UHGEval: Benchmarking the Hallucination of Chinese Large Language Models via Unconstrained Generation
2311.15296
0
0

Abstract
Large language models (LLMs) have emerged as pivotal contributors in contemporary natural language processing and are increasingly being applied across a diverse range of industries. However, these large-scale probabilistic statistical models cannot currently ensure the requisite quality in professional content generation. These models often produce hallucinated text, compromising their practical utility in professional contexts. To assess the authentic reliability of LLMs in text generation, numerous initiatives have developed benchmark evaluations for hallucination phenomena. Nevertheless, these benchmarks frequently utilize constrained generation techniques due to cost and temporal constraints. These techniques encompass the use of directed hallucination induction and strategies that deliberately alter authentic text to produce hallucinations. These approaches are not congruent with the unrestricted text generation demanded by real-world applications. Furthermore, a well-established Chinese-language dataset dedicated to the evaluation of hallucinations in text generation is presently lacking. Consequently, we have developed an Unconstrained Hallucination Generation Evaluation (UHGEval) benchmark, designed to compile outputs produced with minimal restrictions by LLMs. Concurrently, we have established a comprehensive benchmark evaluation framework to aid subsequent researchers in undertaking scalable and reproducible experiments. We have also executed extensive experiments, evaluating prominent Chinese language models and the GPT series models to derive professional performance insights regarding hallucination challenges.
Create account to get full access
Overview
- This paper introduces a new benchmark dataset called UHGEval for evaluating the hallucination of Chinese large language models (LLMs) through unconstrained generation.
- Hallucination refers to the tendency of LLMs to generate plausible-sounding but factually incorrect text.
- The UHGEval dataset aims to provide a comprehensive and challenging benchmark for assessing the hallucination capabilities of Chinese LLMs.
Plain English Explanation
The paper presents a new benchmark dataset called UHGEval that is designed to test how well Chinese large language models can avoid hallucinating - that is, generating text that sounds plausible but is actually factually incorrect. Hallucination is a common issue with these powerful language models, and the researchers created UHGEval to provide a thorough way to measure this problem in the context of Chinese language models.
The key idea is to give the models completely open-ended prompts and see what kind of text they generate. By analyzing the accuracy and truthfulness of the generated output, the benchmark can assess how prone the models are to hallucinating. This is an important issue to study, as language models are increasingly being used for tasks like question answering and content creation, where it's crucial that the output be factually correct.
Technical Explanation
The paper introduces the UHGEval benchmark, which is designed to evaluate the hallucination capabilities of Chinese large language models through unconstrained generation tasks. Hallucination refers to the tendency of LLMs to generate plausible-sounding but factually incorrect text.
To create UHGEval, the researchers curated a dataset of open-ended prompts covering a wide range of topics. These prompts do not have a single correct answer, allowing the models to freely generate responses. The benchmark then assesses the generated text for accuracy, coherence, and truthfulness using both automated metrics and human evaluation.
The paper evaluates several state-of-the-art Chinese LLMs on the UHGEval benchmark and provides insights into their hallucination behaviors. The results show that even the most advanced models still struggle with hallucination to a significant degree, highlighting the need for continued research and improvement in this area.
Critical Analysis
The UHGEval benchmark represents an important step forward in evaluating hallucinations in language models. By focusing on unconstrained generation, the dataset provides a more comprehensive and challenging test of a model's tendency to hallucinate compared to traditional benchmarks.
However, the paper acknowledges several limitations of the current UHGEval dataset and evaluation methodology. For example, the prompts are still relatively narrow in scope, and the human evaluation process can be subjective and labor-intensive. Additionally, the paper does not delve into the specific factors that contribute to hallucination in the tested models, limiting the insights that can be drawn.
Further research is needed to expand the UHGEval dataset, refine the evaluation techniques, and better understand the underlying mechanisms of hallucination in large language models. Ultimately, addressing the hallucination problem is crucial for the safe and reliable deployment of these powerful language models in real-world applications.
Conclusion
The UHGEval benchmark introduced in this paper represents a significant advancement in evaluating the hallucination capabilities of Chinese large language models. By focusing on unconstrained generation, the dataset provides a more comprehensive and realistic test of a model's tendency to produce factually incorrect but plausible-sounding text.
The results of the benchmark highlight the continued challenges in addressing hallucination, even for state-of-the-art models. This underscores the importance of continued research and development in this area to ensure the safe and reliable deployment of language models in high-stakes applications.
