Specialist vision-language models for clinical ophthalmology

0

Sign in to get full access
Overview
- This paper explores the development and evaluation of specialist vision-language models for clinical ophthalmology applications.
- The researchers created models that can accurately interpret and generate medical reports based on visual inputs like eye scans and images.
- The models were trained on large datasets of clinical ophthalmology data to develop specialized understanding and reasoning capabilities.
- Evaluation of the models showed improved performance compared to general-purpose vision-language models, indicating the value of domain-specific approaches.
Plain English Explanation
The researchers in this study wanted to create AI models that could better understand and communicate about medical images, specifically in the field of ophthalmology (eye care). They developed specialized "vision-language" models that were trained on large datasets of clinical eye data, such as scans and images.
These specialized models were able to more accurately interpret the visual information and generate relevant medical reports compared to general-purpose AI models. This is important because it shows the value of tailoring AI systems to specific domains, like healthcare, rather than relying on one-size-fits-all approaches.
By focusing the models on ophthalmology, the researchers were able to give them a deeper, more nuanced understanding of the relevant medical concepts, terminology, and reasoning. This allowed them to produce more accurate and meaningful analyses of the visual data.
Overall, this research demonstrates how AI can be leveraged to assist healthcare professionals by automating certain tasks, like generating initial medical reports, while still maintaining a high level of specialized knowledge and capabilities. This could ultimately lead to improved efficiency and patient outcomes in clinical ophthalmology.
Technical Explanation
The researchers developed a series of specialist vision-language models for clinical ophthalmology by training large language models on datasets of ophthalmology-related text and images. This allowed the models to build a strong understanding of the medical domain and learn how to interpret and generate relevant reports based on visual inputs.
The models were evaluated on various benchmarks, including disease-informed adaptation to assess their ability to reason about specific eye conditions, as well as cultural inclusive considerations to ensure they could handle diverse patient populations.
The results showed that the specialist vision-language models outperformed general-purpose models on these tasks, demonstrating the value of domain-specific approaches to vision-language modeling in healthcare applications. This highlights the potential of leveraging AI to support clinical ophthalmology.
Critical Analysis
The paper provides a thorough evaluation of the specialist vision-language models, including important considerations around disease-specific reasoning and cultural inclusivity. However, it is unclear how the models would perform in real-world clinical settings, where the data and workflows may differ from the evaluation scenarios.
Additionally, the paper does not delve into potential ethical concerns around the use of AI in healthcare, such as issues of bias, transparency, and accountability. These aspects would need to be carefully examined before deploying such systems in clinical practice.
Further research could also explore the integration of these models into existing clinical workflows, as well as their ability to handle open-ended or ambiguous visual inputs that may arise in complex medical cases.
Conclusion
