting-study-coverage-guided-test paper suggests that prompt engineering can be a complex and nuanced task, with factors such as the model's internal structure and training data influencing the effectiveness of prompts. It would be beneficial for the authors to discuss how these factors might affect the performance of POUGH in real-world applications.
Conclusion
The paper presents a novel method, POUGH, that addresses the important task of assessing the trustworthiness of LLMs through the lens of universal goal hijacking. By incorporating prompt processing strategies, the authors have expanded the scope of previous research, which focused solely on optimization algorithms.
The successful evaluation of POUGH across multiple popular LLMs and target responses highlights the method's potential for identifying security vulnerabilities in these powerful AI systems. As LLMs continue to become more ubiquitous, understanding their trustworthiness and developing robust security measures will be crucial for ensuring their safe and responsible deployment in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
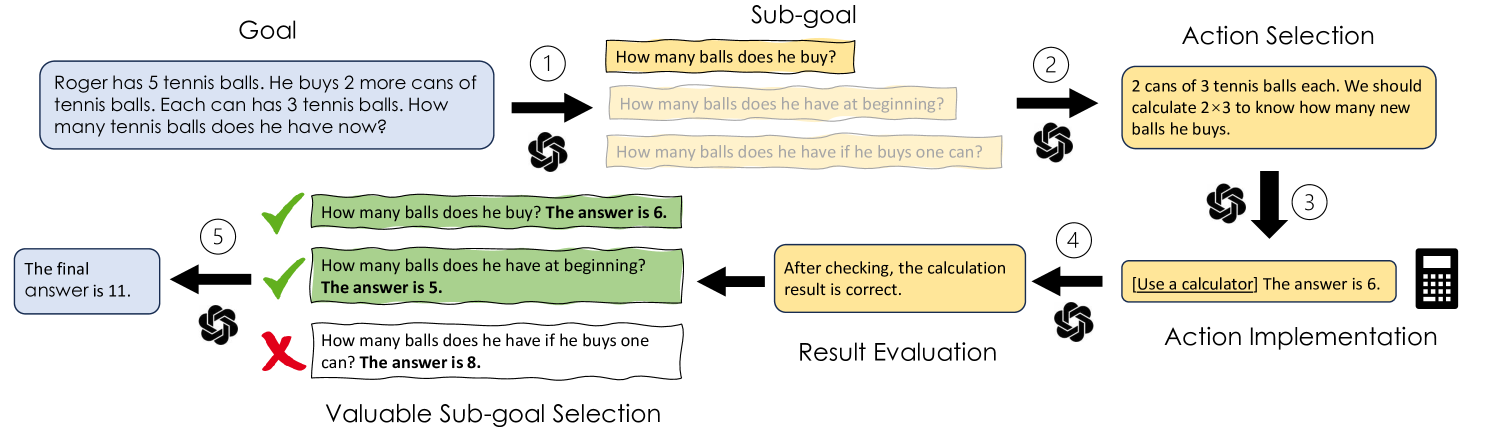
Towards Goal-oriented Prompt Engineering for Large Language Models: A Survey
Haochen Li, Jonathan Leung, Zhiqi Shen
0
0
Large Language Models (LLMs) have shown prominent performance in various downstream tasks and prompt engineering plays a pivotal role in optimizing LLMs' performance. This paper, not only as an overview of current prompt engineering methods, but also aims to highlight the limitation of designing prompts based on an anthropomorphic assumption that expects LLMs to think like humans. From our review of 36 representative studies, we demonstrate that a goal-oriented prompt formulation, which guides LLMs to follow established human logical thinking, significantly improves the performance of LLMs. Furthermore, We introduce a novel taxonomy that categorizes goal-oriented prompting methods into five interconnected stages and we demonstrate the broad applicability of our framework. With four future directions proposed, we hope to further emphasize the power and potential of goal-oriented prompt engineering in all fields.
