SlowFast-LLaVA: A Strong Training-Free Baseline for Video Large Language Models

0

Sign in to get full access
Overview
- The paper presents SlowFast-LLaVA, a training-free baseline for video large language models (VLLMs).
- SlowFast-LLaVA combines a SlowFast video encoder with a self-attention-based language model, achieving strong performance on various video understanding tasks without any training.
- The model leverages pre-trained vision and language models, demonstrating the potential of training-free approaches for VLLMs.
Plain English Explanation
The researchers have developed a new model called SlowFast-LLaVA, which is a way to understand and analyze videos using language. It combines two existing technologies: a SlowFast video encoder, which can capture both slow and fast motion in videos, and a self-attention-based language model, which can understand and generate human language.
The key innovation is that SlowFast-LLaVA doesn't require any additional training. Instead, it uses pre-trained versions of the video encoder and language model, which means the model can be used out-of-the-box without needing to be trained on a large dataset first. This makes it a "training-free" approach, which is an exciting development for video large language models.
The researchers show that SlowFast-LLaVA can perform well on various video understanding tasks, such as video captioning and video question answering, without any additional training. This demonstrates the potential of training-free approaches for building powerful video large language models that can be easily deployed and used in real-world applications.
Technical Explanation
The core of SlowFast-LLaVA is the combination of a SlowFast video encoder and a self-attention-based language model. The SlowFast encoder, which has been previously proposed for image understanding, captures both slow and fast motion in videos by processing the input at multiple temporal resolutions.
The language model component is a self-attention-based transformer, which can understand and generate human language. By connecting the video encoder and language model, SlowFast-LLaVA can perform various video understanding tasks, such as video captioning and video question answering, without any additional training.
The researchers evaluated SlowFast-LLaVA on several benchmark datasets and found that it achieved strong performance, often matching or exceeding the results of models that were trained on large video datasets. This suggests that the pre-trained vision and language models used in SlowFast-LLaVA are powerful enough to capture the essential information needed for video understanding tasks, without the need for further training.
Critical Analysis
The key strength of SlowFast-LLaVA is its training-free nature, which makes it easy to deploy and use in real-world applications. However, the paper does not explore the limitations of this approach or how it compares to models that are trained on large video datasets.
It would be interesting to see how SlowFast-LLaVA performs on more challenging video understanding tasks, such as long-form video analysis or online video understanding, where the benefits of training-free approaches may be more apparent.
Additionally, the paper does not discuss the potential biases or limitations of the pre-trained vision and language models used in SlowFast-LLaVA, which could impact its performance and generalization to diverse datasets and real-world scenarios.
Conclusion
The SlowFast-LLaVA model presented in this paper is a promising step towards training-free video large language models. By leveraging pre-trained vision and language models, the researchers have demonstrated the potential for powerful video understanding capabilities without the need for extensive training.
This work highlights the exciting possibilities of training-free approaches in the field of video understanding, which could lead to more accessible and deployable AI models for a wide range of applications. As the research in this area continues to evolve, it will be important to explore the limitations and potential biases of these models, as well as investigate their performance on more complex video understanding tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SlowFast-LLaVA: A Strong Training-Free Baseline for Video Large Language Models
Mingze Xu, Mingfei Gao, Zhe Gan, Hong-You Chen, Zhengfeng Lai, Haiming Gang, Kai Kang, Afshin Dehghan
We propose SlowFast-LLaVA (or SF-LLaVA for short), a training-free video large language model (LLM) that can jointly capture detailed spatial semantics and long-range temporal context without exceeding the token budget of commonly used LLMs. This is realized by using a two-stream SlowFast design of inputs for Video LLMs to aggregate features from sampled frames in an effective way. Specifically, the Slow pathway extracts features at a low frame rate while keeping as much spatial detail as possible (e.g., with 12x24 tokens), and the Fast pathway operates on a high frame rate but uses a larger spatial pooling stride (e.g., downsampling 6x) to focus on the motion cues. As a result, this design allows us to adequately capture both spatial and temporal features that are beneficial for detailed video understanding. Experimental results show that SF-LLaVA outperforms existing training-free methods on a wide range of video tasks. On some benchmarks, it achieves comparable or even better performance compared to state-of-the-art Video LLMs that are fine-tuned on video datasets. Code has been made available at: https://github.com/apple/ml-slowfast-llava.
Read more9/17/2024

