The Solution for the CVPR2023 NICE Image Captioning Challenge

0
🖼️
Sign in to get full access
Overview
- This document provides guidelines for authors on how to properly format their responses using LaTeX.
- It covers important aspects such as response length and formatting instructions.
- The guidelines aim to help authors ensure their responses meet the required standards.
Plain English Explanation
The provided paper gives instructions for authors on how to format their responses using the LaTeX typesetting language. The key points include:
- Response length: Authors are given guidance on the appropriate length for their responses.
- Formatting guidelines: The paper outlines specific formatting rules authors should follow, such as using the correct document structure and LaTeX commands.
The goal is to ensure all responses are presented in a consistent and readable format, making it easier for reviewers to assess the content. By providing clear formatting instructions, the guidelines aim to improve the overall quality and clarity of the author responses.
Technical Explanation
The document begins with an introduction to the response guidelines. It then covers two main sections:
-
Response length: This section explains the expected length for author responses, providing specific guidance on the maximum number of pages allowed.
-
Formatting your Response: This section outlines the required formatting for author responses, including instructions on the document structure, font styles, and use of LaTeX commands.
The guidelines are designed to ensure a consistent and professional presentation of the author responses, which can help reviewers focus on the content rather than formatting issues.
Critical Analysis
The guidelines provide clear and detailed instructions for authors, which is helpful in ensuring a standardized format for all responses. However, the strict length requirements may pose a challenge for some authors who need more space to fully address the points raised in the review.
Additionally, the exclusive focus on LaTeX formatting could create barriers for authors who are less familiar with this typesetting language. It may be beneficial to also provide guidance on alternative formatting options, such as using a word processor with preset templates.
Overall, the guidelines seem well-intentioned, but there may be room for improvement in terms of flexibility and accessibility for a wider range of authors.
Conclusion
The provided LaTeX guidelines offer a comprehensive set of instructions for authors to format their responses in a consistent and professional manner. By adhering to these guidelines, authors can ensure their responses meet the required standards and are presented in a clear, readable format.
While the guidelines are thorough, there may be opportunities to enhance the flexibility and accessibility to accommodate authors with varying levels of LaTeX expertise. Nevertheless, the guidelines serve an important role in maintaining a high-quality and uniform presentation of author responses.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
The Solution for the CVPR2023 NICE Image Captioning Challenge
Xiangyu Wu, Yi Gao, Hailiang Zhang, Yang Yang, Weili Guo, Jianfeng Lu
In this paper, we present our solution to the New frontiers for Zero-shot Image Captioning Challenge. Different from the traditional image captioning datasets, this challenge includes a larger new variety of visual concepts from many domains (such as COVID-19) as well as various image types (photographs, illustrations, graphics). For the data level, we collect external training data from Laion-5B, a large-scale CLIP-filtered image-text dataset. For the model level, we use OFA, a large-scale visual-language pre-training model based on handcrafted templates, to perform the image captioning task. In addition, we introduce contrastive learning to align image-text pairs to learn new visual concepts in the pre-training stage. Then, we propose a similarity-bucket strategy and incorporate this strategy into the template to force the model to generate higher quality and more matching captions. Finally, by retrieval-augmented strategy, we construct a content-rich template, containing the most relevant top-k captions from other image-text pairs, to guide the model in generating semantic-rich captions. Our method ranks first on the leaderboard, achieving 105.17 and 325.72 Cider-Score in the validation and test phase, respectively.
Read more7/8/2024

0
The Solution for the CVPR2024 NICE Image Captioning Challenge
Longfei Huang, Shupeng Zhong, Xiangyu Wu, Ruoxuan Li
This report introduces a solution to the Topic 1 Zero-shot Image Captioning of 2024 NICE : New frontiers for zero-shot Image Captioning Evaluation. In contrast to NICE 2023 datasets, this challenge involves new annotations by humans with significant differences in caption style and content. Therefore, we enhance image captions effectively through retrieval augmentation and caption grading methods. At the data level, we utilize high-quality captions generated by image caption models as training data to address the gap in text styles. At the model level, we employ OFA (a large-scale visual-language pre-training model based on handcrafted templates) to perform the image captioning task. Subsequently, we propose caption-level strategy for the high-quality caption data generated by the image caption models and integrate them with retrieval augmentation strategy into the template to compel the model to generate higher quality, more matching, and semantically enriched captions based on the retrieval augmentation prompts. Our approach achieves a CIDEr score of 234.11.
Read more4/30/2024
👁️
0
Retrieval Enhanced Zero-Shot Video Captioning
Yunchuan Ma, Laiyun Qing, Guorong Li, Yuankai Qi, Quan Z. Sheng, Qingming Huang
Despite the significant progress of fully-supervised video captioning, zero-shot methods remain much less explored. In this paper, we propose to take advantage of existing pre-trained large-scale vision and language models to directly generate captions with test time adaptation. Specifically, we bridge video and text using three key models: a general video understanding model XCLIP, a general image understanding model CLIP, and a text generation model GPT-2, due to their source-code availability. The main challenge is how to enable the text generation model to be sufficiently aware of the content in a given video so as to generate corresponding captions. To address this problem, we propose using learnable tokens as a communication medium between frozen GPT-2 and frozen XCLIP as well as frozen CLIP. Differing from the conventional way to train these tokens with training data, we update these tokens with pseudo-targets of the inference data under several carefully crafted loss functions which enable the tokens to absorb video information catered for GPT-2. This procedure can be done in just a few iterations (we use 16 iterations in the experiments) and does not require ground truth data. Extensive experimental results on three widely used datasets, MSR-VTT, MSVD, and VATEX, show 4% to 20% improvements in terms of the main metric CIDEr compared to the existing state-of-the-art methods.
