Sparse Weight Averaging with Multiple Particles for Iterative Magnitude Pruning

0
🌀
Sign in to get full access
Overview
- Modern neural networks are growing increasingly large, making efficient architectures crucial.
- Sparse architectures offer faster inference speeds and lower memory demands.
- Iterative Magnitude Pruning (IMP) is a state-of-the-art global pruning technique, despite its simplicity.
- Recent research has found that successive IMP solutions are linearly connected without a loss barrier.
- This paper proposes Sparse Weight Averaging with Multiple Particles (SWAMP), a modification of IMP that achieves comparable performance to an ensemble of two IMP solutions.
Plain English Explanation
As neural networks grow larger, finding efficient architectures becomes more important. Sparse architectures, which have many connections removed, can run faster and use less memory than dense networks. One of the best techniques for creating sparse networks is called Iterative Magnitude Pruning (IMP). IMP works by repeatedly removing the connections with the smallest weights.
Recent research has shown that running IMP multiple times produces a series of sparse networks that are all connected in a straight line, without any barriers or jumps in performance. Building on this, the authors of this paper developed a new method called Sparse Weight Averaging with Multiple Particles (SWAMP). SWAMP trains several sparse networks in parallel, each with a different order of the training data, and then averages their weights together.
The key idea is that by averaging these "particle" networks, SWAMP can match the performance of an ensemble of two separate IMP runs, but do so more efficiently by only training a single model. The authors show through extensive experiments that SWAMP outperforms other pruning methods, achieving comparable accuracy with much sparser networks.
Technical Explanation
The authors start by noting the importance of sparse neural network architectures given the growing size of modern models. They highlight that Iterative Magnitude Pruning (IMP) remains a state-of-the-art global pruning technique, despite its simplicity.
Building on the recent finding that successive IMP solutions are linearly connected without a loss barrier, the authors propose Sparse Weight Averaging with Multiple Particles (SWAMP). For each iteration, SWAMP concurrently trains multiple sparse "particle" models using the same "matching ticket" (pruned architecture), but with different batch orders. It then weight-averages these particle models to produce a single masked model.
The authors demonstrate SWAMP's effectiveness through extensive experiments on various datasets and network architectures. They show that SWAMP consistently outperforms existing baselines, including data-independent module-aware pruning, Iterative Model Weight Averaging (IMWA), and one-shot sensitivity-aware mixed sparsity pruning, across a wide range of sparsity levels.
Critical Analysis
The paper provides a thorough and well-designed experimental evaluation of the proposed SWAMP method. However, it does not delve deeply into the potential limitations or caveats of the approach.
One area that could be explored further is the impact of the number of "particle" models used in SWAMP. The authors show results for 2, 4, and 8 particles, but it's unclear if there are diminishing returns or an optimal number. Additionally, the computational and memory overhead of training multiple models in parallel could be a practical concern, especially for resource-constrained environments.
The authors also do not discuss the potential for further improvements to the SWAMP method, such as exploring more advanced weight averaging techniques or investigating the properties of the linearly connected IMP solutions in greater depth. These could be fruitful avenues for future research.
Overall, the paper presents a compelling and effective approach to sparse network optimization, but additional analysis of the method's limitations and potential enhancements would strengthen the work.
Conclusion
This paper introduces Sparse Weight Averaging with Multiple Particles (SWAMP), a novel pruning technique that builds on the insights of Iterative Magnitude Pruning (IMP). By training multiple sparse "particle" models in parallel and then weight-averaging them, SWAMP is able to achieve performance comparable to an ensemble of two IMP solutions, but with the efficiency of a single model.
The authors demonstrate SWAMP's effectiveness across a range of datasets and network architectures, showing that it consistently outperforms other state-of-the-art pruning methods. This work highlights the importance of sparse architectures for modern neural networks and provides a practical and effective approach to achieving high performance with minimal computational and memory requirements.
As neural networks continue to grow in size and complexity, techniques like SWAMP will become increasingly crucial for deploying efficient and high-performing models in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
0
Sparse Weight Averaging with Multiple Particles for Iterative Magnitude Pruning
Moonseok Choi, Hyungi Lee, Giung Nam, Juho Lee
Given the ever-increasing size of modern neural networks, the significance of sparse architectures has surged due to their accelerated inference speeds and minimal memory demands. When it comes to global pruning techniques, Iterative Magnitude Pruning (IMP) still stands as a state-of-the-art algorithm despite its simple nature, particularly in extremely sparse regimes. In light of the recent finding that the two successive matching IMP solutions are linearly connected without a loss barrier, we propose Sparse Weight Averaging with Multiple Particles (SWAMP), a straightforward modification of IMP that achieves performance comparable to an ensemble of two IMP solutions. For every iteration, we concurrently train multiple sparse models, referred to as particles, using different batch orders yet the same matching ticket, and then weight average such models to produce a single mask. We demonstrate that our method consistently outperforms existing baselines across different sparsities through extensive experiments on various data and neural network structures.
