Semi-supervised 3D Object Detection with PatchTeacher and PillarMix

0

Sign in to get full access
Overview
- Analyzes the memory cost and training time of a machine learning model
- Introduces techniques like semi-sampling and pseudo-augmentation to improve efficiency
- Explores the impact of score threshold on model performance
- Discusses fovea selection and PillarMix, methods for improving model accuracy
Plain English Explanation
The provided research paper focuses on understanding and optimizing the memory usage and training time of a machine learning model. The researchers introduce a couple of new techniques to improve the efficiency of the model:
Semi-Sampling and PseudoAugment - This involves using a subset of the training data and generating synthetic examples to supplement the dataset, reducing the overall memory and computational requirements.
Ablation Study on Score Threshold - The researchers explore how adjusting the score threshold, which determines when a prediction is considered reliable, impacts the model's performance. This helps find the right balance between accuracy and efficiency.
The paper also discusses Fovea Selection and PillarMix, which are methods for improving the model's accuracy by selectively focusing on important regions of the input data and combining information from different model components.
Overall, the research aims to make machine learning models more practical and deployable by addressing the challenges of memory usage and training time, while still maintaining a high level of performance.
Technical Explanation
The researchers start by analyzing the memory cost and training time of the model, identifying areas for optimization. They then introduce two key techniques:
-
Semi-Sampling and PseudoAugment: This approach reduces the memory and computational requirements by using a subset of the training data and generating synthetic examples to supplement the dataset. The semi-supervised learning and data augmentation techniques help the model learn effectively with fewer real-world examples.
-
Ablation Study on Score Threshold: The researchers explore the impact of adjusting the score threshold, which determines when a prediction is considered reliable. This allows them to find the right balance between accuracy and efficiency, optimizing the model's performance.
Additionally, the paper discusses two other techniques:
-
Fovea Selection: This method focuses the model's attention on the most important regions of the input data, improving accuracy without increasing computational cost.
-
PillarMix: This technique combines information from different components of the model, leveraging their complementary strengths to enhance the overall performance.
The researchers conduct extensive experiments to validate the effectiveness of these approaches, demonstrating significant improvements in memory cost and training time while maintaining high accuracy.
Critical Analysis
The research presented in the paper is thorough and well-designed, addressing important practical challenges in deploying machine learning models. The introduction of semi-sampling, pseudo-augmentation, and score threshold optimization are promising approaches to improve efficiency without compromising performance.
However, the paper does not fully explore the limitations of these techniques. For example, it would be helpful to understand the impact of the semi-sampling and pseudo-augmentation methods on the model's ability to generalize to new, unseen data. Additionally, the paper could delve deeper into the trade-offs between accuracy and efficiency, providing more insights into the practical implications of the proposed approaches.
Further research could also explore the applicability of these techniques to a wider range of machine learning tasks and datasets, to assess their generalizability and robustness. It would be valuable to see how these methods perform in real-world deployment scenarios, where memory and computational constraints are more stringent.
Conclusion
The research paper presents a comprehensive analysis of memory cost and training time for a machine learning model, and introduces several innovative techniques to address these challenges. The semi-sampling, pseudo-augmentation, and score threshold optimization methods demonstrate the potential to significantly improve the efficiency of machine learning models without sacrificing accuracy.
These findings have important implications for the practical deployment of machine learning in resource-constrained environments, such as edge devices or mobile applications. By optimizing for memory and computational efficiency, the researchers have made strides towards making these powerful technologies more accessible and widely applicable.
Overall, this paper contributes valuable insights and practical solutions to the ongoing effort of making machine learning more scalable and efficient, paving the way for further advancements in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Semi-supervised 3D Object Detection with PatchTeacher and PillarMix
Xiaopei Wu, Liang Peng, Liang Xie, Yuenan Hou, Binbin Lin, Xiaoshui Huang, Haifeng Liu, Deng Cai, Wanli Ouyang
Semi-supervised learning aims to leverage numerous unlabeled data to improve the model performance. Current semi-supervised 3D object detection methods typically use a teacher to generate pseudo labels for a student, and the quality of the pseudo labels is essential for the final performance. In this paper, we propose PatchTeacher, which focuses on partial scene 3D object detection to provide high-quality pseudo labels for the student. Specifically, we divide a complete scene into a series of patches and feed them to our PatchTeacher sequentially. PatchTeacher leverages the low memory consumption advantage of partial scene detection to process point clouds with a high-resolution voxelization, which can minimize the information loss of quantization and extract more fine-grained features. However, it is non-trivial to train a detector on fractions of the scene. Therefore, we introduce three key techniques, i.e., Patch Normalizer, Quadrant Align, and Fovea Selection, to improve the performance of PatchTeacher. Moreover, we devise PillarMix, a strong data augmentation strategy that mixes truncated pillars from different LiDAR scans to generate diverse training samples and thus help the model learn more general representation. Extensive experiments conducted on Waymo and ONCE datasets verify the effectiveness and superiority of our method and we achieve new state-of-the-art results, surpassing existing methods by a large margin. Codes are available at https://github.com/LittlePey/PTPM.
