Semantically Diverse Language Generation for Uncertainty Estimation in Language Models

1

Sign in to get full access
Overview
- This paper presents a method for generating semantically diverse language to better estimate predictive uncertainty in large language models.
- The key idea is to generate multiple diverse output samples per input, which can then be analyzed to quantify the model's confidence and uncertainty.
- The authors demonstrate their approach on language generation tasks and show it outperforms existing uncertainty estimation techniques.
Plain English Explanation
Large language models like GPT-3 are powerful tools that can generate human-like text on a wide range of topics. However, these models can sometimes be overconfident and produce biased or unreliable outputs, which can be problematic in high-stakes applications.
To address this issue, the researchers in this paper developed a new technique to better measure the uncertainty in a language model's predictions. The core idea is to generate multiple plausible text outputs for a given input, rather than just a single output. By analyzing the diversity and consistency of these multiple outputs, the model can get a better sense of how confident it is in its predictions.
For example, if the model generates several very similar outputs for an input, that suggests it is quite confident in its prediction. But if the outputs are very different from each other, that indicates the model is more uncertain. This uncertainty information can then be used to calibrate the model's outputs and improve its reliability.
The authors tested their approach on language generation tasks like summarization and dialogue, and showed it outperformed existing methods for estimating model uncertainty. This work is an important step towards building more robust and trustworthy language AI systems.
Technical Explanation
The key contribution of this paper is a novel method for measuring predictive uncertainty in natural language generation (NLG) models. The authors argue that existing approaches, which typically rely on a single model output, can fail to capture the full extent of a model's uncertainty.
To address this, the authors propose a "semantically diverse language generation" (SDLG) framework. The core idea is to generate multiple diverse output samples per input, rather than a single output. These diverse samples can then be analyzed to quantify the model's confidence and uncertainty.
Specifically, the SDLG framework consists of three main components:
-
Diverse Latent Sampling: The model first generates a set of diverse latent representations, from which the final text outputs are derived. This is achieved using techniques like iterative refinement and diverse beam search.
-
Uncertainty Estimation: The diversity of the generated text outputs is then used to estimate the model's uncertainty. Metrics like perplexity and output variance are computed across the samples to quantify the model's confidence.
-
Uncertainty-Aware Decoding: Finally, the estimated uncertainty can be used to improve the model's outputs, for example by favoring more confident predictions or providing calibrated uncertainty estimates.
The authors evaluate their SDLG framework on language generation tasks like summarization and dialogue, and demonstrate that it outperforms existing uncertainty estimation techniques. They show that the generated diverse samples better capture the model's uncertainty, leading to more reliable and trustworthy outputs.
Critical Analysis
The SDLG framework proposed in this paper is a promising approach for improving uncertainty estimation in language models. By generating multiple diverse outputs, the model can better quantify its confidence and avoid overconfident or biased predictions.
However, the authors acknowledge several limitations and caveats to their work. For example, the diverse sampling process can be computationally expensive, and the optimal way to balance diversity and quality of the generated outputs is an open research question. Additionally, the metrics used to estimate uncertainty may not fully capture all aspects of a model's uncertainties, such as systematic biases or out-of-distribution failures.
Another potential concern is the impact of this approach on the hallucination problem in language models, where models generate plausible-sounding but factually incorrect text. The diverse sampling process could potentially exacerbate this issue by producing a wider range of potentially hallucinated outputs.
Further research is needed to address these challenges and fully understand the practical implications of the SDLG framework. Approaches for detecting and mitigating hallucinations in language models, as well as more robust methods for uncertainty quantification, will be important areas of focus going forward.
Conclusion
This paper presents a novel approach for improving uncertainty estimation in large language models. By generating multiple diverse text outputs per input, the SDLG framework can better capture the model's confidence and uncertainty, leading to more reliable and trustworthy predictions.
While the proposed method shows promising results, there are still important challenges and limitations that need to be addressed. Ongoing research on hallucination detection, robust uncertainty quantification, and the practical deployment of these techniques will be crucial for realizing the full potential of this work.
