SLAB: Efficient Transformers with Simplified Linear Attention and Progressive Re-parameterized Batch Normalization

0

Sign in to get full access
Overview
- This paper introduces SLAB, a novel Transformer architecture that simplifies the linear attention mechanism and uses progressive re-parameterized batch normalization to improve efficiency.
- The key innovations are a simplified linear attention mechanism and a progressive re-parameterized batch normalization technique that reduces computational complexity and memory usage.
- SLAB is evaluated on a range of tasks including language modeling, machine translation, and image classification, demonstrating competitive performance with significantly lower computational and memory requirements compared to standard Transformer models.
Plain English Explanation
The paper presents a new type of Transformer model called SLAB, which stands for "Simplified Linear Attention and Progressive Batch Normalization." Transformers are a popular type of deep learning model used for tasks like language processing and image recognition.
The main ideas behind SLAB are:
-
Simplified Linear Attention: The standard Transformer model uses a complex "attention" mechanism to figure out which parts of the input are most important. SLAB simplifies this attention mechanism, making it more efficient to compute without sacrificing much performance.
-
Progressive Batch Normalization: Batch normalization is a technique used to improve the training of deep learning models. SLAB uses a modified version of batch normalization that is more computationally efficient.
By using these two innovations, the SLAB model can achieve similar performance to standard Transformers, but with significantly lower computational and memory requirements. This makes SLAB models more practical to deploy, especially on resource-constrained devices like smartphones or embedded systems.
The paper evaluates SLAB on a variety of tasks like language modeling, machine translation, and image classification. The results show that SLAB can match or exceed the performance of standard Transformer models, while using less time and memory to run.
Technical Explanation
The key technical innovations in SLAB are the Simplified Linear Attention (SLA) mechanism and the Progressive Re-parameterized Batch Normalization (PRBN) technique.
Simplified Linear Attention (SLA): The standard Transformer attention mechanism involves computing a matrix of attention weights that scale the input features. SLAB simplifies this by using a linear attention function that is more efficient to compute, yet still captures the most relevant parts of the input. This is achieved by modifying the attention formula to avoid the expensive softmax operation.
Progressive Re-parameterized Batch Normalization (PRBN): Batch normalization is a crucial component of modern deep learning models, but it can be computationally expensive. SLAB uses a re-parameterized version of batch normalization that progressively adjusts the normalization parameters during training. This reduces the overall computational and memory requirements of the model.
The paper presents detailed experiments evaluating SLAB on a range of tasks, including language modeling, machine translation, and image classification. The results show that SLAB can achieve competitive performance with significantly lower computational and memory footprints compared to standard Transformer models.
Critical Analysis
The paper provides a thorough evaluation of SLAB and demonstrates its effectiveness across multiple benchmark tasks. However, there are a few potential limitations and areas for further research:
-
Generalization to Larger Models: The experiments in the paper focus on relatively small-scale models. It would be interesting to see how well SLAB scales to larger, more complex Transformer architectures used in state-of-the-art language models like BERT or GPT-3.
-
Attention Visualization and Interpretability: The paper does not provide much analysis of the attention patterns learned by the SLAB model. Visualizing and interpreting the attention weights could yield additional insights into how the simplified attention mechanism differs from the standard approach.
-
Real-world Deployment Tradeoffs: While the paper demonstrates impressive efficiency gains, there may be additional practical considerations for deploying SLAB in real-world scenarios, such as the impact on inference latency or power consumption on edge devices.
Overall, the SLAB model represents an interesting and promising direction for improving the efficiency of Transformer-based architectures. The simplified attention mechanism and progressive batch normalization techniques could have broader applicability in the field of deep learning.
Conclusion
This paper introduces SLAB, a novel Transformer-based model that achieves competitive performance with significantly lower computational and memory requirements compared to standard Transformer architectures. The key innovations are a simplified linear attention mechanism and a progressive re-parameterized batch normalization technique, which together make SLAB models more efficient to train and deploy.
The experimental results demonstrate the effectiveness of SLAB across a range of tasks, including language modeling, machine translation, and image classification. While there are a few potential limitations and areas for further research, the SLAB model represents an important step towards more efficient and practical Transformer-based systems, with implications for real-world applications on resource-constrained devices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SLAB: Efficient Transformers with Simplified Linear Attention and Progressive Re-parameterized Batch Normalization
Jialong Guo, Xinghao Chen, Yehui Tang, Yunhe Wang
Transformers have become foundational architectures for both natural language and computer vision tasks. However, the high computational cost makes it quite challenging to deploy on resource-constraint devices. This paper investigates the computational bottleneck modules of efficient transformer, i.e., normalization layers and attention modules. LayerNorm is commonly used in transformer architectures but is not computational friendly due to statistic calculation during inference. However, replacing LayerNorm with more efficient BatchNorm in transformer often leads to inferior performance and collapse in training. To address this problem, we propose a novel method named PRepBN to progressively replace LayerNorm with re-parameterized BatchNorm in training. Moreover, we propose a simplified linear attention (SLA) module that is simple yet effective to achieve strong performance. Extensive experiments on image classification as well as object detection demonstrate the effectiveness of our proposed method. For example, our SLAB-Swin obtains $83.6%$ top-1 accuracy on ImageNet-1K with $16.2$ms latency, which is $2.4$ms less than that of Flatten-Swin with $0.1%$ higher accuracy. We also evaluated our method for language modeling task and obtain comparable performance and lower latency.Codes are publicly available at https://github.com/xinghaochen/SLAB and https://github.com/mindspore-lab/models/tree/master/research/huawei-noah/SLAB.
Read more6/18/2024

