Semantically Aligned Question and Code Generation for Automated Insight Generation

0
🛸
Sign in to get full access
Overview
- This paper explores the challenge of automated insight generation, where large language models can produce code that does not accurately correspond to the intended insights.
- The researchers leverage the semantic knowledge of large language models to generate targeted and insightful questions about data, as well as the corresponding code to answer those questions.
- An empirical study on data from Open-WikiTable demonstrates that embeddings can effectively filter out semantically unaligned pairs of questions and code.
- The researchers also found that generating questions and code together yields more diverse questions.
Plain English Explanation
Large language models are often used to automatically generate insights from new and unfamiliar data, helping knowledge workers like data scientists quickly understand the potential value of this data. However, the code produced by these models does not always correctly match the intended insights.
To address this, the researchers in this paper used the semantic knowledge of large language models to generate specific questions about data, along with the code needed to answer those questions. They tested this approach on data from Open-WikiTable and found that using embeddings (mathematical representations of the semantic meaning) could effectively identify question-code pairs that were not well-aligned.
Additionally, the researchers discovered that generating both the questions and code together resulted in a more diverse set of questions being produced. This suggests that this approach could be a useful tool for helping knowledge workers gain deeper insights from their data.
Technical Explanation
The key elements of this paper are:
-
Insight Generation Approach: The researchers leveraged the semantic knowledge of large language models to generate targeted questions about data, as well as the corresponding code to answer those questions. This was done to address the challenge of automated insights produced by language models not always aligning correctly with the intended insights.
-
Empirical Study: The researchers conducted an empirical study using data from the Open-WikiTable dataset. They demonstrated that embeddings (numeric representations of the semantic meaning) could be effectively used to filter out question-code pairs that were not semantically aligned.
-
Diverse Question Generation: The researchers found that generating the questions and code together, rather than separately, resulted in a more diverse set of questions being produced. This suggests that their approach could be a valuable tool for helping knowledge workers gain deeper insights from their data.
Critical Analysis
The paper acknowledges some key limitations and areas for further research. Specifically:
- The researchers only tested their approach on the Open-WikiTable dataset, so it's unclear how well it would generalize to other types of data.
- The paper does not provide a detailed analysis of the specific types of misalignments between the generated insights and the corresponding code.
- There may be opportunities to further improve the diversity and relevance of the generated questions through additional techniques, such as enhancing question answering with enterprise knowledge bases or improving the capabilities of large language models for marketing tasks.
Overall, this research represents an important step towards addressing the challenge of automatically generating insights that are well-aligned with the underlying data and code. However, there is still work to be done to fully realize the potential of retrieval-augmented generation for domain-specific question answering and aligning knowledge graphs provided by humans with those generated by models.
Conclusion
This paper explores a novel approach to automated insight generation that leverages the semantic knowledge of large language models to generate targeted questions and corresponding code. The researchers demonstrated the effectiveness of using embeddings to filter out semantically unaligned question-code pairs, and found that generating questions and code together yields more diverse questions.
This research represents an important step towards improving the reliability and usefulness of automated insight generation, which has significant implications for knowledge workers like data scientists who rely on these tools to quickly understand the value of new data. By generating insightful questions and the corresponding code, this approach could help these workers gain deeper and more meaningful insights from their data, ultimately leading to better-informed decisions and more impactful outcomes.
Furthermore, the researchers' findings on the diversity of generated questions suggest that this approach could also be valuable for generating multilingual question-answering datasets, which are crucial for developing robust natural language processing systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
Semantically Aligned Question and Code Generation for Automated Insight Generation
Ananya Singha, Bhavya Chopra, Anirudh Khatry, Sumit Gulwani, Austin Z. Henley, Vu Le, Chris Parnin, Mukul Singh, Gust Verbruggen
Automated insight generation is a common tactic for helping knowledge workers, such as data scientists, to quickly understand the potential value of new and unfamiliar data. Unfortunately, automated insights produced by large-language models can generate code that does not correctly correspond (or align) to the insight. In this paper, we leverage the semantic knowledge of large language models to generate targeted and insightful questions about data and the corresponding code to answer those questions. Then through an empirical study on data from Open-WikiTable, we show that embeddings can be effectively used for filtering out semantically unaligned pairs of question and code. Additionally, we found that generating questions and code together yields more diverse questions.