Overall, this paper represents an important step towards building more transparent and accountable language AI systems, which will be increasingly important as these models become more widely adopted in high-stakes applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
Semantically Diverse Language Generation for Uncertainty Estimation in Language Models
Lukas Aichberger, Kajetan Schweighofer, Mykyta Ielanskyi, Sepp Hochreiter
Large language models (LLMs) can suffer from hallucinations when generating text. These hallucinations impede various applications in society and industry by making LLMs untrustworthy. Current LLMs generate text in an autoregressive fashion by predicting and appending text tokens. When an LLM is uncertain about the semantic meaning of the next tokens to generate, it is likely to start hallucinating. Thus, it has been suggested that hallucinations stem from predictive uncertainty. We introduce Semantically Diverse Language Generation (SDLG) to quantify predictive uncertainty in LLMs. SDLG steers the LLM to generate semantically diverse yet likely alternatives for an initially generated text. This approach provides a precise measure of aleatoric semantic uncertainty, detecting whether the initial text is likely to be hallucinated. Experiments on question-answering tasks demonstrate that SDLG consistently outperforms existing methods while being the most computationally efficient, setting a new standard for uncertainty estimation in LLMs.
Read more6/7/2024

0
Alleviating Hallucinations in Large Language Models with Scepticism Modeling
Yetao Wu, Yihong Wang, Teng Chen, Chenxi Liu, Ningyuan Xi, Qingqing Gu, Hongyang Lei, Zhonglin Jiang, Yong Chen, Luo Ji
Hallucinations is a major challenge for large language models (LLMs), prevents adoption in diverse fields. Uncertainty estimation could be used for alleviating the damages of hallucinations. The skeptical emotion of human could be useful for enhancing the ability of self estimation. Inspirited by this observation, we proposed a new approach called Skepticism Modeling (SM). This approach is formalized by combining the information of token and logits for self estimation. We construct the doubt emotion aware data, perform continual pre-training, and then fine-tune the LLMs, improve their ability of self estimation. Experimental results demonstrate this new approach effectively enhances a model's ability to estimate their uncertainty, and validate its generalization ability of other tasks by out-of-domain experiments.
Read more9/11/2024
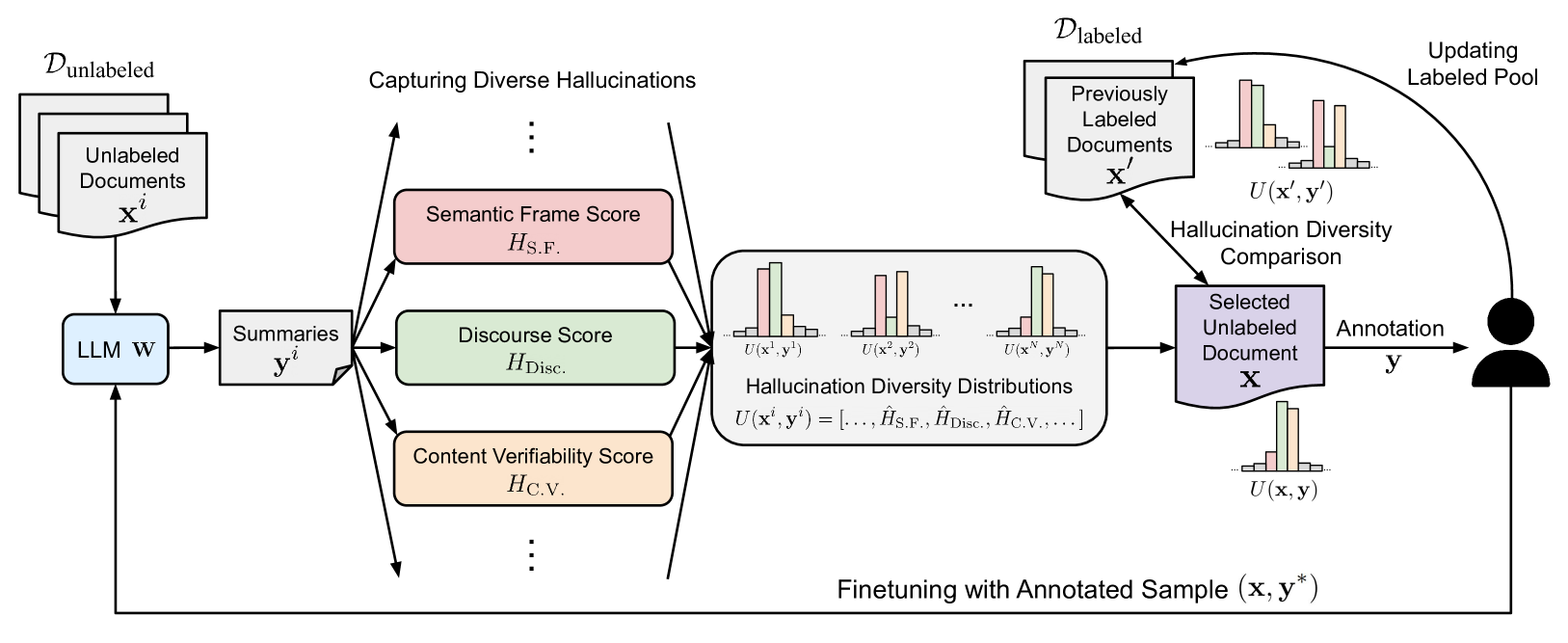
0
Hallucination Diversity-Aware Active Learning for Text Summarization
Yu Xia, Xu Liu, Tong Yu, Sungchul Kim, Ryan A. Rossi, Anup Rao, Tung Mai, Shuai Li
