Sociodemographic Bias in Language Models: A Survey and Forward Path

0

Sign in to get full access
Overview
- This paper provides a comprehensive survey on sociodemographic bias in natural language processing (NLP) systems.
- The authors examine various types of bias, their impact, and potential mitigation strategies.
- Key areas covered include language models, task-specific NLP applications, and real-world deployments.
Plain English Explanation
Artificial intelligence (AI) systems, particularly language models, can sometimes exhibit biases that reflect the biases present in the data used to train them. This paper looks at the problem of sociodemographic bias in natural language processing (NLP) - where an AI system may treat people differently based on their age, gender, race, or other demographic characteristics.
The researchers asked large language models directly about the factors that shape their biases and then reviewed the academic literature to provide a comprehensive overview of this important issue. They cover different types of bias, how these biases can impact real-world applications like clinical decision support, and strategies that have been proposed to mitigate sociodemographic biases in NLP systems.
By understanding and addressing these biases, the goal is to develop more fair and equitable AI systems that treat all people with equal dignity and respect, regardless of their background or demographic characteristics.
Technical Explanation
The paper begins by defining different types of sociodemographic bias that can emerge in NLP systems, such as stereotype bias, over-representation bias, and under-representation bias. The authors then review empirical studies that have measured and analyzed these biases in a range of NLP tasks and applications, including language modeling, text generation, named entity recognition, and sentiment analysis.
The researchers also discuss how sociodemographic biases can manifest and impact real-world clinical decision support systems that leverage NLP techniques. They then survey various technical approaches that have been proposed to mitigate these biases, such as data augmentation, adversarial debiasing, and proactive bias testing.
Throughout the paper, the authors highlight key insights, open challenges, and directions for future research on this important topic at the intersection of AI ethics and NLP.
Critical Analysis
The paper provides a thorough and well-researched overview of sociodemographic bias in NLP, drawing on a wide range of academic literature. However, the authors acknowledge that there are still many open questions and limitations in the current state of research.
For example, they note that most existing studies have focused on bias in English language models, and there is a need for more research on bias in multilingual and non-English NLP systems. Additionally, the authors suggest that the field would benefit from more collaboration between NLP researchers and social scientists to develop a deeper understanding of the societal roots of the biases observed in these systems.
Another potential limitation is that many of the bias mitigation techniques discussed, while promising, have not yet been thoroughly evaluated in real-world deployments. Further research is needed to understand the practical effectiveness and scalability of these approaches in complex, high-stakes applications.
Overall, this paper serves as an invaluable resource for understanding the current state of research on sociodemographic bias in NLP. By highlighting key challenges and open questions, it also provides a roadmap for future work in this critical area of AI ethics and fairness.
Conclusion
This comprehensive survey paper underscores the importance of addressing sociodemographic bias in natural language processing systems. The authors demonstrate that these biases can manifest in a variety of ways, with potentially serious consequences for individuals and society.
By reviewing the current state of research and highlighting promising mitigation strategies, the paper lays the groundwork for ongoing efforts to develop more fair and equitable AI systems that treat all people with dignity and respect, regardless of their background or demographic characteristics. Continued progress in this area will be critical as NLP applications become increasingly ubiquitous in our daily lives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Sociodemographic Bias in Language Models: A Survey and Forward Path
Vipul Gupta, Pranav Narayanan Venkit, Shomir Wilson, Rebecca J. Passonneau
Sociodemographic bias in language models (LMs) has the potential for harm when deployed in real-world settings. This paper presents a comprehensive survey of the past decade of research on sociodemographic bias in LMs, organized into a typology that facilitates examining the different aims: types of bias, quantifying bias, and debiasing techniques. We track the evolution of the latter two questions, then identify current trends and their limitations, as well as emerging techniques. To guide future research towards more effective and reliable solutions, and to help authors situate their work within this broad landscape, we conclude with a checklist of open questions.