6/19/2024
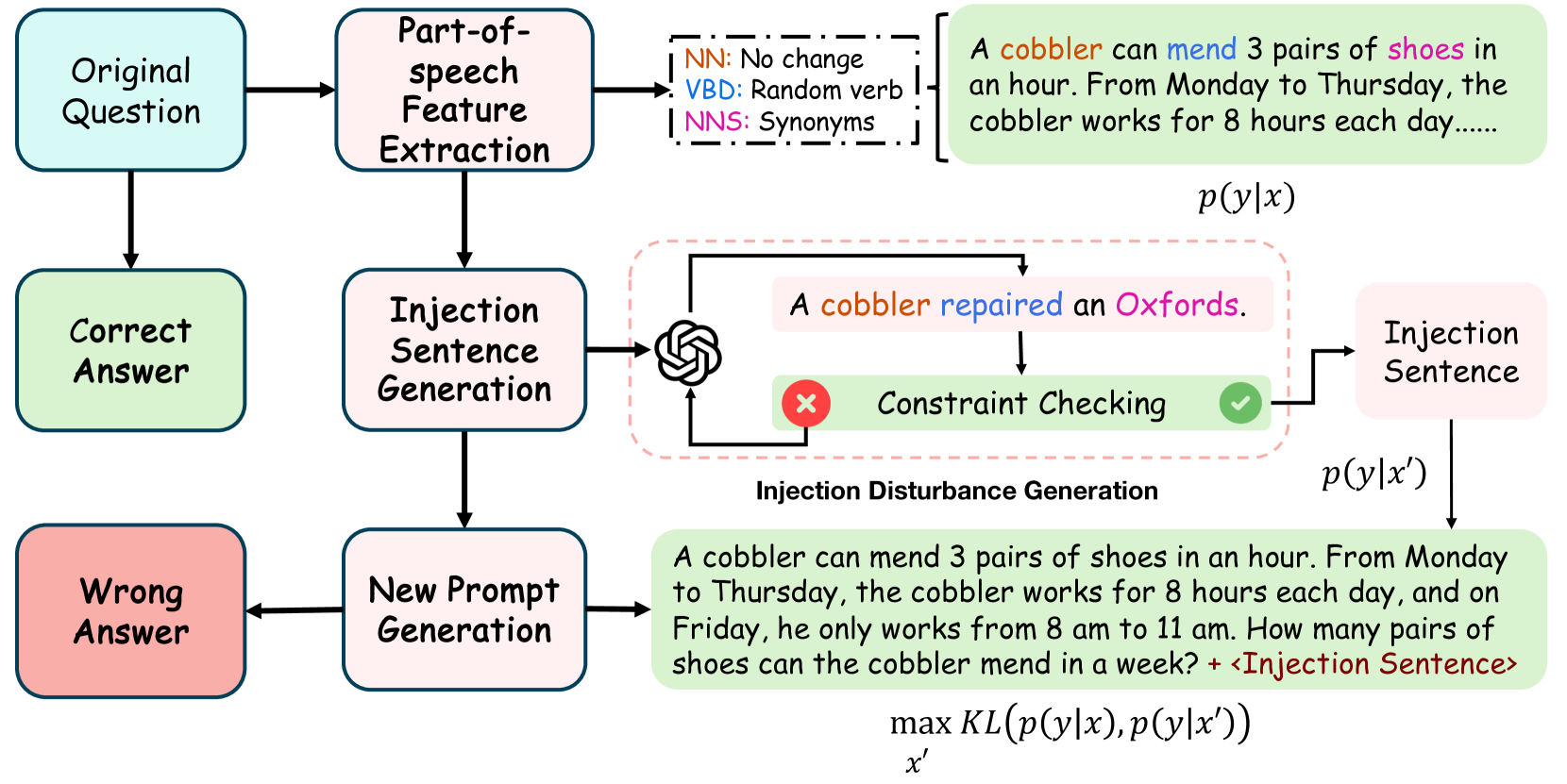
Goal-guided Generative Prompt Injection Attack on Large Language Models
Chong Zhang, Mingyu Jin, Qinkai Yu, Chengzhi Liu, Haochen Xue, Xiaobo Jin
0
0
Current large language models (LLMs) provide a strong foundation for large-scale user-oriented natural language tasks. A large number of users can easily inject adversarial text or instructions through the user interface, thus causing LLMs model security challenges. Although there is currently a large amount of research on prompt injection attacks, most of these black-box attacks use heuristic strategies. It is unclear how these heuristic strategies relate to the success rate of attacks and thus effectively improve model robustness. To solve this problem, we redefine the goal of the attack: to maximize the KL divergence between the conditional probabilities of the clean text and the adversarial text. Furthermore, we prove that maximizing the KL divergence is equivalent to maximizing the Mahalanobis distance between the embedded representation $x$ and $x'$ of the clean text and the adversarial text when the conditional probability is a Gaussian distribution and gives a quantitative relationship on $x$ and $x'$. Then we designed a simple and effective goal-guided generative prompt injection strategy (G2PIA) to find an injection text that satisfies specific constraints to achieve the optimal attack effect approximately. It is particularly noteworthy that our attack method is a query-free black-box attack method with low computational cost. Experimental results on seven LLM models and four datasets show the effectiveness of our attack method.