Large Language Models (LLMs) have shown propensity to generate hallucinated outputs, i.e., texts that are factually incorrect or unsupported. Existing methods for alleviating hallucinations typically require costly human annotations to identify and correct hallucinations in LLM outputs. Moreover, most of these methods focus on a specific type of hallucination, e.g., entity or token errors, which limits their effectiveness in addressing various types of hallucinations exhibited in LLM outputs. To our best knowledge, in this paper we propose the first active learning framework to alleviate LLM hallucinations, reducing costly human annotations of hallucination needed. By measuring fine-grained hallucinations from errors in semantic frame, discourse and content verifiability in text summarization, we propose HAllucination Diversity-Aware Sampling (HADAS) to select diverse hallucinations for annotations in active learning for LLM finetuning. Extensive experiments on three datasets and different backbone models demonstrate advantages of our method in effectively and efficiently mitigating LLM hallucinations.
Read more4/3/2024

0
UHGEval: Benchmarking the Hallucination of Chinese Large Language Models via Unconstrained Generation
Xun Liang, Shichao Song, Simin Niu, Zhiyu Li, Feiyu Xiong, Bo Tang, Yezhaohui Wang, Dawei He, Peng Cheng, Zhonghao Wang, Haiying Deng
Large language models (LLMs) have emerged as pivotal contributors in contemporary natural language processing and are increasingly being applied across a diverse range of industries. However, these large-scale probabilistic statistical models cannot currently ensure the requisite quality in professional content generation. These models often produce hallucinated text, compromising their practical utility in professional contexts. To assess the authentic reliability of LLMs in text generation, numerous initiatives have developed benchmark evaluations for hallucination phenomena. Nevertheless, these benchmarks frequently utilize constrained generation techniques due to cost and temporal constraints. These techniques encompass the use of directed hallucination induction and strategies that deliberately alter authentic text to produce hallucinations. These approaches are not congruent with the unrestricted text generation demanded by real-world applications. Furthermore, a well-established Chinese-language dataset dedicated to the evaluation of hallucinations in text generation is presently lacking. Consequently, we have developed an Unconstrained Hallucination Generation Evaluation (UHGEval) benchmark, designed to compile outputs produced with minimal restrictions by LLMs. Concurrently, we have established a comprehensive benchmark evaluation framework to aid subsequent researchers in undertaking scalable and reproducible experiments. We have also executed extensive experiments, evaluating prominent Chinese language models and the GPT series models to derive professional performance insights regarding hallucination challenges.
Read more5/27/2024