Read more5/14/2024
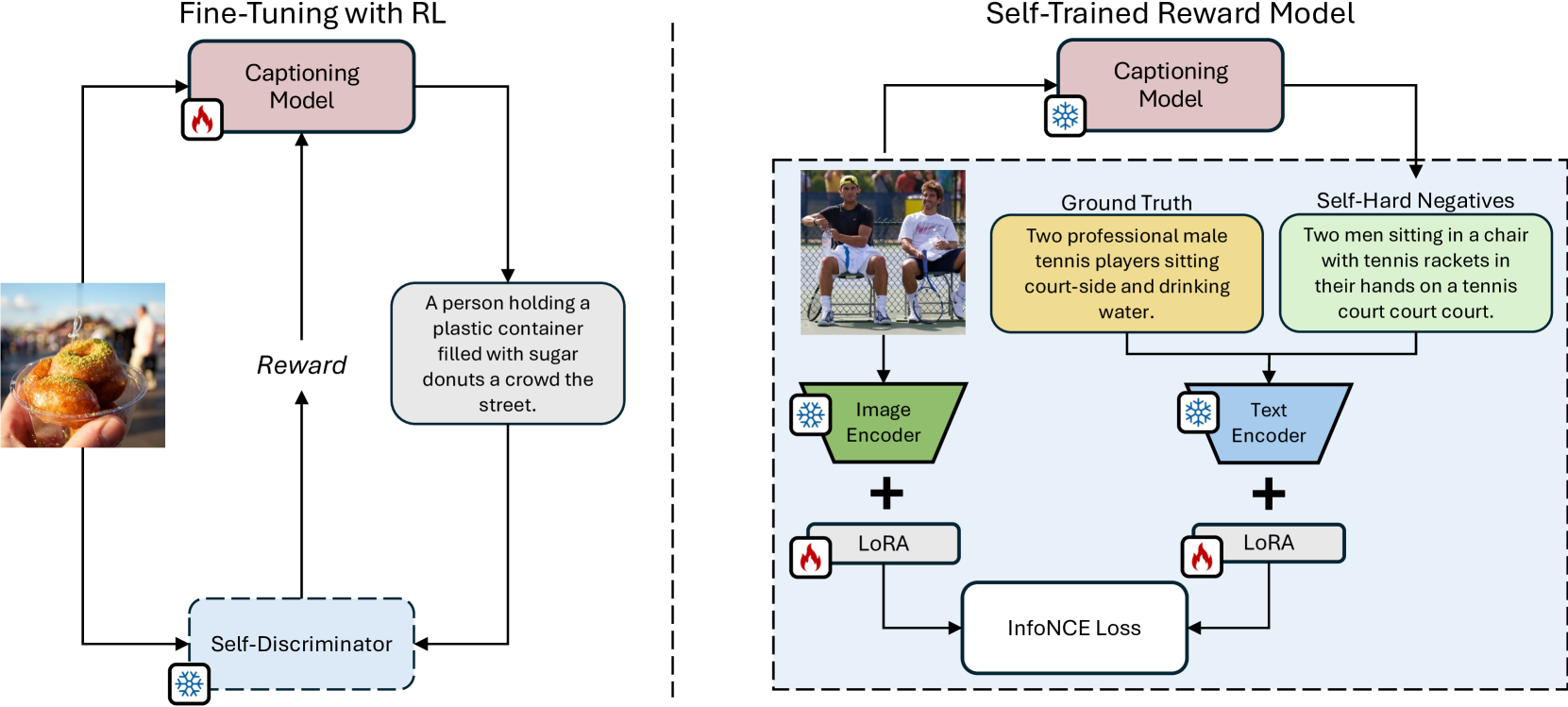
0
Fluent and Accurate Image Captioning with a Self-Trained Reward Model
Nicholas Moratelli, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara
Fine-tuning image captioning models with hand-crafted rewards like the CIDEr metric has been a classical strategy for promoting caption quality at the sequence level. This approach, however, is known to limit descriptiveness and semantic richness and tends to drive the model towards the style of ground-truth sentences, thus losing detail and specificity. On the contrary, recent attempts to employ image-text models like CLIP as reward have led to grammatically incorrect and repetitive captions. In this paper, we propose Self-Cap, a captioning approach that relies on a learnable reward model based on self-generated negatives that can discriminate captions based on their consistency with the image. Specifically, our discriminator is a fine-tuned contrastive image-text model trained to promote caption correctness while avoiding the aberrations that typically happen when training with a CLIP-based reward. To this end, our discriminator directly incorporates negative samples from a frozen captioner, which significantly improves the quality and richness of the generated captions but also reduces the fine-tuning time in comparison to using the CIDEr score as the sole metric for optimization. Experimental results demonstrate the effectiveness of our training strategy on both standard and zero-shot image captioning datasets.
Read more9/2/2024