Specify What? Enhancing Neural Specification Synthesis by Symbolic Methods
2406.15540
0
0

Abstract
We investigate how combinations of Large Language Models (LLMs) and symbolic analyses can be used to synthesise specifications of C programs. The LLM prompts are augmented with outputs from two formal methods tools in the Frama-C ecosystem, Pathcrawler and EVA, to produce C program annotations in the specification language ACSL. We demonstrate how the addition of symbolic analysis to the workflow impacts the quality of annotations: information about input/output examples from Pathcrawler produce more context-aware annotations, while the inclusion of EVA reports yields annotations more attuned to runtime errors. In addition, we show that the method infers rather the programs intent than its behaviour, by generating specifications for buggy programs and observing robustness of the result against bugs.
Create account to get full access
Overview
- The paper "Specify What? Enhancing Neural Specification Synthesis by Symbolic Methods" proposes a novel approach to program specification synthesis that combines neural and symbolic techniques.
- The researchers developed a system that uses a large language model (LLM) to generate candidate program specifications, which are then refined and validated using symbolic methods.
- The goal is to improve the accuracy and reliability of program specification synthesis, which is a critical step in the software development process.
Plain English Explanation
The process of writing software often starts with defining the program's specification, which outlines what the program should do. Traditionally, this specification is written by human developers, but the Hysynth: Context-Free LLM Approximation Guiding Program and Guiding Enumerative Program Synthesis with Large Language Models papers have shown that large language models (LLMs) can be used to automatically generate these specifications.
However, the specifications generated by LLMs may not always be accurate or complete. The researchers in this paper wanted to improve on this by combining the power of LLMs with the precision of symbolic methods. They developed a system that uses an LLM to generate candidate specifications, and then uses symbolic techniques to refine and validate them.
The key idea is that the LLM can quickly generate a wide range of possible specifications, but the symbolic methods can then ensure that these specifications are logically consistent and accurately capture the intended behavior of the program. This helps to overcome the limitations of both approaches when used alone.
Technical Explanation
The researchers' approach, called Nesy: Is Alive and Well, LLM-Driven Symbolic, involves several steps:
-
LLM-based Specification Generation: The system uses a large language model to generate candidate program specifications based on a given problem description.
-
Symbolic Refinement: The candidate specifications are then passed to a symbolic reasoning engine, which uses techniques like constraint solving and program synthesis to refine and validate the specifications.
-
Iterative Refinement: If the symbolic engine identifies issues with the specifications, the system can go back to the LLM and generate new candidates, repeating the process until a satisfactory specification is found.
The key insight is that by combining the strengths of LLMs (fast generation of candidate solutions) and symbolic methods (rigorous validation and refinement), the system can produce more accurate and reliable program specifications than either approach could on its own.
The researchers evaluated their system on a variety of programming tasks and found that it outperformed both pure LLM-based and pure symbolic approaches in terms of specification quality and synthesis success rate.
Critical Analysis
The researchers acknowledge several limitations of their approach, including the need for a large and diverse dataset of program specifications to train the LLM, and the potential for the iterative refinement process to become computationally expensive for complex programs.
Additionally, the Investigating Symbolic Capabilities of Large Language Models paper has raised concerns about the ability of LLMs to truly understand and reason about symbolic representations, which could limit the effectiveness of the hybrid approach.
Further research is needed to address these challenges and explore the broader applicability of the Enchanting Program Specification Synthesis by Large Language technique, particularly in domains where formal verification and correctness guarantees are critical.
Conclusion
This paper presents a promising approach to program specification synthesis that combines the strengths of neural and symbolic methods. By leveraging large language models to generate candidate specifications and using symbolic techniques to refine and validate them, the researchers have developed a system that can produce more accurate and reliable program specifications than either approach alone.
While there are still some limitations and areas for further research, this work represents an important step forward in the field of automated program synthesis and could have significant implications for the software development process as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

HYSYNTH: Context-Free LLM Approximation for Guiding Program Synthesis
Shraddha Barke, Emmanuel Anaya Gonzalez, Saketh Ram Kasibatla, Taylor Berg-Kirkpatrick, Nadia Polikarpova
0
0
Many structured prediction and reasoning tasks can be framed as program synthesis problems, where the goal is to generate a program in a domain-specific language (DSL) that transforms input data into the desired output. Unfortunately, purely neural approaches, such as large language models (LLMs), often fail to produce fully correct programs in unfamiliar DSLs, while purely symbolic methods based on combinatorial search scale poorly to complex problems. Motivated by these limitations, we introduce a hybrid approach, where LLM completions for a given task are used to learn a task-specific, context-free surrogate model, which is then used to guide program synthesis. We evaluate this hybrid approach on three domains, and show that it outperforms both unguided search and direct sampling from LLMs, as well as existing program synthesizers.
