A sensitivity analysis to quantify the impact of neuroimaging preprocessing strategies on subsequent statistical analyses
2404.14882
0
0
🤔
Abstract
Even though novel imaging techniques have been successful in studying brain structure and function, the measured biological signals are often contaminated by multiple sources of noise, arising due to e.g. head movements of the individual being scanned, limited spatial/temporal resolution, or other issues specific to each imaging technology. Data preprocessing (e.g. denoising) is therefore critical. Preprocessing pipelines have become increasingly complex over the years, but also more flexible, and this flexibility can have a significant impact on the final results and conclusions of a given study. This large parameter space is often referred to as multiverse analyses. Here, we provide conceptual and practical tools for statistical analyses that can aggregate multiple pipeline results along with a new sensitivity analysis testing for hypotheses across pipelines such as no effect across all pipelines or at least one pipeline with no effect. The proposed framework is generic and can be applied to any multiverse scenario, but we illustrate its use based on positron emission tomography data.
Create account to get full access
Overview
- Novel imaging techniques have been successful in studying brain structure and function
- But the measured biological signals are often contaminated by various sources of noise
- Data preprocessing (e.g. denoising) is critical to address this issue
- Preprocessing pipelines have become more complex and flexible over time
- This flexibility can significantly impact the final results and conclusions of a study
- This paper provides tools for statistical analyses that can aggregate multiple pipeline results and test hypotheses across pipelines
Plain English Explanation
Researchers use advanced imaging techniques to study how the brain is structured and how it functions. However, the data they collect is often "noisy" - it contains unwanted signals that can distort the results. This noise can come from things like the person moving their head during the scan, or limitations of the imaging technology itself.
To address this issue, scientists perform "data preprocessing" - they use various techniques to clean up the data and remove the noise. Over time, these preprocessing pipelines have become increasingly complex and flexible. This flexibility is a double-edged sword - it allows researchers to explore the data in more depth, but it also means the final results can be heavily influenced by the specific choices made during preprocessing.
This paper introduces some new statistical tools that can help researchers navigate this "multiverse" of potential preprocessing pipelines. The tools allow them to aggregate the results across multiple pipelines and test whether there are consistent findings (or lack thereof) regardless of the specific choices made. The authors illustrate these techniques using positron emission tomography (PET) data, but the approach is designed to be generic and applicable to other imaging modalities as well.
Technical Explanation
The paper addresses the challenge of "multiverse analyses" in neuroimaging research. Neuroimaging data, such as that from positron emission tomography (PET) or functional magnetic resonance imaging (fMRI), is often contaminated by various sources of noise, such as head movements, limited spatial/temporal resolution, and other imaging-specific issues. Preprocessing pipelines to denoise and prepare the data have become increasingly complex and flexible over the years.
This flexibility in preprocessing can have a significant impact on the final results and conclusions of a study, leading to the "multiverse" problem - a large parameter space of potential analysis choices. The authors provide conceptual and practical tools for statistical analyses that can aggregate multiple pipeline results and test hypotheses across pipelines, such as the hypothesis of no effect across all pipelines or at least one pipeline with no effect.
The proposed framework is generic and can be applied to any multiverse scenario, but the authors illustrate its use based on PET data. By addressing the challenges of analytical variability in neuroimaging research, this work aims to improve the reliability and reproducibility of findings in the field.
Critical Analysis
The authors acknowledge several limitations and caveats in their approach. First, the proposed framework relies on the assumption that the different preprocessing pipelines represent a reasonable exploration of the multiverse, which may not always be the case in practice. Additionally, the sensitivity analysis assumes that the pipelines are independent, which may not hold true if they share common steps or assumptions.
Another potential issue is the computational burden of the proposed method, as it requires running multiple preprocessing pipelines and aggregating the results. This could be a significant challenge for large-scale neuroimaging studies or real-time applications.
Furthermore, the paper does not address the potential biases or systematic errors that may be introduced by the preprocessing steps themselves. While the framework can help mitigate the impact of these issues, it does not provide a solution for identifying or correcting them.
Finally, the authors note that the interpretation of the aggregated results across pipelines can be complex, and care must be taken to avoid oversimplifying or overgeneralizing the findings.
Conclusion
This paper presents a novel statistical framework for addressing the "multiverse" problem in neuroimaging research, where the flexibility of data preprocessing pipelines can significantly impact the final results and conclusions. By providing tools to aggregate multiple pipeline results and test hypotheses across pipelines, the authors aim to improve the reliability and reproducibility of findings in the field.
