Bayesian vs. PAC-Bayesian Deep Neural Network Ensembles

0
Sign in to get full access
Overview
- Compares the performance of Bayesian and PAC-Bayesian deep neural network ensembles
- Examines how different ensemble training approaches impact model accuracy and calibration
- Explores the trade-offs between Bayesian and PAC-Bayesian methods for deep learning
Plain English Explanation
This research paper looks at two different ways of training ensembles of deep neural networks - the Bayesian approach and the PAC-Bayesian approach. Ensembles are groups of individual models that work together to make predictions, and can often outperform a single model.
The Bayesian approach treats the parameters of the neural network models as probability distributions, rather than fixed values. This allows the models to capture uncertainty in their predictions. The PAC-Bayesian approach, on the other hand, provides theoretical guarantees about the model's performance, without requiring the full Bayesian framework.
The key question the paper explores is how these two different ensemble training approaches impact the accuracy and calibration of the final models. Calibration refers to how well the model's confidence in its predictions matches the true likelihood of being correct.
The researchers find that the Bayesian ensemble approach generally achieves higher accuracy, but the PAC-Bayesian ensembles are better calibrated. They also find some interesting trade-offs in terms of computational efficiency and the ability to handle different types of data and tasks.
Overall, the paper provides valuable insights into the pros and cons of Bayesian and PAC-Bayesian deep learning ensembles, and how the choice of approach can impact real-world model performance.
Technical Explanation
The paper compares the performance of Bayesian and PAC-Bayesian deep neural network ensembles across a range of benchmark datasets and tasks.
The Bayesian ensemble approach treats the network weights as probability distributions, which allows the models to capture uncertainty. This is implemented using variational inference techniques. The PAC-Bayesian ensemble, on the other hand, provides theoretical generalization bounds without requiring the full Bayesian framework.
The researchers evaluate the accuracy, calibration, and computational efficiency of the two ensemble approaches. They find that the Bayesian ensembles generally achieve higher predictive accuracy, but the PAC-Bayesian ensembles are better calibrated, meaning their confidence levels better match the true likelihood of being correct.
The paper also explores how the ensemble training approaches handle different data distributions and task types. For example, the PAC-Bayesian approach is shown to be more robust to distribution shift, while the Bayesian approach is more effective for uncertainty quantification.
Overall, the results highlight important trade-offs between the Bayesian and PAC-Bayesian ensemble methods, and provide guidance on when each approach may be more appropriate for real-world deep learning applications.
Critical Analysis
The paper provides a thorough and well-designed comparison of Bayesian and PAC-Bayesian deep learning ensembles. The experimental setup is rigorous, with evaluations across multiple benchmark datasets and tasks.
One potential limitation is the focus on standard image classification and regression tasks. It would be interesting to see how the two ensemble approaches perform on more complex, real-world applications with diverse data distributions and modeling requirements.
Additionally, the paper does not delve into the computational costs and scaling properties of the ensemble methods. As deep learning models continue to grow in size and complexity, the efficiency and scalability of ensemble techniques will be an important practical consideration.
The authors also acknowledge that their findings may be sensitive to the specific architectural choices and hyperparameter settings used for the neural networks. Further research could explore the robustness of the results to these design decisions.
Overall, this paper makes a valuable contribution to the understanding of Bayesian and PAC-Bayesian deep learning ensembles. The insights provided can help guide practitioners in selecting the most appropriate ensemble approach for their particular deep learning applications and requirements.
Conclusion
This research paper presents a comprehensive comparison of Bayesian and PAC-Bayesian deep neural network ensembles. The key findings are:
- Bayesian ensembles generally achieve higher predictive accuracy, while PAC-Bayesian ensembles are better calibrated
- There are trade-offs in terms of computational efficiency and the ability to handle different data distributions and task types
- The choice of ensemble approach should be guided by the specific requirements and constraints of the deep learning application
These results offer important guidance for deep learning practitioners in selecting the most appropriate ensemble method for their needs. The insights provided can help improve the real-world performance and reliability of deep neural network models across a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Bayesian vs. PAC-Bayesian Deep Neural Network Ensembles
Nick Hauptvogel, Christian Igel
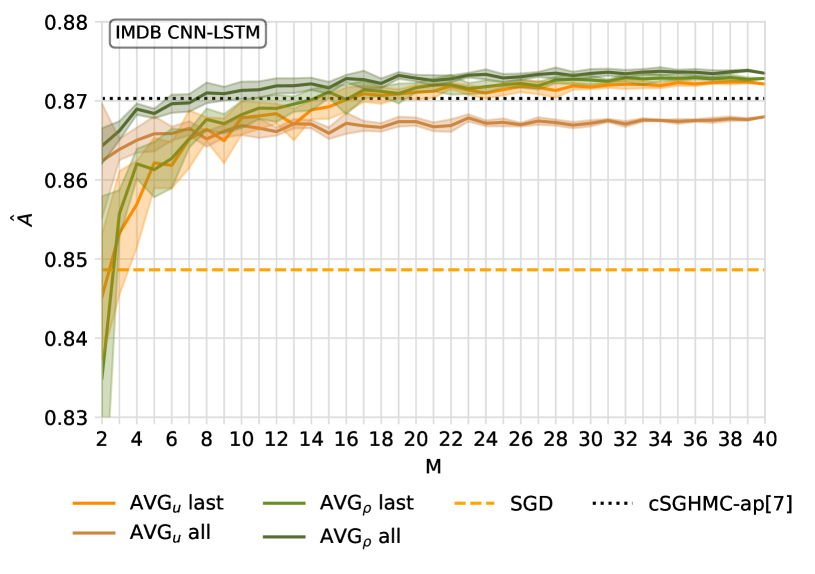
