Sequential Bayesian Neural Subnetwork Ensembles

0
📶
Sign in to get full access
Overview
- Deep ensembles are a powerful technique for improving predictive performance and model robustness.
- Traditional deep ensemble methods are computationally expensive and rely on deterministic models, limiting their flexibility.
- Sparse subnetworks of dense models have shown promise in matching performance and enhancing robustness, but existing methods for inducing sparsity incur high training costs.
Plain English Explanation
Deep ensembles are a way of combining multiple machine learning models to get better predictions and more reliable results. This is useful in a variety of applications. However, the traditional methods for creating deep ensembles can be very computationally intensive and rely on models that always give the same output for the same input.
Another approach that has shown promise is to use sparse subnetworks - smaller, more efficient versions of the original machine learning models. But the current methods for creating these sparse subnetworks still require a lot of training time, comparable to training a full-size model.
Technical Explanation
To address these challenges, the researchers propose an approach for sequentially ensembling dynamic Bayesian neural subnetworks. This method consistently maintains reduced model complexity throughout training while generating diverse ensembles in a single forward pass.
The approach involves an initial exploration phase to identify high-performing regions of the parameter space, followed by multiple exploitation phases that quickly converge to different minima in the energy landscape. This corresponds to finding multiple high-performing subnetworks that together form a diverse and robust ensemble.
Critical Analysis
The paper does not provide much detail on the specific strategies used for the exploration and exploitation phases, or how the different subnetworks are selected to form the final ensemble. Additionally, the experiments are limited to a few standard benchmarks, and the performance advantages over other ensemble methods may not generalize to more complex real-world problems.
Further research could explore more sophisticated techniques for navigating the parameter space and generating diverse subnetworks, as well as validating the approach on a wider range of applications. Potential limitations around scalability and computational efficiency should also be investigated in more depth.
Conclusion
This research presents a novel approach for creating deep ensembles that maintains model efficiency and generates diverse, high-performing subnetworks. By leveraging a sequential exploration and exploitation strategy, the method can produce robust and accurate ensembles in a computationally efficient manner. While further work is needed to fully understand the method's capabilities and limitations, this work represents an important step forward in developing practical and effective ensemble learning techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
0
Sequential Bayesian Neural Subnetwork Ensembles
Sanket Jantre, Shrijita Bhattacharya, Nathan M. Urban, Byung-Jun Yoon, Tapabrata Maiti, Prasanna Balaprakash, Sandeep Madireddy
Deep ensembles have emerged as a powerful technique for improving predictive performance and enhancing model robustness across various applications by leveraging model diversity. However, traditional deep ensemble methods are often computationally expensive and rely on deterministic models, which may limit their flexibility. Additionally, while sparse subnetworks of dense models have shown promise in matching the performance of their dense counterparts and even enhancing robustness, existing methods for inducing sparsity typically incur training costs comparable to those of training a single dense model, as they either gradually prune the network during training or apply thresholding post-training. In light of these challenges, we propose an approach for sequential ensembling of dynamic Bayesian neural subnetworks that consistently maintains reduced model complexity throughout the training process while generating diverse ensembles in a single forward pass. Our approach involves an initial exploration phase to identify high-performing regions within the parameter space, followed by multiple exploitation phases that take advantage of the compactness of the sparse model. These exploitation phases quickly converge to different minima in the energy landscape, corresponding to high-performing subnetworks that together form a diverse and robust ensemble. We empirically demonstrate that our proposed approach outperforms traditional dense and sparse deterministic and Bayesian ensemble models in terms of prediction accuracy, uncertainty estimation, out-of-distribution detection, and adversarial robustness.
Read more8/21/2024
🧠
0
Neural Subnetwork Ensembles
Tim Whitaker
Neural network ensembles have been effectively used to improve generalization by combining the predictions of multiple independently trained models. However, the growing scale and complexity of deep neural networks have led to these methods becoming prohibitively expensive and time consuming to implement. Low-cost ensemble methods have become increasingly important as they can alleviate the need to train multiple models from scratch while retaining the generalization benefits that traditional ensemble learning methods afford. This dissertation introduces and formalizes a low-cost framework for constructing Subnetwork Ensembles, where a collection of child networks are formed by sampling, perturbing, and optimizing subnetworks from a trained parent model. We explore several distinct methodologies for generating child networks and we evaluate their efficacy through a variety of ablation studies and established benchmarks. Our findings reveal that this approach can greatly improve training efficiency, parametric utilization, and generalization performance while minimizing computational cost. Subnetwork Ensembles offer a compelling framework for exploring how we can build better systems by leveraging the unrealized potential of deep neural networks.
