Smart Multi-Modal Search: Contextual Sparse and Dense Embedding Integration in Adobe Express

0
Sign in to get full access
Overview
- Presents a novel approach for integrating sparse and dense embeddings in a multi-modal search system
- Developed for Adobe Express, a popular design and publishing platform
- Aims to improve search relevance and user experience by leveraging both textual and visual information
Plain English Explanation
The paper describes a technique for improving multi-modal search in Adobe Express, a design and publishing platform. The key idea is to combine two types of data representations - sparse embeddings that capture textual information, and dense embeddings that represent visual features.
By integrating these complementary embeddings, the system can more effectively understand the user's intent and retrieve the most relevant content, whether it's based on text, images, or a combination of both.
This approach helps to improve the overall search quality and product discovery experience for Adobe Express users.
Technical Explanation
The paper presents a multi-modal search system that integrates sparse textual embeddings and dense visual embeddings to enhance search relevance. The sparse embeddings capture semantic relationships between textual elements, while the dense embeddings represent visual features of the content.
The system first generates sparse and dense embeddings for the search query and the indexed content (e.g., design templates, images, etc.) using separate neural networks. It then applies a contextual integration module to combine these complementary representations, taking into account the relationships between the text and visual features.
The integrated embeddings are then used to calculate the relevance score between the query and the indexed content, allowing the system to retrieve the most relevant results for the user's search.
The authors evaluate their approach on a large-scale dataset from Adobe Express and demonstrate significant improvements in search quality compared to existing methods that only use textual or visual features in isolation.
Critical Analysis
The paper provides a comprehensive solution for enhancing multi-modal search in the context of a design and publishing platform. The authors thoughtfully address the challenge of effectively integrating textual and visual information to improve the overall search experience.
One potential limitation is the reliance on pre-trained networks for generating the sparse and dense embeddings. While this approach leverages existing models, it may be worth exploring end-to-end training of the entire system to further optimize the integration of the different modalities.
Additionally, the authors could have delved deeper into the potential biases that may arise from the multi-modal representation and how they plan to mitigate such issues to ensure fair and inclusive search results.
Overall, the paper presents a compelling and practical solution for enhancing multi-modal search in the context of a design and publishing platform, and the insights gained can be valuable for similar applications in other domains.
Conclusion
The paper introduces a novel approach for integrating sparse textual embeddings and dense visual embeddings to improve the relevance and user experience of multi-modal search in the Adobe Express platform. By leveraging the complementary information from both textual and visual features, the system can better understand the user's intent and retrieve the most relevant content, ultimately enhancing the overall search quality and product discovery capabilities.
The techniques and insights presented in this work can be valuable for researchers and practitioners working on similar challenges in multi-modal information retrieval, particularly in the context of design and publishing platforms where both textual and visual elements play a crucial role in the user experience.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Smart Multi-Modal Search: Contextual Sparse and Dense Embedding Integration in Adobe Express
Cherag Aroraa, Tracy Holloway King, Jayant Kumar, Yi Lu, Sanat Sharma, Arvind Srikantan, David Uvalle, Josep Valls-Vargas, Harsha Vardhan
As user content and queries become increasingly multi-modal, the need for effective multi-modal search systems has grown. Traditional search systems often rely on textual and metadata annotations for indexed images, while multi-modal embeddings like CLIP enable direct search using text and image embeddings. However, embedding-based approaches face challenges in integrating contextual features such as user locale and recency. Building a scalable multi-modal search system requires fine-tuning several components. This paper presents a multi-modal search architecture and a series of AB tests that optimize embeddings and multi-modal technologies in Adobe Express template search. We address considerations such as embedding model selection, the roles of embeddings in matching and ranking, and the balance between dense and sparse embeddings. Our iterative approach demonstrates how utilizing sparse, dense, and contextual features enhances short and long query search, significantly reduces null rates (over 70%), and increases click-through rates (CTR). Our findings provide insights into developing robust multi-modal search systems, thereby enhancing relevance for complex queries.