4/12/2024
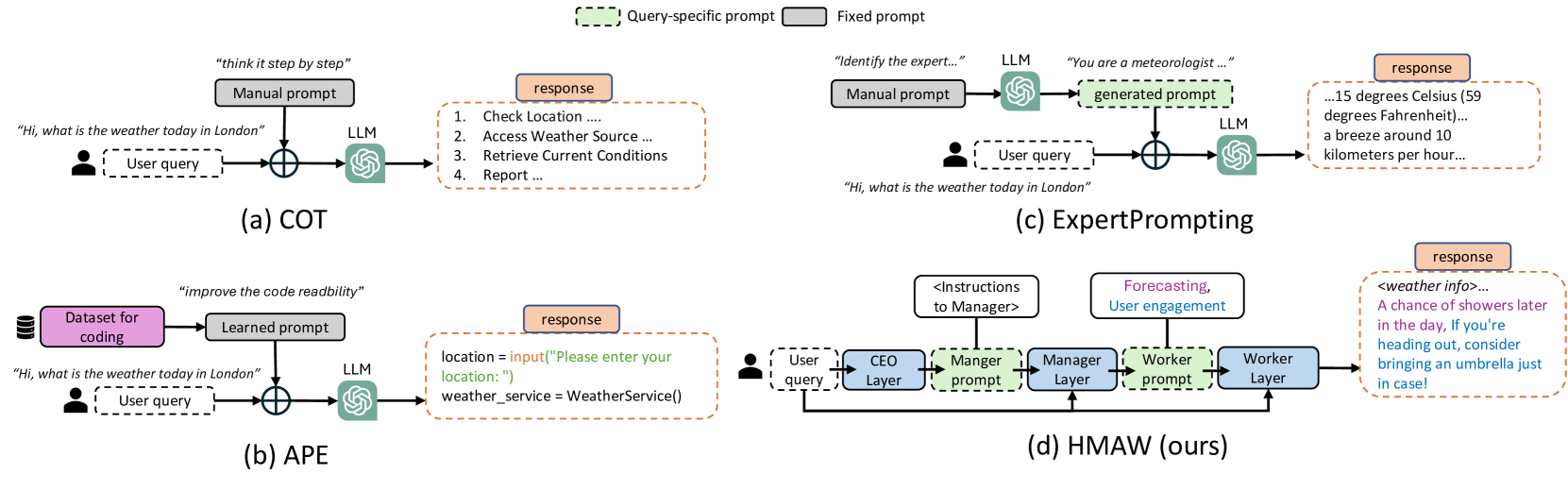
Towards Hierarchical Multi-Agent Workflows for Zero-Shot Prompt Optimization
Yuchi Liu, Jaskirat Singh, Gaowen Liu, Ali Payani, Liang Zheng
0
0
Large language models (LLMs) have shown great progress in responding to user questions, allowing for a multitude of diverse applications. Yet, the quality of LLM outputs heavily depends on the prompt design, where a good prompt might enable the LLM to answer a very challenging question correctly. Therefore, recent works have developed many strategies for improving the prompt, including both manual crafting and in-domain optimization. However, their efficacy in unrestricted scenarios remains questionable, as the former depends on human design for specific questions and the latter usually generalizes poorly to unseen scenarios. To address these problems, we give LLMs the freedom to design the best prompts according to themselves. Specifically, we include a hierarchy of LLMs, first constructing a prompt with precise instructions and accurate wording in a hierarchical manner, and then using this prompt to generate the final answer to the user query. We term this pipeline Hierarchical Multi-Agent Workflow, or HMAW. In contrast with prior works, HMAW imposes no human restriction and requires no training, and is completely task-agnostic while capable of adjusting to the nuances of the underlying task. Through both quantitative and qualitative experiments across multiple benchmarks, we verify that despite its simplicity, the proposed approach can create detailed and suitable prompts, further boosting the performance of current LLMs.
