SimpleSpeech 2: Towards Simple and Efficient Text-to-Speech with Flow-based Scalar Latent Transformer Diffusion Models

0

Sign in to get full access
Overview
- This paper proposes SimpleSpeech 2, a text-to-speech (TTS) system that uses a flow-based scalar latent Transformer diffusion model.
- The goal is to create a simple and efficient TTS system that can generate high-quality audio.
- The paper explores the use of diffusion models, which learn to convert simple noise into complex data like audio, as an alternative to traditional autoregressive models.
Plain English Explanation
The researchers have developed a new text-to-speech (TTS) system called SimpleSpeech 2. TTS systems convert written text into spoken audio, and this new approach aims to be more simple and efficient than previous methods.
The key innovation is the use of diffusion models, a type of machine learning model that learns to transform simple noise into complex data like audio. This is different from the more common autoregressive models, which generate audio one piece at a time.
The researchers believe this diffusion-based approach can produce high-quality audio in a simpler and more efficient way than existing TTS systems. By using a "scalar latent Transformer" architecture, they aim to make the model smaller and faster while maintaining good performance.
Technical Explanation
The SimpleSpeech 2 system uses a flow-based scalar latent Transformer diffusion model to generate audio from text. Diffusion models work by learning to gradually transform simple noise into complex data like audio waveforms.
The key elements of the SimpleSpeech 2 architecture include:
- Transformer Encoder: Encodes the input text into a sequence of latent embeddings.
- Scalar Latent Transformer: Applies a series of diffusion and denoising steps to the latent embeddings to generate a sequence of scalar latent variables.
- Waveform Decoder: Reconstructs the final audio waveform from the scalar latent variables.
The researchers trained and evaluated SimpleSpeech 2 on several benchmark TTS datasets. They found that it can generate high-quality audio while being more efficient and scalable than previous diffusion-based TTS models.
Critical Analysis
The paper presents a promising new approach to text-to-speech generation using diffusion models. Compared to traditional autoregressive models, the diffusion-based approach offers potential benefits in terms of simplicity and efficiency.
However, the paper does not provide a detailed analysis of the limitations or potential drawbacks of the SimpleSpeech 2 system. For example, it is unclear how the model's performance compares to state-of-the-art autoregressive TTS systems, or how it handles issues like speaker adaptation or emotional expression.
Additionally, the researchers do not explore the potential robustness or generalization capabilities of the diffusion-based approach. Further research would be needed to understand the system's limitations and how it could be improved or extended.
Conclusion
The SimpleSpeech 2 paper presents a novel approach to text-to-speech generation using flow-based scalar latent Transformer diffusion models. This diffusion-based system aims to be more simple and efficient than previous TTS methods while maintaining high-quality audio output.
While the results are promising, further research is needed to fully understand the strengths, weaknesses, and potential of this diffusion-based TTS approach. Nonetheless, the paper contributes to the ongoing efforts to develop more effective and scalable text-to-speech systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SimpleSpeech 2: Towards Simple and Efficient Text-to-Speech with Flow-based Scalar Latent Transformer Diffusion Models
Dongchao Yang, Rongjie Huang, Yuanyuan Wang, Haohan Guo, Dading Chong, Songxiang Liu, Xixin Wu, Helen Meng
Scaling Text-to-speech (TTS) to large-scale datasets has been demonstrated as an effective method for improving the diversity and naturalness of synthesized speech. At the high level, previous large-scale TTS models can be categorized into either Auto-regressive (AR) based (textit{e.g.}, VALL-E) or Non-auto-regressive (NAR) based models (textit{e.g.}, NaturalSpeech 2/3). Although these works demonstrate good performance, they still have potential weaknesses. For instance, AR-based models are plagued by unstable generation quality and slow generation speed; meanwhile, some NAR-based models need phoneme-level duration alignment information, thereby increasing the complexity of data pre-processing, model design, and loss design. In this work, we build upon our previous publication by implementing a simple and efficient non-autoregressive (NAR) TTS framework, termed SimpleSpeech 2. SimpleSpeech 2 effectively combines the strengths of both autoregressive (AR) and non-autoregressive (NAR) methods, offering the following key advantages: (1) simplified data preparation; (2) straightforward model and loss design; and (3) stable, high-quality generation performance with fast inference speed. Compared to our previous publication, we present ({romannumeral1}) a detailed analysis of the influence of speech tokenizer and noisy label for TTS performance; ({romannumeral2}) four distinct types of sentence duration predictors; ({romannumeral3}) a novel flow-based scalar latent transformer diffusion model. With these improvement, we show a significant improvement in generation performance and generation speed compared to our previous work and other state-of-the-art (SOTA) large-scale TTS models. Furthermore, we show that SimpleSpeech 2 can be seamlessly extended to multilingual TTS by training it on multilingual speech datasets. Demos are available on: {https://dongchaoyang.top/SimpleSpeech2_demo/}.
Read more8/29/2024
0
SimpleSpeech: Towards Simple and Efficient Text-to-Speech with Scalar Latent Transformer Diffusion Models
Dongchao Yang, Dingdong Wang, Haohan Guo, Xueyuan Chen, Xixin Wu, Helen Meng
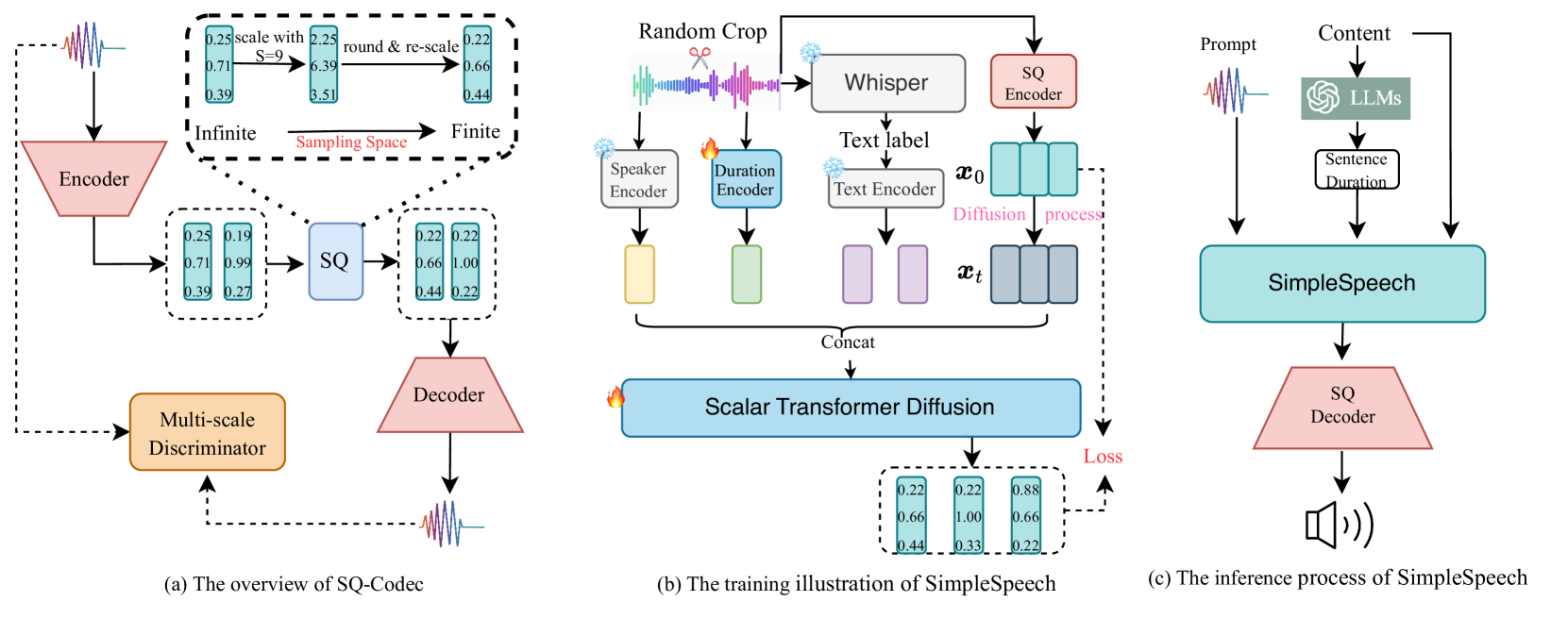
In this study, we propose a simple and efficient Non-Autoregressive (NAR) text-to-speech (TTS) system based on diffusion, named SimpleSpeech. Its simpleness shows in three aspects: (1) It can be trained on the speech-only dataset, without any alignment information; (2) It directly takes plain text as input and generates speech through an NAR way; (3) It tries to model speech in a finite and compact latent space, which alleviates the modeling difficulty of diffusion. More specifically, we propose a novel speech codec model (SQ-Codec) with scalar quantization, SQ-Codec effectively maps the complex speech signal into a finite and compact latent space, named scalar latent space. Benefits from SQ-Codec, we apply a novel transformer diffusion model in the scalar latent space of SQ-Codec. We train SimpleSpeech on 4k hours of a speech-only dataset, it shows natural prosody and voice cloning ability. Compared with previous large-scale TTS models, it presents significant speech quality and generation speed improvement. Demos are released.
Read more6/17/2024