Read more5/6/2024
0
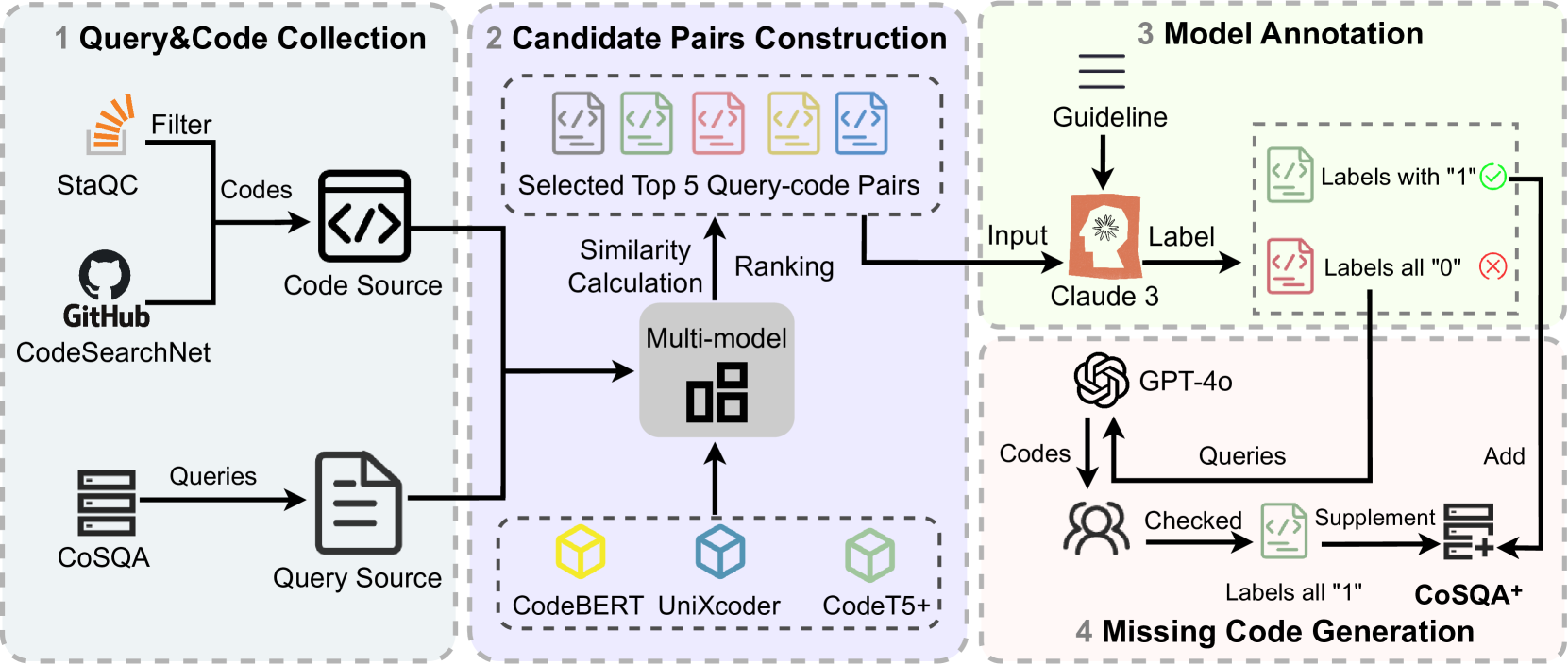
CoSQA+: Enhancing Code Search Dataset with Matching Code
Jing Gong, Yanghui Wu, Linxi Liang, Zibin Zheng, Yanlin Wang
Semantic code search, retrieving code that matches a given natural language query, is an important task to improve productivity in software engineering. Existing code search datasets are problematic: either using unrealistic queries, or with mismatched codes, and typically using one-to-one query-code pairing, which fails to reflect the reality that a query might have multiple valid code matches. This paper introduces CoSQA+, pairing high-quality queries (reused from CoSQA) with multiple suitable codes. We collect code candidates from diverse sources and form candidate pairs by pairing queries with these codes. Utilizing the power of large language models (LLMs), we automate pair annotation, filtering, and code generation for queries without suitable matches. Through extensive experiments, CoSQA+ has demonstrated superior quality over CoSQA. Models trained on CoSQA+ exhibit improved performance. Furthermore, we propose a new metric Mean Multi-choice Reciprocal Rank (MMRR), to assess one-to-N code search performance. We provide the code and data at https://github.com/DeepSoftwareAnalytics/CoSQA_Plus.
Read more8/27/2024
🌀
0
Chain of Targeted Verification Questions to Improve the Reliability of Code Generated by LLMs
Sylvain Kouemo Ngassom, Arghavan Moradi Dakhel, Florian Tambon, Foutse Khomh
LLM-based assistants, such as GitHub Copilot and ChatGPT, have the potential to generate code that fulfills a programming task described in a natural language description, referred to as a prompt. The widespread accessibility of these assistants enables users with diverse backgrounds to generate code and integrate it into software projects. However, studies show that code generated by LLMs is prone to bugs and may miss various corner cases in task specifications. Presenting such buggy code to users can impact their reliability and trust in LLM-based assistants. Moreover, significant efforts are required by the user to detect and repair any bug present in the code, especially if no test cases are available. In this study, we propose a self-refinement method aimed at improving the reliability of code generated by LLMs by minimizing the number of bugs before execution, without human intervention, and in the absence of test cases. Our approach is based on targeted Verification Questions (VQs) to identify potential bugs within the initial code. These VQs target various nodes within the Abstract Syntax Tree (AST) of the initial code, which have the potential to trigger specific types of bug patterns commonly found in LLM-generated code. Finally, our method attempts to repair these potential bugs by re-prompting the LLM with the targeted VQs and the initial code. Our evaluation, based on programming tasks in the CoderEval dataset, demonstrates that our proposed method outperforms state-of-the-art methods by decreasing the number of targeted errors in the code between 21% to 62% and improving the number of executable code instances to 13%.
Read more5/24/2024
💬
0
Improving the Capabilities of Large Language Model Based Marketing Analytics Copilots With Semantic Search And Fine-Tuning
Yilin Gao, Sai Kumar Arava, Yancheng Li, James W. Snyder Jr
Artificial intelligence (AI) is widely deployed to solve problems related to marketing attribution and budget optimization. However, AI models can be quite complex, and it can be difficult to understand model workings and insights without extensive implementation teams. In principle, recently developed large language models (LLMs), like GPT-4, can be deployed to provide marketing insights, reducing the time and effort required to make critical decisions. In practice, there are substantial challenges that need to be overcome to reliably use such models. We focus on domain-specific question-answering, SQL generation needed for data retrieval, and tabular analysis and show how a combination of semantic search, prompt engineering, and fine-tuning can be applied to dramatically improve the ability of LLMs to execute these tasks accurately. We compare both proprietary models, like GPT-4, and open-source models, like Llama-2-70b, as well as various embedding methods. These models are tested on sample use cases specific to marketing mix modeling and attribution.
Read more4/23/2024