This research demonstrates the potential for specialized vision-language models to enhance clinical ophthalmology by automating the interpretation and reporting of medical images. The improved performance of the domain-specific models compared to general-purpose alternatives highlights the value of tailoring AI systems to specific healthcare domains.
While there are still challenges and ethical considerations to address, this work represents an important step forward in leveraging AI to support healthcare professionals and improve patient outcomes. As the field of vision-language modeling continues to evolve, further advancements in this area could have a significant impact on the delivery of ophthalmological care.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Specialist vision-language models for clinical ophthalmology
Robbie Holland (on behalf of the PINNACLE consortium), Thomas R. P. Taylor (on behalf of the PINNACLE consortium), Christopher Holmes (on behalf of the PINNACLE consortium), Sophie Riedl (on behalf of the PINNACLE consortium), Julia Mai (on behalf of the PINNACLE consortium), Maria Patsiamanidi (on behalf of the PINNACLE consortium), Dimitra Mitsopoulou (on behalf of the PINNACLE consortium), Paul Hager (on behalf of the PINNACLE consortium), Philip Muller (on behalf of the PINNACLE consortium), Hendrik P. N. Scholl (on behalf of the PINNACLE consortium), Hrvoje Bogunovi'c (on behalf of the PINNACLE consortium), Ursula Schmidt-Erfurth (on behalf of the PINNACLE consortium), Daniel Rueckert (on behalf of the PINNACLE consortium), Sobha Sivaprasad (on behalf of the PINNACLE consortium), Andrew J. Lotery (on behalf of the PINNACLE consortium), Martin J. Menten (on behalf of the PINNACLE consortium)
Clinicians spend a significant amount of time reviewing medical images and transcribing their findings regarding patient diagnosis, referral and treatment in text form. Vision-language models (VLMs), which automatically interpret images and summarize their findings as text, have enormous potential to alleviate clinical workloads and increase patient access to high-quality medical care. While foundational models have stirred considerable interest in the medical community, it is unclear whether their general capabilities translate to real-world clinical utility. In this work, we show that foundation VLMs markedly underperform compared to practicing ophthalmologists on specialist tasks crucial to the care of patients with age-related macular degeneration (AMD). To address this, we initially identified the essential capabilities required for image-based clinical decision-making, and then developed a curriculum to selectively train VLMs in these skills. The resulting model, RetinaVLM, can be instructed to write reports that significantly outperform those written by leading foundation medical VLMs in disease staging (F1 score of 0.63 vs. 0.11) and patient referral (0.67 vs. 0.39), and approaches the diagnostic performance of junior ophthalmologists (who achieve 0.77 and 0.78 on the respective tasks). Furthermore, in a reader study involving two senior ophthalmologists with up to 32 years of experience, RetinaVLM's reports were found to be similarly correct (78.6% vs. 82.1%) and complete (both 78.6%) as reports written by junior ophthalmologists with up to 10 years of experience. These results demonstrate that our curriculum-based approach provides a blueprint for specializing generalist foundation medical VLMs to handle real-world clinical tasks.
Read more7/12/2024
0
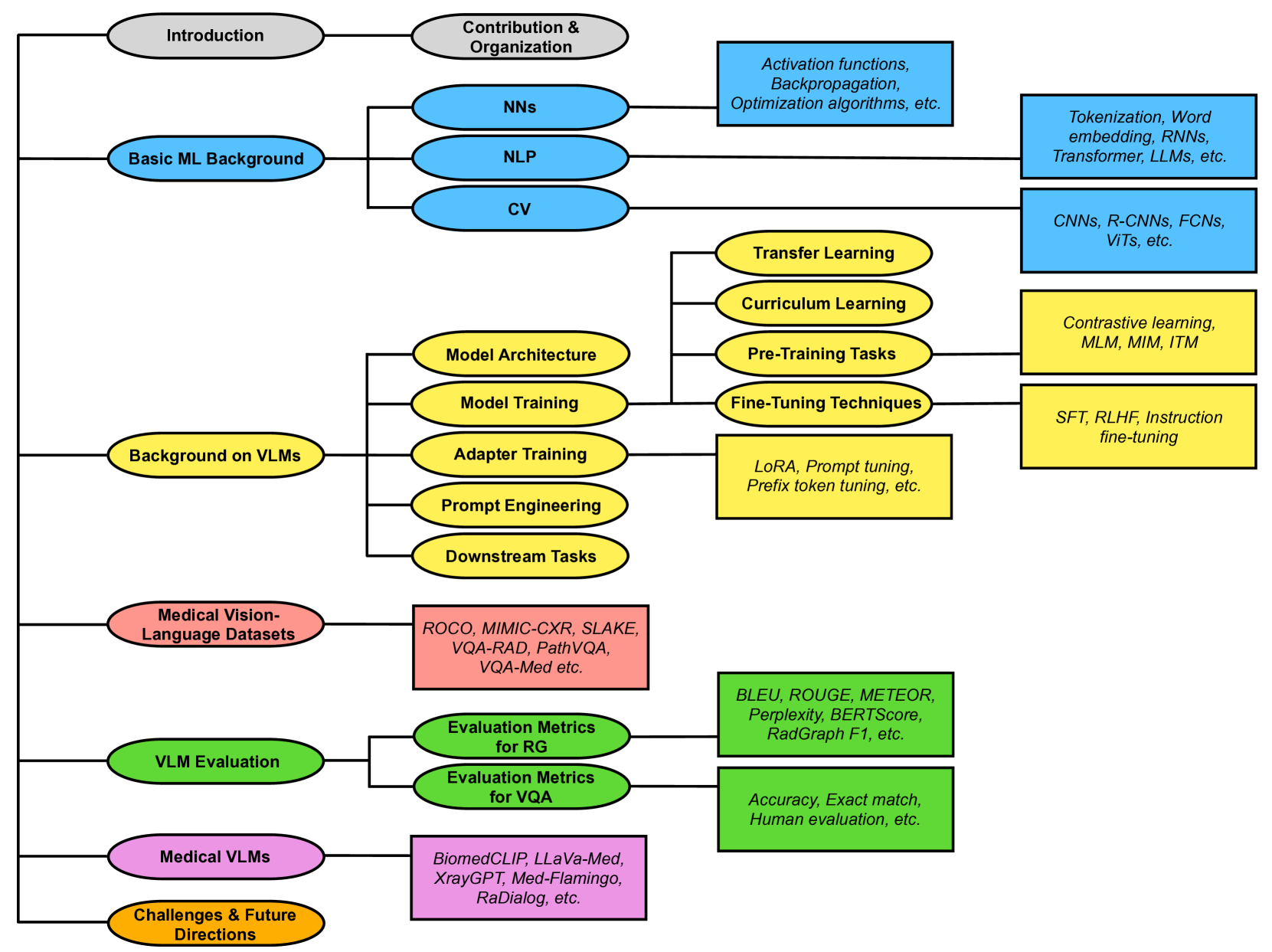
Vision-Language Models for Medical Report Generation and Visual Question Answering: A Review
Iryna Hartsock, Ghulam Rasool