Overall, the UHGEval benchmark and the insights from this paper contribute valuable tools and knowledge to the ongoing effort to understand and mitigate the hallucination problem in large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
HaluEval-Wild: Evaluating Hallucinations of Language Models in the Wild
Zhiying Zhu, Yiming Yang, Zhiqing Sun
0
0
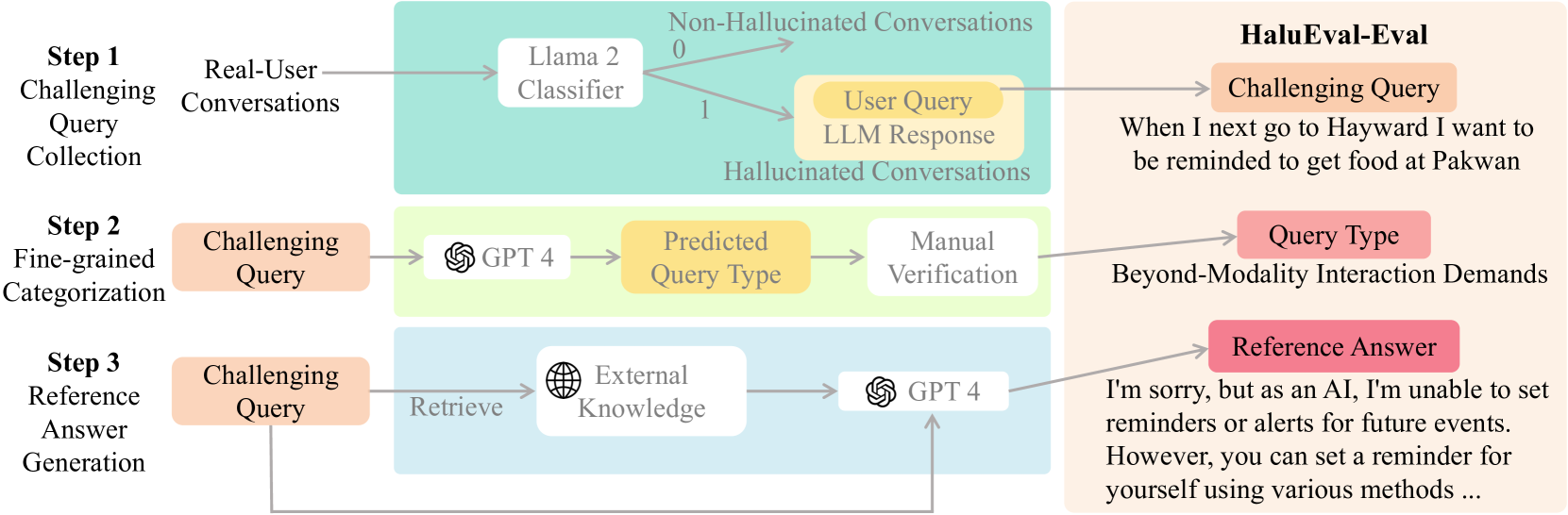
Hallucinations pose a significant challenge to the reliability of large language models (LLMs) in critical domains. Recent benchmarks designed to assess LLM hallucinations within conventional NLP tasks, such as knowledge-intensive question answering (QA) and summarization, are insufficient for capturing the complexities of user-LLM interactions in dynamic, real-world settings. To address this gap, we introduce HaluEval-Wild, the first benchmark specifically designed to evaluate LLM hallucinations in the wild. We meticulously collect challenging (adversarially filtered by Alpaca) user queries from existing real-world user-LLM interaction datasets, including ShareGPT, to evaluate the hallucination rates of various LLMs. Upon analyzing the collected queries, we categorize them into five distinct types, which enables a fine-grained analysis of the types of hallucinations LLMs exhibit, and synthesize the reference answers with the powerful GPT-4 model and retrieval-augmented generation (RAG). Our benchmark offers a novel approach towards enhancing our comprehension and improvement of LLM reliability in scenarios reflective of real-world interactions. Our benchmark is available at https://github.com/Dianezzy/HaluEval-Wild.
5/7/2024

A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, Wei Peng
0
0
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
5/7/2024
💬
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, Mike Zheng Shou
0
0
This survey presents a comprehensive analysis of the phenomenon of hallucination in multimodal large language models (MLLMs), also known as Large Vision-Language Models (LVLMs), which have demonstrated significant advancements and remarkable abilities in multimodal tasks. Despite these promising developments, MLLMs often generate outputs that are inconsistent with the visual content, a challenge known as hallucination, which poses substantial obstacles to their practical deployment and raises concerns regarding their reliability in real-world applications. This problem has attracted increasing attention, prompting efforts to detect and mitigate such inaccuracies. We review recent advances in identifying, evaluating, and mitigating these hallucinations, offering a detailed overview of the underlying causes, evaluation benchmarks, metrics, and strategies developed to address this issue. Additionally, we analyze the current challenges and limitations, formulating open questions that delineate potential pathways for future research. By drawing the granular classification and landscapes of hallucination causes, evaluation benchmarks, and mitigation methods, this survey aims to deepen the understanding of hallucinations in MLLMs and inspire further advancements in the field. Through our thorough and in-depth review, we contribute to the ongoing dialogue on enhancing the robustness and reliability of MLLMs, providing valuable insights and resources for researchers and practitioners alike. Resources are available at: https://github.com/showlab/Awesome-MLLM-Hallucination.
4/30/2024
🔎
Unified Hallucination Detection for Multimodal Large Language Models
Xiang Chen, Chenxi Wang, Yida Xue, Ningyu Zhang, Xiaoyan Yang, Qiang Li, Yue Shen, Lei Liang, Jinjie Gu, Huajun Chen
0
0
Despite significant strides in multimodal tasks, Multimodal Large Language Models (MLLMs) are plagued by the critical issue of hallucination. The reliable detection of such hallucinations in MLLMs has, therefore, become a vital aspect of model evaluation and the safeguarding of practical application deployment. Prior research in this domain has been constrained by a narrow focus on singular tasks, an inadequate range of hallucination categories addressed, and a lack of detailed granularity. In response to these challenges, our work expands the investigative horizons of hallucination detection. We present a novel meta-evaluation benchmark, MHaluBench, meticulously crafted to facilitate the evaluation of advancements in hallucination detection methods. Additionally, we unveil a novel unified multimodal hallucination detection framework, UNIHD, which leverages a suite of auxiliary tools to validate the occurrence of hallucinations robustly. We demonstrate the effectiveness of UNIHD through meticulous evaluation and comprehensive analysis. We also provide strategic insights on the application of specific tools for addressing various categories of hallucinations.
5/28/2024