19
DiTTo-TTS: Efficient and Scalable Zero-Shot Text-to-Speech with Diffusion Transformer
Keon Lee, Dong Won Kim, Jaehyeon Kim, Jaewoong Cho
Large-scale diffusion models have shown outstanding generative abilities across multiple modalities including images, videos, and audio. However, text-to-speech (TTS) systems typically involve domain-specific modeling factors (e.g., phonemes and phoneme-level durations) to ensure precise temporal alignments between text and speech, which hinders the efficiency and scalability of diffusion models for TTS. In this work, we present an efficient and scalable Diffusion Transformer (DiT) that utilizes off-the-shelf pre-trained text and speech encoders. Our approach addresses the challenge of text-speech alignment via cross-attention mechanisms with the prediction of the total length of speech representations. To achieve this, we enhance the DiT architecture to suit TTS and improve the alignment by incorporating semantic guidance into the latent space of speech. We scale the training dataset and the model size to 82K hours and 790M parameters, respectively. Our extensive experiments demonstrate that the large-scale diffusion model for TTS without domain-specific modeling not only simplifies the training pipeline but also yields superior or comparable zero-shot performance to state-of-the-art TTS models in terms of naturalness, intelligibility, and speaker similarity. Our speech samples are available at https://ditto-tts.github.io.
Read more6/18/2024

0
CTC-based Non-autoregressive Textless Speech-to-Speech Translation
Qingkai Fang, Zhengrui Ma, Yan Zhou, Min Zhang, Yang Feng
Direct speech-to-speech translation (S2ST) has achieved impressive translation quality, but it often faces the challenge of slow decoding due to the considerable length of speech sequences. Recently, some research has turned to non-autoregressive (NAR) models to expedite decoding, yet the translation quality typically lags behind autoregressive (AR) models significantly. In this paper, we investigate the performance of CTC-based NAR models in S2ST, as these models have shown impressive results in machine translation. Experimental results demonstrate that by combining pretraining, knowledge distillation, and advanced NAR training techniques such as glancing training and non-monotonic latent alignments, CTC-based NAR models achieve translation quality comparable to the AR model, while preserving up to 26.81$times$ decoding speedup.
Read more6/12/2024