While the proposed approach has some limitations, it represents an important step forward in addressing a critical challenge in neuroimaging data analysis. As the complexity and flexibility of preprocessing pipelines continue to grow, tools like those described in this paper will become increasingly valuable for ensuring the integrity and transparency of neuroimaging research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
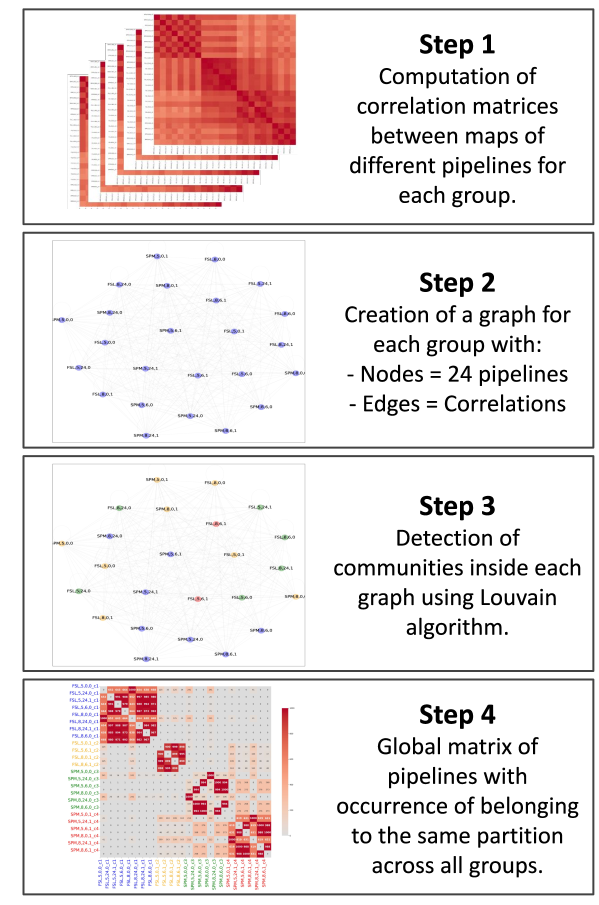
Uncovering communities of pipelines in the task-fMRI analytical space
Elodie Germani (EMPENN), Elisa Fromont (LACODAM), Camille Maumet (EMPENN)
0
0
Analytical workflows in functional magnetic resonance imaging are highly flexible with limited best practices as to how to choose a pipeline. While it has been shown that the use of different pipelines might lead to different results, there is still a lack of understanding of the factors that drive these differences and of the stability of these differences across contexts. We use community detection algorithms to explore the pipeline space and assess the stability of pipeline relationships across different contexts. We show that there are subsets of pipelines that give similar results, especially those sharing specific parameters (e.g. number of motion regressors, software packages, etc.). Those pipeline-to-pipeline patterns are stable across groups of participants but not across different tasks. By visualizing the differences between communities, we show that the pipeline space is mainly driven by the size of the activation area in the brain and the scale of statistic values in statistic maps.
6/19/2024
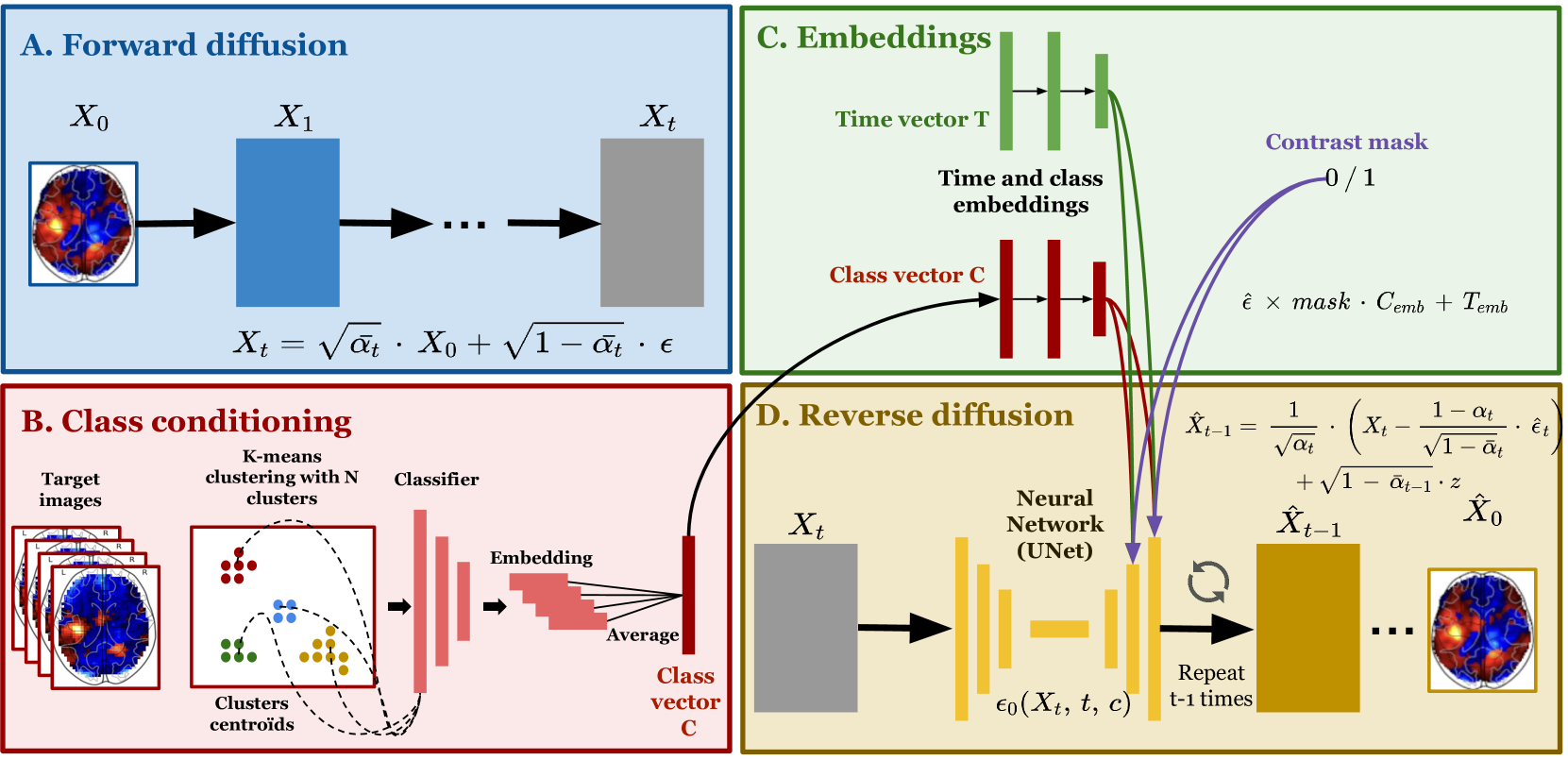
Mitigating analytical variability in fMRI results with style transfer
Elodie Germani (EMPENN, LACODAM), Elisa Fromont (LACODAM), Camille Maumet (EMPENN)
0
0
We propose a novel approach to improve the reproducibility of neuroimaging results by converting statistic maps across different functional MRI pipelines. We make the assumption that pipelines can be considered as a style component of data and propose to use different generative models, among which, Diffusion Models (DM) to convert data between pipelines. We design a new DM-based unsupervised multi-domain image-to-image transition framework and constrain the generation of 3D fMRI statistic maps using the latent space of an auxiliary classifier that distinguishes statistic maps from different pipelines. We extend traditional sampling techniques used in DM to improve the transition performance. Our experiments demonstrate that our proposed methods are successful: pipelines can indeed be transferred, providing an important source of data augmentation for future medical studies.