Medical vision-language models (VLMs) combine computer vision (CV) and natural language processing (NLP) to analyze visual and textual medical data. Our paper reviews recent advancements in developing VLMs specialized for healthcare, focusing on models designed for medical report generation and visual question answering (VQA). We provide background on NLP and CV, explaining how techniques from both fields are integrated into VLMs to enable learning from multimodal data. Key areas we address include the exploration of medical vision-language datasets, in-depth analyses of architectures and pre-training strategies employed in recent noteworthy medical VLMs, and comprehensive discussion on evaluation metrics for assessing VLMs' performance in medical report generation and VQA. We also highlight current challenges and propose future directions, including enhancing clinical validity and addressing patient privacy concerns. Overall, our review summarizes recent progress in developing VLMs to harness multimodal medical data for improved healthcare applications.
Read more4/16/2024

0
Beyond the Hype: A dispassionate look at vision-language models in medical scenario
Yang Nan, Huichi Zhou, Xiaodan Xing, Guang Yang
Recent advancements in Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities across diverse tasks, garnering significant attention in AI communities. However, their performance and reliability in specialized domains such as medicine remain insufficiently assessed. In particular, most assessments over-concentrate in evaluating VLMs based on simple Visual Question Answering (VQA) on multi-modality data, while ignoring the in-depth characteristic of LVLMs. In this study, we introduce RadVUQA, a novel Radiological Visual Understanding and Question Answering benchmark, to comprehensively evaluate existing LVLMs. RadVUQA mainly validates LVLMs across five dimensions: 1) Anatomical understanding, assessing the models' ability to visually identify biological structures; 2) Multimodal comprehension, which involves the capability of interpreting linguistic and visual instructions to produce desired outcomes; 3) Quantitative and spatial reasoning, evaluating the models' spatial awareness and proficiency in combining quantitative analysis with visual and linguistic information; 4) Physiological knowledge, measuring the models' capability to comprehend functions and mechanisms of organs and systems; and 5) Robustness, which assesses the models' capabilities against unharmonised and synthetic data. The results indicate that both generalized LVLMs and medical-specific LVLMs have critical deficiencies with weak multimodal comprehension and quantitative reasoning capabilities. Our findings reveal the large gap between existing LVLMs and clinicians, highlighting the urgent need for more robust and intelligent LVLMs. The code and dataset will be available after the acceptance of this paper.
Read more8/19/2024

0
Vision-Language Models under Cultural and Inclusive Considerations
Antonia Karamolegkou, Phillip Rust, Yong Cao, Ruixiang Cui, Anders S{o}gaard, Daniel Hershcovich
Large vision-language models (VLMs) can assist visually impaired people by describing images from their daily lives. Current evaluation datasets may not reflect diverse cultural user backgrounds or the situational context of this use case. To address this problem, we create a survey to determine caption preferences and propose a culture-centric evaluation benchmark by filtering VizWiz, an existing dataset with images taken by people who are blind. We then evaluate several VLMs, investigating their reliability as visual assistants in a culturally diverse setting. While our results for state-of-the-art models are promising, we identify challenges such as hallucination and misalignment of automatic evaluation metrics with human judgment. We make our survey, data, code, and model outputs publicly available.
Read more7/9/2024