Read more8/30/2024
0
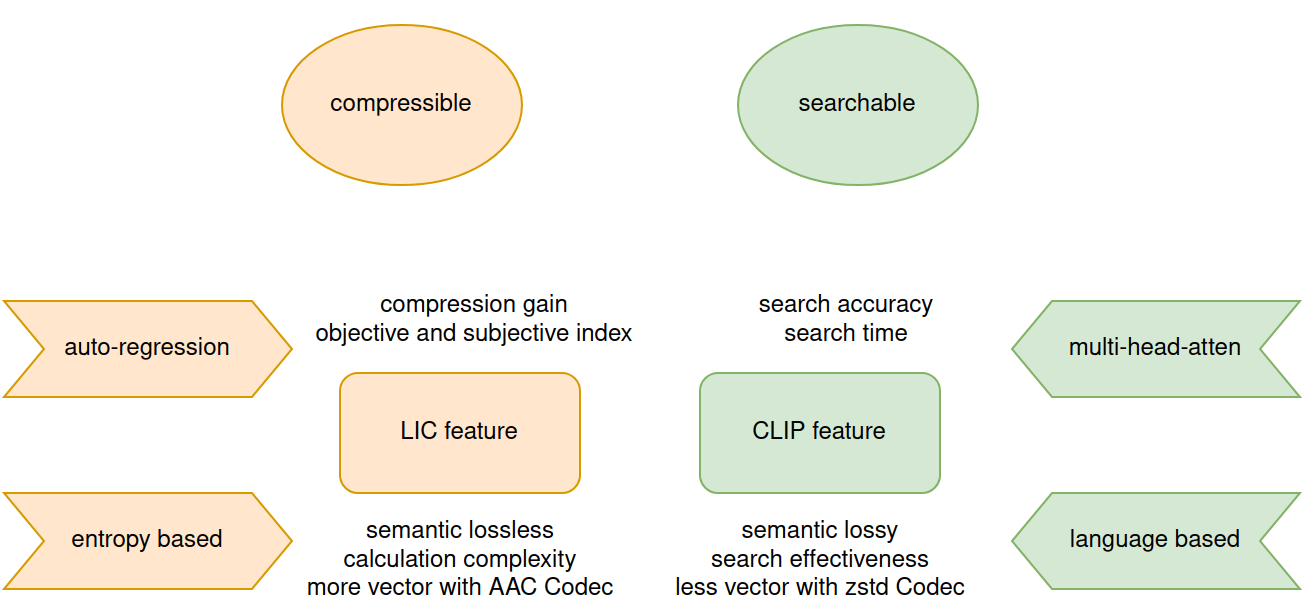
Compressible and Searchable: AI-native Multi-Modal Retrieval System with Learned Image Compression
Jixiang Luo
The burgeoning volume of digital content across diverse modalities necessitates efficient storage and retrieval methods. Conventional approaches struggle to cope with the escalating complexity and scale of multimedia data. In this paper, we proposed framework addresses this challenge by fusing AI-native multi-modal search capabilities with neural image compression. First we analyze the intricate relationship between compressibility and searchability, recognizing the pivotal role each plays in the efficiency of storage and retrieval systems. Through the usage of simple adapter is to bridge the feature of Learned Image Compression(LIC) and Contrastive Language-Image Pretraining(CLIP) while retaining semantic fidelity and retrieval of multi-modal data. Experimental evaluations on Kodak datasets demonstrate the efficacy of our approach, showcasing significant enhancements in compression efficiency and search accuracy compared to existing methodologies. Our work marks a significant advancement towards scalable and efficient multi-modal search systems in the era of big data.
Read more4/17/2024

0
Designing Interfaces for Multimodal Vector Search Applications
Owen Pendrigh Elliott, Tom Hamer, Jesse Clark
Multimodal vector search offers a new paradigm for information retrieval by exposing numerous pieces of functionality which are not possible in traditional lexical search engines. While multimodal vector search can be treated as a drop in replacement for these traditional systems, the experience can be significantly enhanced by leveraging the unique capabilities of multimodal search. Central to any information retrieval system is a user who expresses an information need, traditional user interfaces with a single search bar allow users to interact with lexical search systems effectively however are not necessarily optimal for multimodal vector search. In this paper we explore novel capabilities of multimodal vector search applications utilising CLIP models and present implementations and design patterns which better allow users to express their information needs and effectively interact with these systems in an information retrieval context.
