Sharing Parameter by Conjugation for Knowledge Graph Embeddings in Complex Space

0

Sign in to get full access
Overview
- This paper proposes a new method called "Sharing Parameter by Conjugation" (SPC) for learning knowledge graph embeddings in complex space.
- The authors argue that SPC can better capture the intrinsic properties of knowledge graphs by representing entities and relations as complex-valued vectors.
- SPC introduces a conjugation operation to share parameters between entities and relations, which allows the model to learn more efficient and expressive representations.
Plain English Explanation
Knowledge graphs are structured databases that represent real-world entities and the relationships between them. Embedding models for knowledge graphs have become a popular approach for learning efficient representations of this data that can be used in various applications.
The authors of this paper propose a new embedding model called "Sharing Parameter by Conjugation" (SPC) that represents entities and relations as complex-valued vectors. Complex numbers are a type of number with both real and imaginary parts, which can capture more intricate patterns in the knowledge graph.
The key innovation of SPC is the use of a conjugation operation to share parameters between the entity and relation embeddings. This allows the model to learn more efficient and expressive representations compared to previous approaches. Intuitively, the conjugation operation can be thought of as a way to "mirror" the entity and relation vectors, enabling the model to better capture the inherent structure of the knowledge graph.
The authors demonstrate the effectiveness of SPC through experiments on several benchmark knowledge graph datasets. They show that SPC outperforms state-of-the-art embedding models on various tasks, such as link prediction and triple classification.
Technical Explanation
The authors propose a new knowledge graph embedding model called "Sharing Parameter by Conjugation" (SPC), which represents entities and relations as complex-valued vectors. SPC introduces a conjugation operation to share parameters between the entity and relation embeddings.
Formally, the SPC model learns a complex-valued embedding for each entity e and relation r, denoted as e and r, respectively. The score function for a given triple (h, r, t) is defined as:
score(h, r, t) = Re(h⊗r⊙t)
where ⊗ and ⊙ denote the Hadamard product and complex conjugation operation, respectively.
The key innovation of SPC is the use of the conjugation operation ⊙ to share parameters between the entity and relation embeddings. This allows the model to learn more efficient and expressive representations compared to previous approaches that treat entities and relations independently.
The authors demonstrate the effectiveness of SPC on several benchmark knowledge graph datasets, including FB15k-237, WN18RR, and YAGO3-10. SPC outperforms state-of-the-art embedding models on tasks such as link prediction and triple classification, demonstrating the advantages of learning complex-valued representations with shared parameters.
Critical Analysis
The authors provide a thorough evaluation of SPC and compare it to various baselines, demonstrating its effectiveness on several benchmark datasets. However, the paper does not discuss any major limitations or caveats of the proposed approach.
One potential concern is the interpretability of the complex-valued embeddings learned by SPC. While the conjugation operation can lead to more expressive representations, it may also make the learned embeddings more difficult to interpret and understand compared to real-valued embeddings.
Additionally, the paper does not explore the computational complexity or training time of SPC compared to other knowledge graph embedding models. This information would be valuable for assessing the practicality of the approach, especially for large-scale knowledge graphs.
Overall, the authors present a novel and promising approach for learning knowledge graph embeddings in complex space. However, further research is needed to better understand the strengths, weaknesses, and practical implications of the SPC model.
Conclusion
This paper introduces a new knowledge graph embedding model called "Sharing Parameter by Conjugation" (SPC) that represents entities and relations as complex-valued vectors. The key innovation of SPC is the use of a conjugation operation to share parameters between the entity and relation embeddings, which allows the model to learn more efficient and expressive representations.
The authors demonstrate the effectiveness of SPC through experiments on several benchmark knowledge graph datasets, showing that it outperforms state-of-the-art embedding models on tasks such as link prediction and triple classification. While the paper provides a thorough technical explanation and evaluation of the proposed approach, it does not discuss any major limitations or caveats.
Overall, the SPC model presents a promising direction for advancing knowledge graph embedding techniques by leveraging the representational power of complex-valued vectors. However, further research is needed to better understand the practical implications and interpretability of the learned embeddings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Sharing Parameter by Conjugation for Knowledge Graph Embeddings in Complex Space
Xincan Feng, Zhi Qu, Yuchang Cheng, Taro Watanabe, Nobuhiro Yugami
A Knowledge Graph (KG) is the directed graphical representation of entities and relations in the real world. KG can be applied in diverse Natural Language Processing (NLP) tasks where knowledge is required. The need to scale up and complete KG automatically yields Knowledge Graph Embedding (KGE), a shallow machine learning model that is suffering from memory and training time consumption issues. To mitigate the computational load, we propose a parameter-sharing method, i.e., using conjugate parameters for complex numbers employed in KGE models. Our method improves memory efficiency by 2x in relation embedding while achieving comparable performance to the state-of-the-art non-conjugate models, with faster, or at least comparable, training time. We demonstrated the generalizability of our method on two best-performing KGE models $5^{bigstar}mathrm{E}$ and $mathrm{ComplEx}$ on five benchmark datasets.