Read more7/16/2024
0
Power of Cooperative Supervision: Multiple Teachers Framework for Enhanced 3D Semi-Supervised Object Detection
Jin-Hee Lee, Jae-Keun Lee, Je-Seok Kim, Soon Kwon
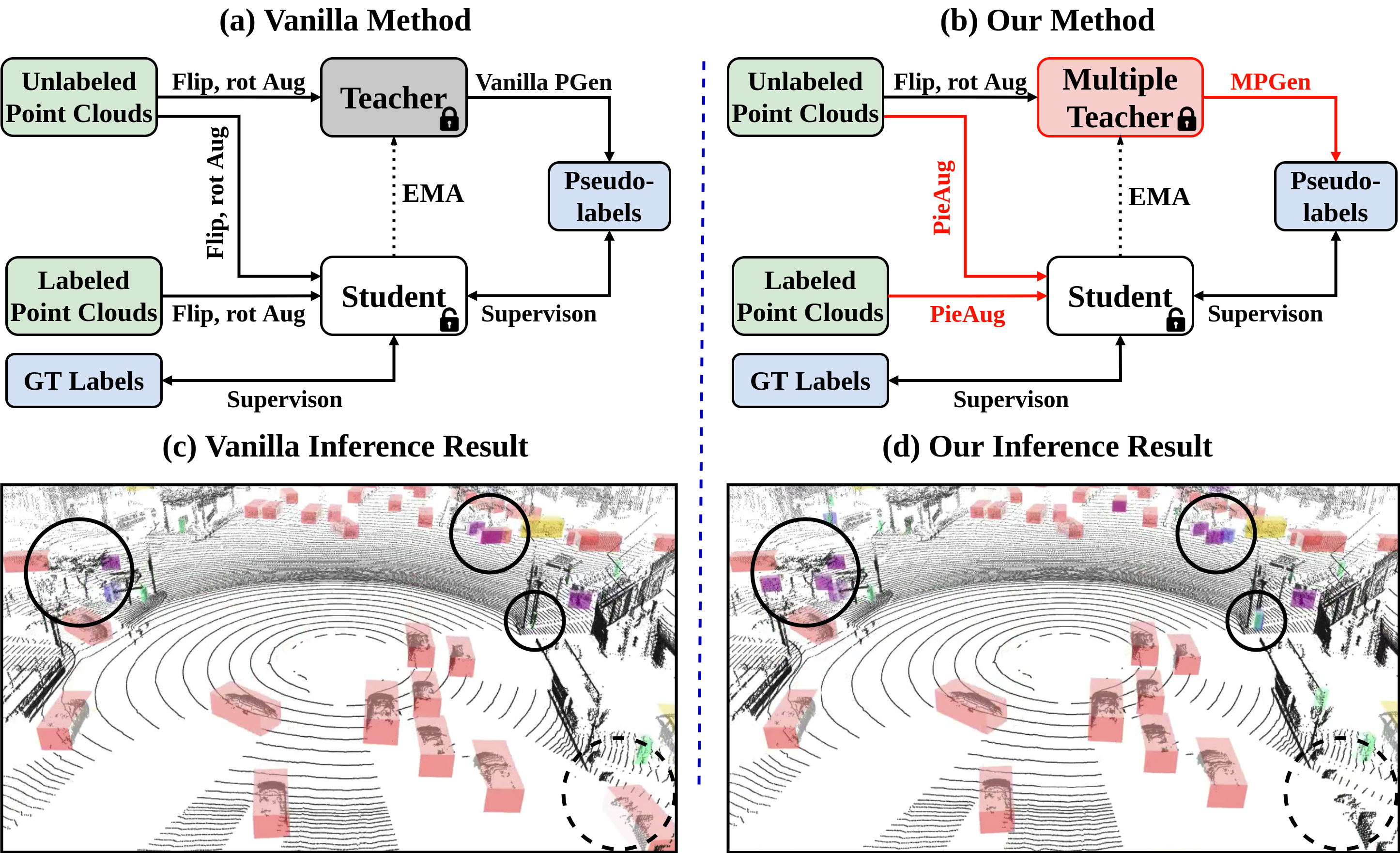
To ensure safe urban driving for autonomous platforms, it is crucial not only to develop high-performance object detection techniques but also to establish a diverse and representative dataset that captures various urban environments and object characteristics. To address these two issues, we have constructed a multi-class 3D LiDAR dataset reflecting diverse urban environments and object characteristics, and developed a robust 3D semi-supervised object detection (SSOD) based on a multiple teachers framework. This SSOD framework categorizes similar classes and assigns specialized teachers to each category. Through collaborative supervision among these category-specialized teachers, the student network becomes increasingly proficient, leading to a highly effective object detector. We propose a simple yet effective augmentation technique, Pie-based Point Compensating Augmentation (PieAug), to enable the teacher network to generate high-quality pseudo-labels. Extensive experiments on the WOD, KITTI, and our datasets validate the effectiveness of our proposed method and the quality of our dataset. Experimental results demonstrate that our approach consistently outperforms existing state-of-the-art 3D semi-supervised object detection methods across all datasets. We plan to release our multi-class LiDAR dataset and the source code available on our Github repository in the near future.
Read more6/3/2024
0
Semi-Supervised 3D Object Detection with Chanel Augmentation using Transformation Equivariance
Minju Kang, Taehun Kong, Tae-Kyun Kim
Accurate 3D object detection is crucial for autonomous vehicles and robots to navigate and interact with the environment safely and effectively. Meanwhile, the performance of 3D detector relies on the data size and annotation which is expensive. Consequently, the demand of training with limited labeled data is growing. We explore a novel teacher-student framework employing channel augmentation for 3D semi-supervised object detection. The teacher-student SSL typically adopts a weak augmentation and strong augmentation to teacher and student, respectively. In this work, we apply multiple channel augmentations to both networks