Read more9/19/2024
0
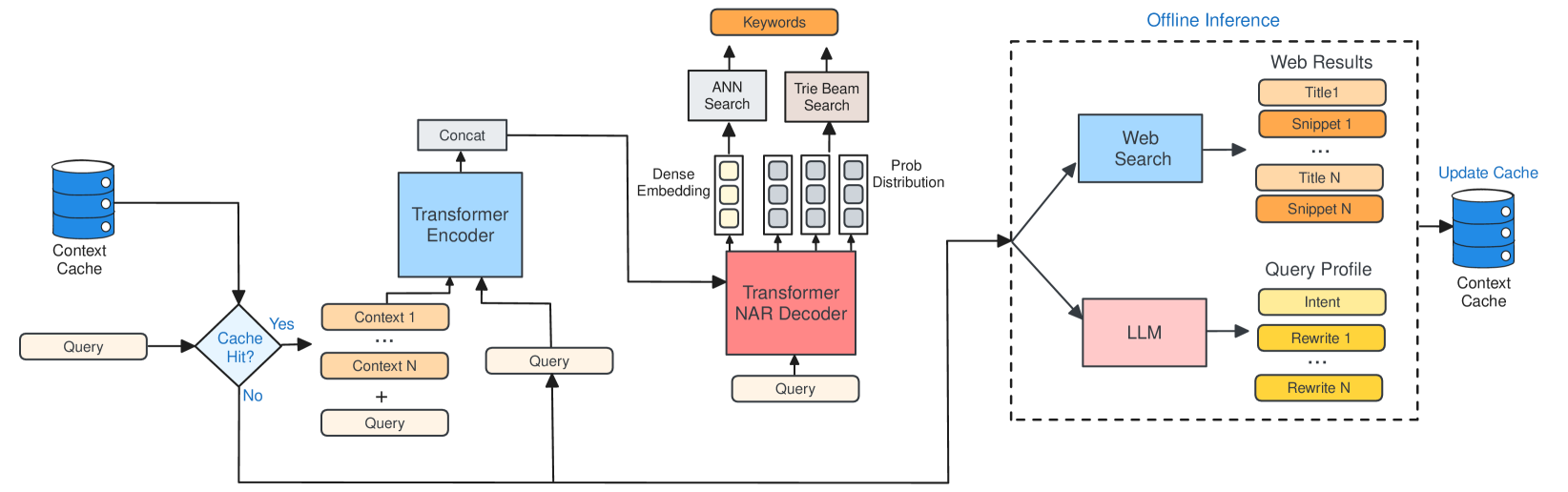
Improving Retrieval in Sponsored Search by Leveraging Query Context Signals
Akash Kumar Mohankumar, Gururaj K, Gagan Madan, Amit Singh
Accurately retrieving relevant bid keywords for user queries is critical in Sponsored Search but remains challenging, particularly for short, ambiguous queries. Existing dense and generative retrieval models often fail to capture nuanced user intent in these cases. To address this, we propose an approach to enhance query understanding by augmenting queries with rich contextual signals derived from web search results and large language models, stored in an online cache. Specifically, we use web search titles and snippets to ground queries in real-world information and utilize GPT-4 to generate query rewrites and explanations that clarify user intent. These signals are efficiently integrated through a Fusion-in-Decoder based Unity architecture, enabling both dense and generative retrieval with serving costs on par with traditional context-free models. To address scenarios where context is unavailable in the cache, we introduce context glancing, a curriculum learning strategy that improves model robustness and performance even without contextual signals during inference. Extensive offline experiments demonstrate that our context-aware approach substantially outperforms context-free models. Furthermore, online A/B testing on a prominent search engine across 160+ countries shows significant improvements in user engagement and revenue.
Read more7/22/2024