Read more4/29/2024
📈
0
DRIVE: Dual Gradient-Based Rapid Iterative Pruning
Dhananjay Saikumar, Blesson Varghese
Modern deep neural networks (DNNs) consist of millions of parameters, necessitating high-performance computing during training and inference. Pruning is one solution that significantly reduces the space and time complexities of DNNs. Traditional pruning methods that are applied post-training focus on streamlining inference, but there are recent efforts to leverage sparsity early on by pruning before training. Pruning methods, such as iterative magnitude-based pruning (IMP) achieve up to a 90% parameter reduction while retaining accuracy comparable to the original model. However, this leads to impractical runtime as it relies on multiple train-prune-reset cycles to identify and eliminate redundant parameters. In contrast, training agnostic early pruning methods, such as SNIP and SynFlow offer fast pruning but fall short of the accuracy achieved by IMP at high sparsities. To bridge this gap, we present Dual Gradient-Based Rapid Iterative Pruning (DRIVE), which leverages dense training for initial epochs to counteract the randomness inherent at the initialization. Subsequently, it employs a unique dual gradient-based metric for parameter ranking. It has been experimentally demonstrated for VGG and ResNet architectures on CIFAR-10/100 and Tiny ImageNet, and ResNet on ImageNet that DRIVE consistently has superior performance over other training-agnostic early pruning methods in accuracy. Notably, DRIVE is 43$times$ to 869$times$ faster than IMP for pruning.
Read more4/8/2024
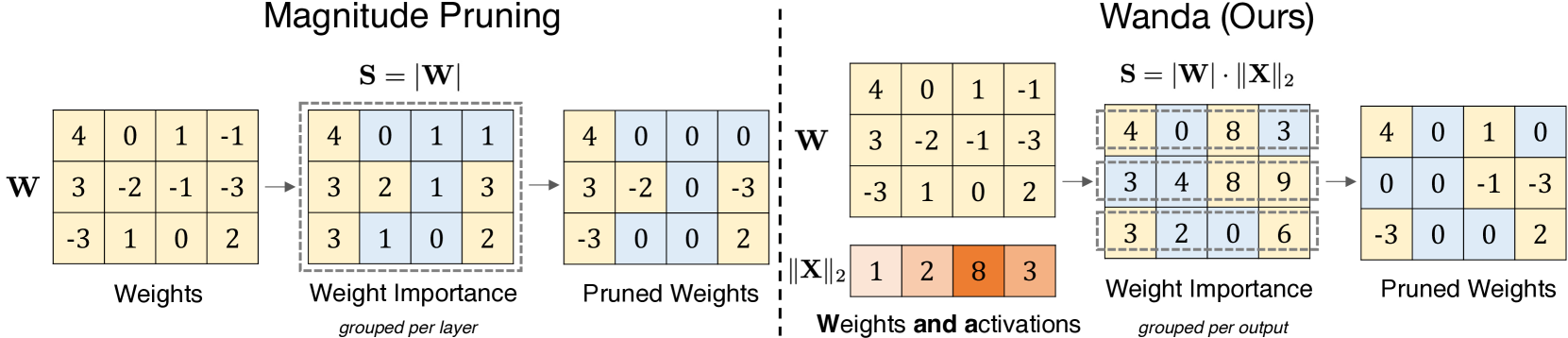
1
A Simple and Effective Pruning Approach for Large Language Models
Mingjie Sun, Zhuang Liu, Anna Bair, J. Zico Kolter
As their size increases, Large Languages Models (LLMs) are natural candidates for network pruning methods: approaches that drop a subset of network weights while striving to preserve performance. Existing methods, however, require either retraining, which is rarely affordable for billion-scale LLMs, or solving a weight reconstruction problem reliant on second-order information, which may also be computationally expensive. In this paper, we introduce a novel, straightforward yet effective pruning method, termed Wanda (Pruning by Weights and activations), designed to induce sparsity in pretrained LLMs. Motivated by the recent observation of emergent large magnitude features in LLMs, our approach prunes weights with the smallest magnitudes multiplied by the corresponding input activations, on a per-output basis. Notably, Wanda requires no retraining or weight update, and the pruned LLM can be used as is. We conduct a thorough evaluation of our method Wanda on LLaMA and LLaMA-2 across various language benchmarks. Wanda significantly outperforms the established baseline of magnitude pruning and performs competitively against recent method involving intensive weight update. Code is available at https://github.com/locuslab/wanda.