Bayesian neural networks address epistemic uncertainty by learning a posterior distribution over model parameters. Sampling and weighting networks according to this posterior yields an ensemble model referred to as Bayes ensemble. Ensembles of neural networks (deep ensembles) can profit from the cancellation of errors effect: Errors by ensemble members may average out and the deep ensemble achieves better predictive performance than each individual network. We argue that neither the sampling nor the weighting in a Bayes ensemble are particularly well-suited for increasing generalization performance, as they do not support the cancellation of errors effect, which is evident in the limit from the Bernstein-von~Mises theorem for misspecified models. In contrast, a weighted average of models where the weights are optimized by minimizing a PAC-Bayesian generalization bound can improve generalization performance. This requires that the optimization takes correlations between models into account, which can be achieved by minimizing the tandem loss at the cost that hold-out data for estimating error correlations need to be available. The PAC-Bayesian weighting increases the robustness against correlated models and models with lower performance in an ensemble. This allows us to safely add several models from the same learning process to an ensemble, instead of using early-stopping for selecting a single weight configuration. Our study presents empirical results supporting these conceptual considerations on four different classification datasets. We show that state-of-the-art Bayes ensembles from the literature, despite being computationally demanding, do not improve over simple uniformly weighted deep ensembles and cannot match the performance of deep ensembles weighted by optimizing the tandem loss, which additionally come with non-vacuous generalization guarantees.
Read more6/11/2024

0
Continual learning with the neural tangent ensemble
Ari S. Benjamin, Christian Pehle, Kyle Daruwalla
A natural strategy for continual learning is to weigh a Bayesian ensemble of fixed functions. This suggests that if a (single) neural network could be interpreted as an ensemble, one could design effective algorithms that learn without forgetting. To realize this possibility, we observe that a neural network classifier with N parameters can be interpreted as a weighted ensemble of N classifiers, and that in the lazy regime limit these classifiers are fixed throughout learning. We term these classifiers the neural tangent experts and show they output valid probability distributions over the labels. We then derive the likelihood and posterior probability of each expert given past data. Surprisingly, we learn that the posterior updates for these experts are equivalent to a scaled and projected form of stochastic gradient descent (SGD) over the network weights. Away from the lazy regime, networks can be seen as ensembles of adaptive experts which improve over time. These results offer a new interpretation of neural networks as Bayesian ensembles of experts, providing a principled framework for understanding and mitigating catastrophic forgetting in continual learning settings.
Read more9/2/2024
📶
0
Sequential Bayesian Neural Subnetwork Ensembles
Sanket Jantre, Shrijita Bhattacharya, Nathan M. Urban, Byung-Jun Yoon, Tapabrata Maiti, Prasanna Balaprakash, Sandeep Madireddy
Deep ensembles have emerged as a powerful technique for improving predictive performance and enhancing model robustness across various applications by leveraging model diversity. However, traditional deep ensemble methods are often computationally expensive and rely on deterministic models, which may limit their flexibility. Additionally, while sparse subnetworks of dense models have shown promise in matching the performance of their dense counterparts and even enhancing robustness, existing methods for inducing sparsity typically incur training costs comparable to those of training a single dense model, as they either gradually prune the network during training or apply thresholding post-training. In light of these challenges, we propose an approach for sequential ensembling of dynamic Bayesian neural subnetworks that consistently maintains reduced model complexity throughout the training process while generating diverse ensembles in a single forward pass. Our approach involves an initial exploration phase to identify high-performing regions within the parameter space, followed by multiple exploitation phases that take advantage of the compactness of the sparse model. These exploitation phases quickly converge to different minima in the energy landscape, corresponding to high-performing subnetworks that together form a diverse and robust ensemble. We empirically demonstrate that our proposed approach outperforms traditional dense and sparse deterministic and Bayesian ensemble models in terms of prediction accuracy, uncertainty estimation, out-of-distribution detection, and adversarial robustness.
Read more8/21/2024
🌿
0
WASH: Train your Ensemble with Communication-Efficient Weight Shuffling, then Average
Louis Fournier (MLIA), Adel Nabli (MLIA, Mila), Masih Aminbeidokhti (ETS), Marco Pedersoli (ETS), Eugene Belilovsky (Mila), Edouard Oyallon
The performance of deep neural networks is enhanced by ensemble methods, which average the output of several models. However, this comes at an increased cost at inference. Weight averaging methods aim at balancing the generalization of ensembling and the inference speed of a single model by averaging the parameters of an ensemble of models. Yet, naive averaging results in poor performance as models converge to different loss basins, and aligning the models to improve the performance of the average is challenging. Alternatively, inspired by distributed training, methods like DART and PAPA have been proposed to train several models in parallel such that they will end up in the same basin, resulting in good averaging accuracy. However, these methods either compromise ensembling accuracy or demand significant communication between models during training. In this paper, we introduce WASH, a novel distributed method for training model ensembles for weight averaging that achieves state-of-the-art image classification accuracy. WASH maintains models within the same basin by randomly shuffling a small percentage of weights during training, resulting in diverse models and lower communication costs compared to standard parameter averaging methods.
Read more5/29/2024