0
A Primal-Dual Framework for Transformers and Neural Networks
Tan M. Nguyen, Tam Nguyen, Nhat Ho, Andrea L. Bertozzi, Richard G. Baraniuk, Stanley J. Osher
Self-attention is key to the remarkable success of transformers in sequence modeling tasks including many applications in natural language processing and computer vision. Like neural network layers, these attention mechanisms are often developed by heuristics and experience. To provide a principled framework for constructing attention layers in transformers, we show that the self-attention corresponds to the support vector expansion derived from a support vector regression problem, whose primal formulation has the form of a neural network layer. Using our framework, we derive popular attention layers used in practice and propose two new attentions: 1) the Batch Normalized Attention (Attention-BN) derived from the batch normalization layer and 2) the Attention with Scaled Head (Attention-SH) derived from using less training data to fit the SVR model. We empirically demonstrate the advantages of the Attention-BN and Attention-SH in reducing head redundancy, increasing the model's accuracy, and improving the model's efficiency in a variety of practical applications including image and time-series classification.
Read more6/21/2024
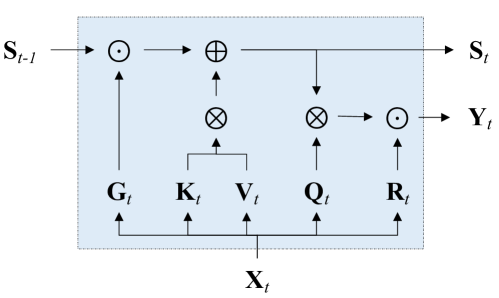
1
Gated Linear Attention Transformers with Hardware-Efficient Training
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, Yoon Kim
Transformers with linear attention allow for efficient parallel training but can simultaneously be formulated as an RNN with 2D (matrix-valued) hidden states, thus enjoying linear-time inference complexity. However, linear attention generally underperforms ordinary softmax attention. Moreover, current implementations of linear attention lack I/O-awareness and are thus slower than highly optimized implementations of softmax attention. This work describes a hardware-efficient algorithm for linear attention that trades off memory movement against parallelizability. The resulting implementation, dubbed FLASHLINEARATTENTION, is faster than FLASHATTENTION-2 (Dao, 2023) as a standalone layer even on short sequence lengths (e.g., 1K). We then generalize this algorithm to a more expressive variant of linear attention with data-dependent gates. When used as a replacement for the standard attention layer in Transformers, the resulting gated linear attention (GLA) Transformer is found to perform competitively against the LLaMA-architecture Transformer (Touvron et al., 2023) as well recent linear-time-inference baselines such as RetNet (Sun et al., 2023a) and Mamba (Gu & Dao, 2023) on moderate-scale language modeling experiments. GLA Transformer is especially effective at length generalization, enabling a model trained on 2K to generalize to sequences longer than 20K without significant perplexity degradations. For training speed, the GLA Transformer has higher throughput than a similarly-sized Mamba model.
Read more6/6/2024
🎲
0
UnitNorm: Rethinking Normalization for Transformers in Time Series
Nan Huang, Christian Kummerle, Xiang Zhang
Normalization techniques are crucial for enhancing Transformer models' performance and stability in time series analysis tasks, yet traditional methods like batch and layer normalization often lead to issues such as token shift, attention shift, and sparse attention. We propose UnitNorm, a novel approach that scales input vectors by their norms and modulates attention patterns, effectively circumventing these challenges. Grounded in existing normalization frameworks, UnitNorm's effectiveness is demonstrated across diverse time series analysis tasks, including forecasting, classification, and anomaly detection, via a rigorous evaluation on 6 state-of-the-art models and 10 datasets. Notably, UnitNorm shows superior performance, especially in scenarios requiring robust attention mechanisms and contextual comprehension, evidenced by significant improvements by up to a 1.46 decrease in MSE for forecasting, and a 4.89% increase in accuracy for classification. This work not only calls for a reevaluation of normalization strategies in time series Transformers but also sets a new direction for enhancing model performance and stability. The source code is available at https://anonymous.4open.science/r/UnitNorm-5B84.
Read more5/28/2024