Read more5/7/2024
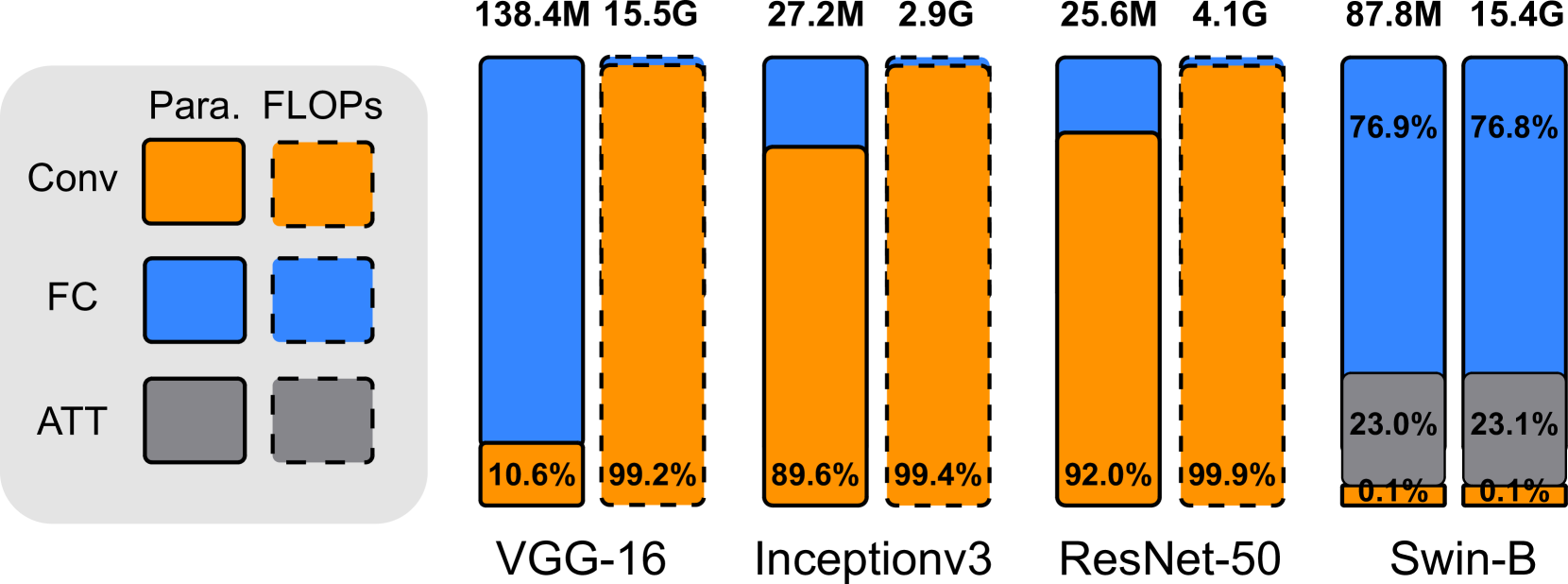
0
Data-independent Module-aware Pruning for Hierarchical Vision Transformers
Yang He, Joey Tianyi Zhou
Hierarchical vision transformers (ViTs) have two advantages over conventional ViTs. First, hierarchical ViTs achieve linear computational complexity with respect to image size by local self-attention. Second, hierarchical ViTs create hierarchical feature maps by merging image patches in deeper layers for dense prediction. However, existing pruning methods ignore the unique properties of hierarchical ViTs and use the magnitude value as the weight importance. This approach leads to two main drawbacks. First, the local attention weights are compared at a global level, which may cause some locally important weights to be pruned due to their relatively small magnitude globally. The second issue with magnitude pruning is that it fails to consider the distinct weight distributions of the network, which are essential for extracting coarse to fine-grained features at various hierarchical levels. To solve the aforementioned issues, we have developed a Data-independent Module-Aware Pruning method (DIMAP) to compress hierarchical ViTs. To ensure that local attention weights at different hierarchical levels are compared fairly in terms of their contribution, we treat them as a module and examine their contribution by analyzing their information distortion. Furthermore, we introduce a novel weight metric that is solely based on weights and does not require input images, thereby eliminating the dependence on the patch merging process. Our method validates its usefulness and strengths on Swin Transformers of different sizes on ImageNet-1k classification. Notably, the top-5 accuracy drop is only 0.07% when we remove 52.5% FLOPs and 52.7% parameters of Swin-B. When we reduce 33.2% FLOPs and 33.2% parameters of Swin-S, we can even achieve a 0.8% higher relative top-5 accuracy than the original model. Code is available at: https://github.com/he-y/Data-independent-Module-Aware-Pruning
Read more4/23/2024