Read more7/9/2024
0
Sparse Bayesian Networks: Efficient Uncertainty Quantification in Medical Image Analysis
Zeinab Abboud, Herve Lombaert, Samuel Kadoury
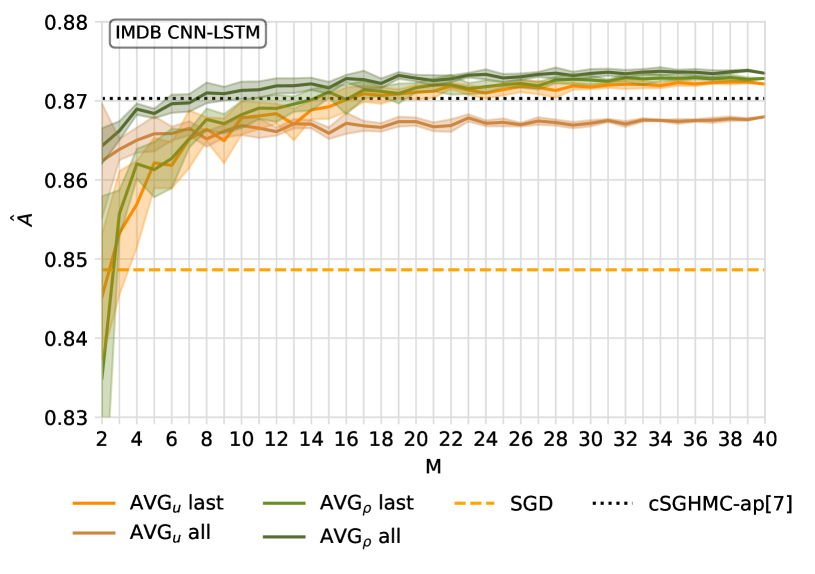
Efficiently quantifying predictive uncertainty in medical images remains a challenge. While Bayesian neural networks (BNN) offer predictive uncertainty, they require substantial computational resources to train. Although Bayesian approximations such as ensembles have shown promise, they still suffer from high training and inference costs. Existing approaches mainly address the costs of BNN inference post-training, with little focus on improving training efficiency and reducing parameter complexity. This study introduces a training procedure for a sparse (partial) Bayesian network. Our method selectively assigns a subset of parameters as Bayesian by assessing their deterministic saliency through gradient sensitivity analysis. The resulting network combines deterministic and Bayesian parameters, exploiting the advantages of both representations to achieve high task-specific performance and minimize predictive uncertainty. Demonstrated on multi-label ChestMNIST for classification and ISIC, LIDC-IDRI for segmentation, our approach achieves competitive performance and predictive uncertainty estimation by reducing Bayesian parameters by over 95%, significantly reducing computational expenses compared to fully Bayesian and ensemble methods.
Read more6/12/2024
0
Bayesian vs. PAC-Bayesian Deep Neural Network Ensembles
Nick Hauptvogel, Christian Igel
Bayesian neural networks address epistemic uncertainty by learning a posterior distribution over model parameters. Sampling and weighting networks according to this posterior yields an ensemble model referred to as Bayes ensemble. Ensembles of neural networks (deep ensembles) can profit from the cancellation of errors effect: Errors by ensemble members may average out and the deep ensemble achieves better predictive performance than each individual network. We argue that neither the sampling nor the weighting in a Bayes ensemble are particularly well-suited for increasing generalization performance, as they do not support the cancellation of errors effect, which is evident in the limit from the Bernstein-von~Mises theorem for misspecified models. In contrast, a weighted average of models where the weights are optimized by minimizing a PAC-Bayesian generalization bound can improve generalization performance. This requires that the optimization takes correlations between models into account, which can be achieved by minimizing the tandem loss at the cost that hold-out data for estimating error correlations need to be available. The PAC-Bayesian weighting increases the robustness against correlated models and models with lower performance in an ensemble. This allows us to safely add several models from the same learning process to an ensemble, instead of using early-stopping for selecting a single weight configuration. Our study presents empirical results supporting these conceptual considerations on four different classification datasets. We show that state-of-the-art Bayes ensembles from the literature, despite being computationally demanding, do not improve over simple uniformly weighted deep ensembles and cannot match the performance of deep ensembles weighted by optimizing the tandem loss, which additionally come with non-vacuous generalization guarantees.
Read more6/11/2024