5/28/2024
💬
Guiding Enumerative Program Synthesis with Large Language Models
Yixuan Li, Julian Parsert, Elizabeth Polgreen
0
0
Pre-trained Large Language Models (LLMs) are beginning to dominate the discourse around automatic code generation with natural language specifications. In contrast, the best-performing synthesizers in the domain of formal synthesis with precise logical specifications are still based on enumerative algorithms. In this paper, we evaluate the abilities of LLMs to solve formal synthesis benchmarks by carefully crafting a library of prompts for the domain. When one-shot synthesis fails, we propose a novel enumerative synthesis algorithm, which integrates calls to an LLM into a weighted probabilistic search. This allows the synthesizer to provide the LLM with information about the progress of the enumerator, and the LLM to provide the enumerator with syntactic guidance in an iterative loop. We evaluate our techniques on benchmarks from the Syntax-Guided Synthesis (SyGuS) competition. We find that GPT-3.5 as a stand-alone tool for formal synthesis is easily outperformed by state-of-the-art formal synthesis algorithms, but our approach integrating the LLM into an enumerative synthesis algorithm shows significant performance gains over both the LLM and the enumerative synthesizer alone and the winning SyGuS competition tool.
5/28/2024
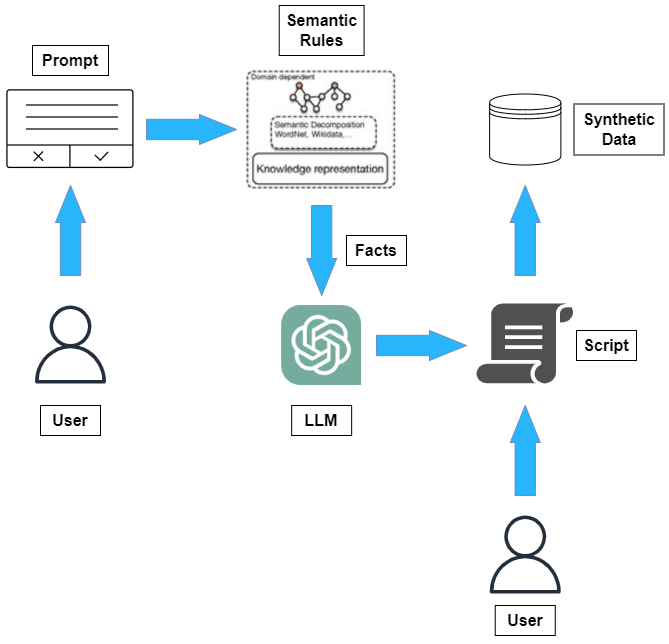
NeSy is alive and well: A LLM-driven symbolic approach for better code comment data generation and classification
Hanna Abi Akl
0
0
We present a neuro-symbolic (NeSy) workflow combining a symbolic-based learning technique with a large language model (LLM) agent to generate synthetic data for code comment classification in the C programming language. We also show how generating controlled synthetic data using this workflow fixes some of the notable weaknesses of LLM-based generation and increases the performance of classical machine learning models on the code comment classification task. Our best model, a Neural Network, achieves a Macro-F1 score of 91.412% with an increase of 1.033% after data augmentation.
5/27/2024
💬
Investigating Symbolic Capabilities of Large Language Models
Neisarg Dave, Daniel Kifer, C. Lee Giles, Ankur Mali
0
0
Prompting techniques have significantly enhanced the capabilities of Large Language Models (LLMs) across various complex tasks, including reasoning, planning, and solving math word problems. However, most research has predominantly focused on language-based reasoning and word problems, often overlooking the potential of LLMs in handling symbol-based calculations and reasoning. This study aims to bridge this gap by rigorously evaluating LLMs on a series of symbolic tasks, such as addition, multiplication, modulus arithmetic, numerical precision, and symbolic counting. Our analysis encompasses eight LLMs, including four enterprise-grade and four open-source models, of which three have been pre-trained on mathematical tasks. The assessment framework is anchored in Chomsky's Hierarchy, providing a robust measure of the computational abilities of these models. The evaluation employs minimally explained prompts alongside the zero-shot Chain of Thoughts technique, allowing models to navigate the solution process autonomously. The findings reveal a significant decline in LLMs' performance on context-free and context-sensitive symbolic tasks as the complexity, represented by the number of symbols, increases. Notably, even the fine-tuned GPT3.5 exhibits only marginal improvements, mirroring the performance trends observed in other models. Across the board, all models demonstrated a limited generalization ability on these symbol-intensive tasks. This research underscores LLMs' challenges with increasing symbolic complexity and highlights the need for specialized training, memory and architectural adjustments to enhance their proficiency in symbol-based reasoning tasks.
5/24/2024