Read more8/15/2024
0
Understanding Intrinsic Socioeconomic Biases in Large Language Models
Mina Arzaghi, Florian Carichon, Golnoosh Farnadi
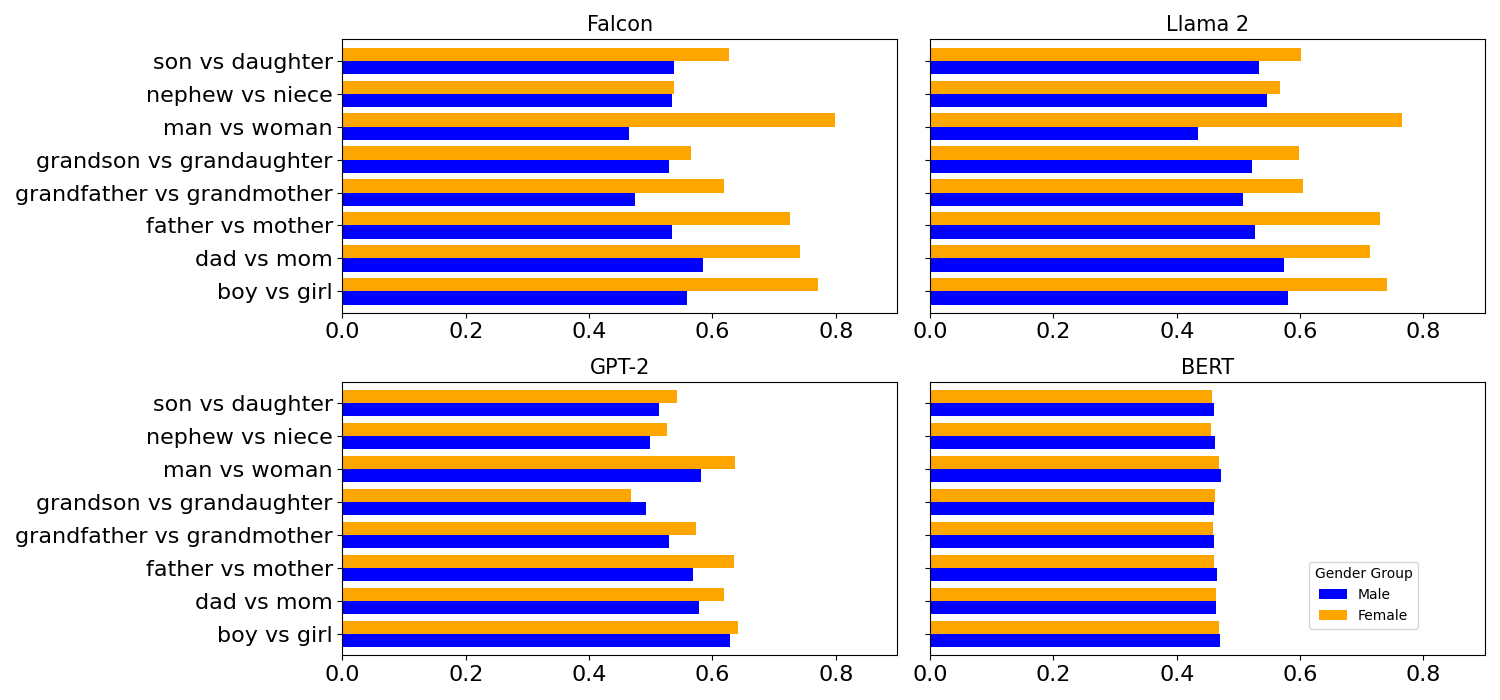
Large Language Models (LLMs) are increasingly integrated into critical decision-making processes, such as loan approvals and visa applications, where inherent biases can lead to discriminatory outcomes. In this paper, we examine the nuanced relationship between demographic attributes and socioeconomic biases in LLMs, a crucial yet understudied area of fairness in LLMs. We introduce a novel dataset of one million English sentences to systematically quantify socioeconomic biases across various demographic groups. Our findings reveal pervasive socioeconomic biases in both established models such as GPT-2 and state-of-the-art models like Llama 2 and Falcon. We demonstrate that these biases are significantly amplified when considering intersectionality, with LLMs exhibiting a remarkable capacity to extract multiple demographic attributes from names and then correlate them with specific socioeconomic biases. This research highlights the urgent necessity for proactive and robust bias mitigation techniques to safeguard against discriminatory outcomes when deploying these powerful models in critical real-world applications.
Read more5/30/2024
💬
0
Bias and Fairness in Large Language Models: A Survey
Isabel O. Gallegos, Ryan A. Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, Nesreen K. Ahmed
Rapid advancements of large language models (LLMs) have enabled the processing, understanding, and generation of human-like text, with increasing integration into systems that touch our social sphere. Despite this success, these models can learn, perpetuate, and amplify harmful social biases. In this paper, we present a comprehensive survey of bias evaluation and mitigation techniques for LLMs. We first consolidate, formalize, and expand notions of social bias and fairness in natural language processing, defining distinct facets of harm and introducing several desiderata to operationalize fairness for LLMs. We then unify the literature by proposing three intuitive taxonomies, two for bias evaluation, namely metrics and datasets, and one for mitigation. Our first taxonomy of metrics for bias evaluation disambiguates the relationship between metrics and evaluation datasets, and organizes metrics by the different levels at which they operate in a model: embeddings, probabilities, and generated text. Our second taxonomy of datasets for bias evaluation categorizes datasets by their structure as counterfactual inputs or prompts, and identifies the targeted harms and social groups; we also release a consolidation of publicly-available datasets for improved access. Our third taxonomy of techniques for bias mitigation classifies methods by their intervention during pre-processing, in-training, intra-processing, and post-processing, with granular subcategories that elucidate research trends. Finally, we identify open problems and challenges for future work. Synthesizing a wide range of recent research, we aim to provide a clear guide of the existing literature that empowers researchers and practitioners to better understand and prevent the propagation of bias in LLMs.
Read more7/16/2024
1
Ask LLMs Directly, What shapes your bias?: Measuring Social Bias in Large Language Models
Jisu Shin, Hoyun Song, Huije Lee, Soyeong Jeong, Jong C. Park
Social bias is shaped by the accumulation of social perceptions towards targets across various demographic identities. To fully understand such social bias in large language models (LLMs), it is essential to consider the composite of social perceptions from diverse perspectives among identities. Previous studies have either evaluated biases in LLMs by indirectly assessing the presence of sentiments towards demographic identities in the generated text or measuring the degree of alignment with given stereotypes. These methods have limitations in directly quantifying social biases at the level of distinct perspectives among identities. In this paper, we aim to investigate how social perceptions from various viewpoints contribute to the development of social bias in LLMs. To this end, we propose a novel strategy to intuitively quantify these social perceptions and suggest metrics that can evaluate the social biases within LLMs by aggregating diverse social perceptions. The experimental results show the quantitative demonstration of the social attitude in LLMs by examining social perception. The analysis we conducted shows that our proposed metrics capture the multi-dimensional aspects of social bias, enabling a fine-grained and comprehensive investigation of bias in LLMs.
Read more6/7/2024