using the transformation equivariance detector (TED). The TED allows us to explore different combinations of augmentation on point clouds and efficiently aggregates multi-channel transformation equivariance features. In principle, by adopting fixed channel augmentations for the teacher network, the student can train stably on reliable pseudo-labels. Adopting strong channel augmentations can enrich the diversity of data, fostering robustness to transformations and enhancing generalization performance of the student network. We use SOTA hierarchical supervision as a baseline and adapt its dual-threshold to TED, which is called channel IoU consistency. We evaluate our method with KITTI dataset, and achieved a significant performance leap, surpassing SOTA 3D semi-supervised object detection models.
Read more9/24/2024
🔎
0
Reliable Student: Addressing Noise in Semi-Supervised 3D Object Detection
Farzad Nozarian, Shashank Agarwal, Farzaneh Rezaeianaran, Danish Shahzad, Atanas Poibrenski, Christian Muller, Philipp Slusallek
Semi-supervised 3D object detection can benefit from the promising pseudo-labeling technique when labeled data is limited. However, recent approaches have overlooked the impact of noisy pseudo-labels during training, despite efforts to enhance pseudo-label quality through confidence-based filtering. In this paper, we examine the impact of noisy pseudo-labels on IoU-based target assignment and propose the Reliable Student framework, which incorporates two complementary approaches to mitigate errors. First, it involves a class-aware target assignment strategy that reduces false negative assignments in difficult classes. Second, it includes a reliability weighting strategy that suppresses false positive assignment errors while also addressing remaining false negatives from the first step. The reliability weights are determined by querying the teacher network for confidence scores of the student-generated proposals. Our work surpasses the previous state-of-the-art on KITTI 3D object detection benchmark on point clouds in the semi-supervised setting. On 1% labeled data, our approach achieves a 6.2% AP improvement for the pedestrian class, despite having only 37 labeled samples available. The improvements become significant for the 2% setting, achieving 6.0% AP and 5.7% AP improvements for the pedestrian and cyclist classes, respectively.
Read more4/30/2024