Read more4/19/2024
0
On The Expressive Power of Knowledge Graph Embedding Methods
Jiexing Gao, Dmitry Rodin, Vasily Motolygin, Denis Zaytsev
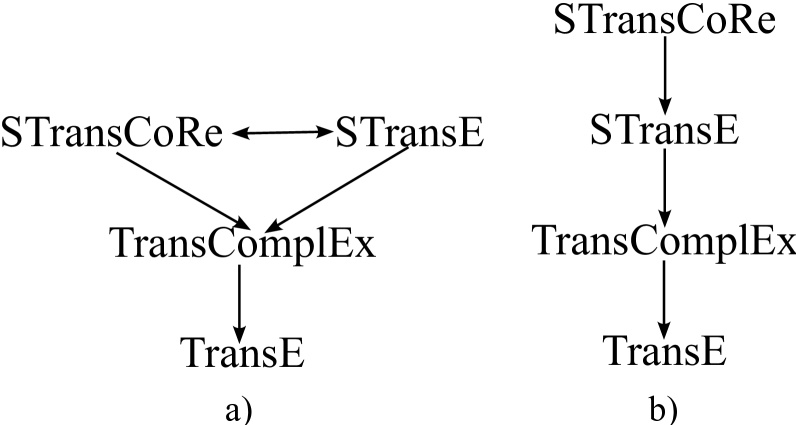
Knowledge Graph Embedding (KGE) is a popular approach, which aims to represent entities and relations of a knowledge graph in latent spaces. Their representations are known as embeddings. To measure the plausibility of triplets, score functions are defined over embedding spaces. Despite wide dissemination of KGE in various tasks, KGE methods have limitations in reasoning abilities. In this paper we propose a mathematical framework to compare reasoning abilities of KGE methods. We show that STransE has a higher capability than TransComplEx, and then present new STransCoRe method, which improves the STransE by combining it with the TransCoRe insights, which can reduce the STransE space complexity.
Read more7/29/2024
📉
0
Generalizing Knowledge Graph Embedding with Universal Orthogonal Parameterization
Rui Li, Chaozhuo Li, Yanming Shen, Zeyu Zhang, Xu Chen
Recent advances in knowledge graph embedding (KGE) rely on Euclidean/hyperbolic orthogonal relation transformations to model intrinsic logical patterns and topological structures. However, existing approaches are confined to rigid relational orthogonalization with restricted dimension and homogeneous geometry, leading to deficient modeling capability. In this work, we move beyond these approaches in terms of both dimension and geometry by introducing a powerful framework named GoldE, which features a universal orthogonal parameterization based on a generalized form of Householder reflection. Such parameterization can naturally achieve dimensional extension and geometric unification with theoretical guarantees, enabling our framework to simultaneously capture crucial logical patterns and inherent topological heterogeneity of knowledge graphs. Empirically, GoldE achieves state-of-the-art performance on three standard benchmarks. Codes are available at https://github.com/xxrep/GoldE.
Read more5/15/2024
🌐
0
From Wide to Deep: Dimension Lifting Network for Parameter-efficient Knowledge Graph Embedding
Borui Cai, Yong Xiang, Longxiang Gao, Di Wu, He Zhang, Jiong Jin, Tom Luan
Knowledge graph embedding (KGE) that maps entities and relations into vector representations is essential for downstream applications. Conventional KGE methods require high-dimensional representations to learn the complex structure of knowledge graph, but lead to oversized model parameters. Recent advances reduce parameters by low-dimensional entity representations, while developing techniques (e.g., knowledge distillation or reinvented representation forms) to compensate for reduced dimension. However, such operations introduce complicated computations and model designs that may not benefit large knowledge graphs. To seek a simple strategy to improve the parameter efficiency of conventional KGE models, we take inspiration from that deeper neural networks require exponentially fewer parameters to achieve expressiveness comparable to wider networks for compositional structures. We view all entity representations as a single-layer embedding network, and conventional KGE methods that adopt high-dimensional entity representations equal widening the embedding network to gain expressiveness. To achieve parameter efficiency, we instead propose a deeper embedding network for entity representations, i.e., a narrow entity embedding layer plus a multi-layer dimension lifting network (LiftNet). Experiments on three public datasets show that by integrating LiftNet, four conventional KGE methods with 16-dimensional representations achieve comparable link prediction accuracy as original models that adopt 512-dimensional representations, saving 68.4% to 96.9% parameters.
Read more9/4/2024