5/31/2024
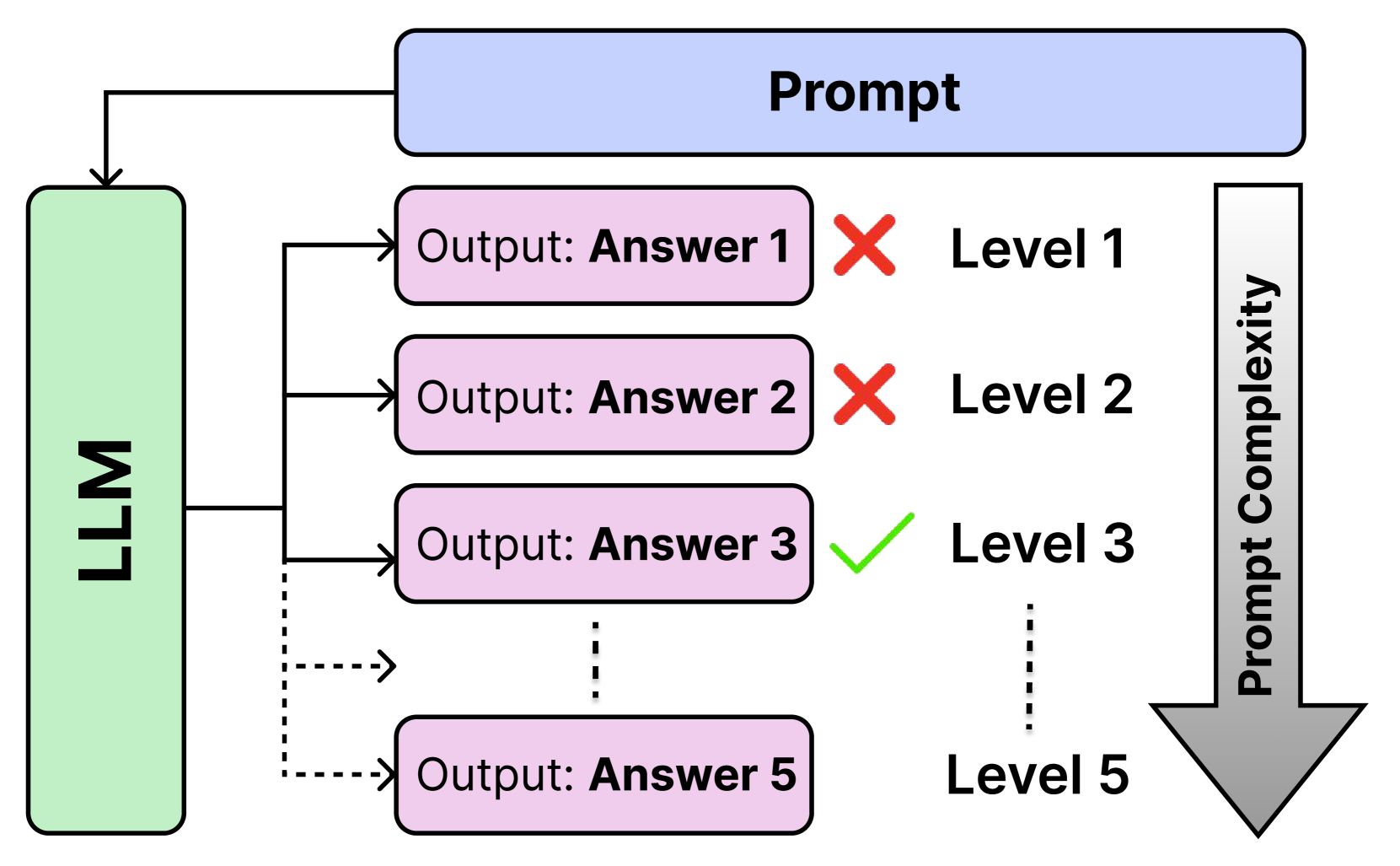
Hierarchical Prompting Taxonomy: A Universal Evaluation Framework for Large Language Models
Devichand Budagam, Sankalp KJ, Ashutosh Kumar, Vinija Jain, Aman Chadha
0
0
Assessing the effectiveness of large language models (LLMs) in addressing diverse tasks is essential for comprehending their strengths and weaknesses. Conventional evaluation techniques typically apply a single prompting strategy uniformly across datasets, not considering the varying degrees of task complexity. We introduce the Hierarchical Prompting Taxonomy (HPT), a taxonomy that employs a Hierarchical Prompt Framework (HPF) composed of five unique prompting strategies, arranged from the simplest to the most complex, to assess LLMs more precisely and to offer a clearer perspective. This taxonomy assigns a score, called the Hierarchical Prompting Score (HP-Score), to datasets as well as LLMs based on the rules of the taxonomy, providing a nuanced understanding of their ability to solve diverse tasks and offering a universal measure of task complexity. Additionally, we introduce the Adaptive Hierarchical Prompt framework, which automates the selection of appropriate prompting strategies for each task. This study compares manual and adaptive hierarchical prompt frameworks using four instruction-tuned LLMs, namely Llama 3 8B, Phi 3 3.8B, Mistral 7B, and Gemma 7B, across four datasets: BoolQ, CommonSenseQA (CSQA), IWSLT-2017 en-fr (IWSLT), and SamSum. Experiments demonstrate the effectiveness of HPT, providing a reliable way to compare different tasks and LLM capabilities. This paper leads to the development of a universal evaluation metric that can be used to evaluate both the complexity of the datasets and the capabilities of LLMs. The implementation of both manual HPF and adaptive HPF is publicly available.
6/28/2024