4/8/2024

Provable Privacy with Non-Private Pre-Processing
Yaxi Hu, Amartya Sanyal, Bernhard Scholkopf
0
0
When analysing Differentially Private (DP) machine learning pipelines, the potential privacy cost of data-dependent pre-processing is frequently overlooked in privacy accounting. In this work, we propose a general framework to evaluate the additional privacy cost incurred by non-private data-dependent pre-processing algorithms. Our framework establishes upper bounds on the overall privacy guarantees by utilising two new technical notions: a variant of DP termed Smooth DP and the bounded sensitivity of the pre-processing algorithms. In addition to the generic framework, we provide explicit overall privacy guarantees for multiple data-dependent pre-processing algorithms, such as data imputation, quantization, deduplication and PCA, when used in combination with several DP algorithms. Notably, this framework is also simple to implement, allowing direct integration into existing DP pipelines.
6/24/2024
🧠
A Neural Framework for Generalized Causal Sensitivity Analysis
Dennis Frauen, Fergus Imrie, Alicia Curth, Valentyn Melnychuk, Stefan Feuerriegel, Mihaela van der Schaar
0
0
Unobserved confounding is common in many applications, making causal inference from observational data challenging. As a remedy, causal sensitivity analysis is an important tool to draw causal conclusions under unobserved confounding with mathematical guarantees. In this paper, we propose NeuralCSA, a neural framework for generalized causal sensitivity analysis. Unlike previous work, our framework is compatible with (i) a large class of sensitivity models, including the marginal sensitivity model, f-sensitivity models, and Rosenbaum's sensitivity model; (ii) different treatment types (i.e., binary and continuous); and (iii) different causal queries, including (conditional) average treatment effects and simultaneous effects on multiple outcomes. The generality of NeuralCSA is achieved by learning a latent distribution shift that corresponds to a treatment intervention using two conditional normalizing flows. We provide theoretical guarantees that NeuralCSA is able to infer valid bounds on the causal query of interest and also demonstrate this empirically using both simulated and real-world data.
4/10/2024