0
PLLaVA : Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning
Lin Xu, Yilin Zhao, Daquan Zhou, Zhijie Lin, See Kiong Ng, Jiashi Feng
Vision-language pre-training has significantly elevated performance across a wide range of image-language applications. Yet, the pre-training process for video-related tasks demands exceptionally large computational and data resources, which hinders the progress of video-language models. This paper investigates a straight-forward, highly efficient, and resource-light approach to adapting an existing image-language pre-trained model for dense video understanding. Our preliminary experiments reveal that directly fine-tuning pre-trained image-language models with multiple frames as inputs on video datasets leads to performance saturation or even a drop. Our further investigation reveals that it is largely attributed to the bias of learned high-norm visual features. Motivated by this finding, we propose a simple but effective pooling strategy to smooth the feature distribution along the temporal dimension and thus reduce the dominant impacts from the extreme features. The new model is termed Pooling LLaVA, or PLLaVA in short. PLLaVA achieves new state-of-the-art performance on modern benchmark datasets for both video question-answer and captioning tasks. Notably, on the recent popular VideoChatGPT benchmark, PLLaVA achieves a score of 3.48 out of 5 on average of five evaluated dimensions, exceeding the previous SOTA results from GPT4V (IG-VLM) by 9%. On the latest multi-choice benchmark MVBench, PLLaVA achieves 58.1% accuracy on average across 20 sub-tasks, 14.5% higher than GPT4V (IG-VLM). Code is available at https://pllava.github.io/
Read more4/30/2024
📈
0
New!Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, Li Yuan
The Large Vision-Language Model (LVLM) has enhanced the performance of various downstream tasks in visual-language understanding. Most existing approaches encode images and videos into separate feature spaces, which are then fed as inputs to large language models. However, due to the lack of unified tokenization for images and videos, namely misalignment before projection, it becomes challenging for a Large Language Model (LLM) to learn multi-modal interactions from several poor projection layers. In this work, we unify visual representation into the language feature space to advance the foundational LLM towards a unified LVLM. As a result, we establish a simple but robust LVLM baseline, Video-LLaVA, which learns from a mixed dataset of images and videos, mutually enhancing each other. Video-LLaVA achieves superior performances on a broad range of 9 image benchmarks across 5 image question-answering datasets and 4 image benchmark toolkits. Additionally, our Video-LLaVA also outperforms Video-ChatGPT by 5.8%, 9.9%, 18.6%, and 10.1% on MSRVTT, MSVD, TGIF, and ActivityNet, respectively. Notably, extensive experiments demonstrate that Video-LLaVA mutually benefits images and videos within a unified visual representation, outperforming models designed specifically for images or videos. We aim for this work to provide modest insights into the multi-modal inputs for the LLM. Code address: href{https://github.com/PKU-YuanGroup/Video-LLaVA}
Read more10/2/2024
0
Fewer Tokens and Fewer Videos: Extending Video Understanding Abilities in Large Vision-Language Models
Shimin Chen, Yitian Yuan, Shaoxiang Chen, Zequn Jie, Lin Ma
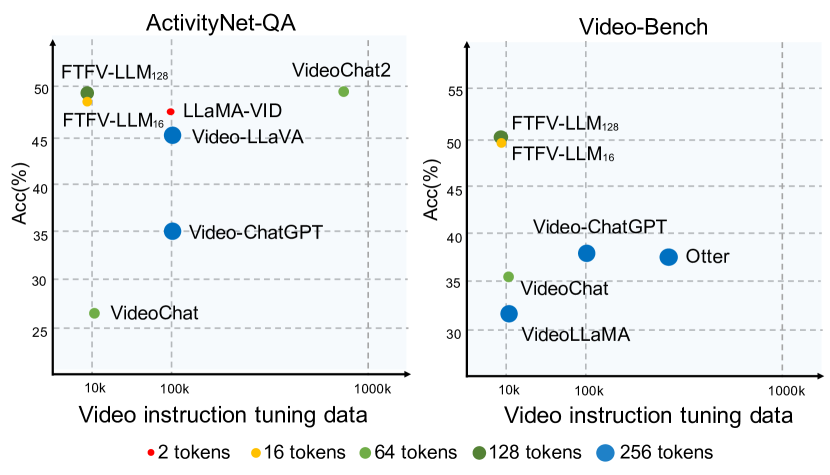
Amidst the advancements in image-based Large Vision-Language Models (image-LVLM), the transition to video-based models (video-LVLM) is hindered by the limited availability of quality video data. This paper addresses the challenge by leveraging the visual commonalities between images and videos to efficiently evolve image-LVLMs into video-LVLMs. We present a cost-effective video-LVLM that enhances model architecture, introduces innovative training strategies, and identifies the most effective types of video instruction data. Our innovative weighted token sampler significantly compresses the visual token numbers of each video frame, effectively cutting computational expenses. We also find that judiciously using just 10% of the video data, compared to prior video-LVLMs, yields impressive results during various training phases. Moreover, we delve into the influence of video instruction data in limited-resource settings, highlighting the significance of incorporating video training data that emphasizes temporal understanding to enhance model performance. The resulting Fewer Tokens and Fewer Videos LVLM (FTFV-LVLM) exhibits exceptional performance across video and image benchmarks, validating our model's design and training approaches.
Read more6/13/2024