A Survey of Pipeline Tools for Data Engineering

0

Sign in to get full access
Overview
- Provides a comprehensive survey of various data engineering pipeline tools
- Explores the key features, capabilities, and use cases of different pipeline tools
- Aims to help data practitioners and researchers understand the landscape of pipeline technologies
Plain English Explanation
This paper offers a detailed overview of the different tools available for building data engineering pipelines. Data engineering pipelines are the processes and systems used to collect, transform, and prepare data for analysis or use in machine learning models. The paper examines the key features and capabilities of various pipeline tools, including Towards Interactively Improving ML Data Preparation Code, Good Tools are Half the Work: Tool Usage in Data Science, and AI Competitions, Benchmarks, and Dataset Development.
The goal is to help data practitioners and researchers understand the landscape of available pipeline tools and make informed decisions about which ones might be best suited for their specific needs and use cases. By providing a comprehensive overview, the paper aims to empower data teams to select and implement the right pipeline tools to streamline their data engineering workflows and ultimately improve the quality and reliability of their data-driven insights.
Technical Explanation
The paper begins by defining the concept of data engineering pipelines and highlighting their importance in modern data-driven organizations. It then outlines the methodology used to survey and evaluate a wide range of pipeline tools, including both open-source and commercial offerings.
The core of the paper is a detailed analysis of the key features and capabilities of these pipeline tools, including their support for different data sources and formats, data transformation and processing capabilities, scalability and performance, integration with other tools and platforms, and overall ease of use and deployment. The analysis also covers specialized tools like FeatureEnvi: Visual Analytics for Feature Engineering Using Stepwise and the Framework to Model ML Engineering Processes.
Through this comprehensive evaluation, the paper aims to provide data practitioners with a clear understanding of the strengths, weaknesses, and trade-offs of different pipeline tools, enabling them to make more informed decisions about which tool or combination of tools might be most suitable for their specific data engineering needs and requirements.
Critical Analysis
The paper acknowledges that the field of data engineering pipelines is rapidly evolving, with new tools and technologies constantly emerging. As such, the authors note that their survey and analysis may not be entirely comprehensive or up-to-date. They also highlight the inherent subjectivity involved in evaluating and comparing the various pipeline tools, as individual users may have different priorities and preferences.
Additionally, the paper does not delve deeply into the technical implementation details or performance benchmarks of the surveyed tools, which may be of interest to more technically-inclined readers. The focus is primarily on the high-level features and capabilities, which could be seen as a limitation for those seeking a more in-depth technical understanding.
Nevertheless, the paper provides a valuable and timely overview of the data engineering pipeline landscape, which can serve as a useful starting point for data practitioners and researchers looking to navigate the increasingly complex ecosystem of pipeline tools and technologies.
Conclusion
This paper offers a comprehensive survey of the various pipeline tools available for data engineering, providing data practitioners with a detailed understanding of the key features, capabilities, and trade-offs of different pipeline solutions. By highlighting the strengths and weaknesses of these tools, the paper empowers data teams to make more informed decisions about which pipeline technologies to adopt and implement, ultimately leading to more efficient and effective data engineering workflows. The paper's insights can also inform future research and development efforts in the data engineering pipeline space, driving continued innovation and progress in this critical domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Survey of Pipeline Tools for Data Engineering
Anthony Mbata, Yaji Sripada, Mingjun Zhong
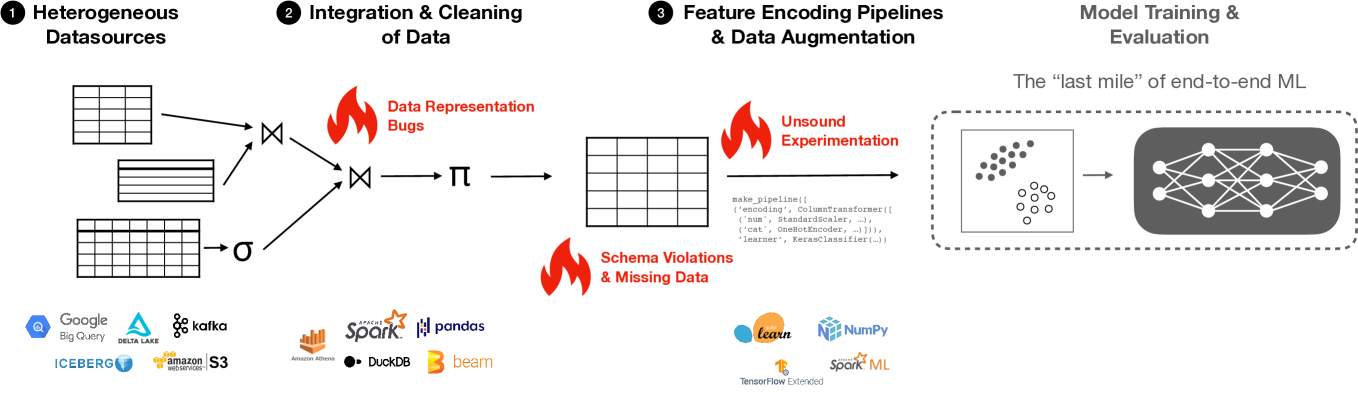
Currently, a variety of pipeline tools are available for use in data engineering. Data scientists can use these tools to resolve data wrangling issues associated with data and accomplish some data engineering tasks from data ingestion through data preparation to utilization as input for machine learning (ML). Some of these tools have essential built-in components or can be combined with other tools to perform desired data engineering operations. While some tools are wholly or partly commercial, several open-source tools are available to perform expert-level data engineering tasks. This survey examines the broad categories and examples of pipeline tools based on their design and data engineering intentions. These categories are Extract Transform Load/Extract Load Transform (ETL/ELT), pipelines for Data Integration, Ingestion, and Transformation, Data Pipeline Orchestration and Workflow Management, and Machine Learning Pipelines. The survey also provides a broad outline of the utilization with examples within these broad groups and finally, a discussion is presented with case studies indicating the usage of pipeline tools for data engineering. The studies present some first-user application experiences with sample data, some complexities of the applied pipeline, and a summary note of approaches to using these tools to prepare data for machine learning.
Read more6/21/2024
0
Instrumentation and Analysis of Native ML Pipelines via Logical Query Plans
Stefan Grafberger
Machine Learning (ML) is increasingly used to automate impactful decisions, which leads to concerns regarding their correctness, reliability, and fairness. We envision highly-automated software platforms to assist data scientists with developing, validating, monitoring, and analysing their ML pipelines. In contrast to existing work, our key idea is to extract logical query plans from ML pipeline code relying on popular libraries. Based on these plans, we automatically infer pipeline semantics and instrument and rewrite the ML pipelines to enable diverse use cases without requiring data scientists to manually annotate or rewrite their code. First, we developed such an abstract ML pipeline representation together with machinery to extract it from Python code. Next, we used this representation to efficiently instrument static ML pipelines and apply provenance tracking, which enables lightweight screening for common data preparation issues. Finally, we built machinery to automatically rewrite ML pipelines to perform more advanced what-if analyses and proposed using multi-query optimisation for the resulting workloads. In future work, we aim to interactively assist data scientists as they work on their ML pipelines.
Read more7/11/2024

0
Statistical Test for Data Analysis Pipeline by Selective Inference
Tomohiro Shiraishi, Tatsuya Matsukawa, Shuichi Nishino, Ichiro Takeuchi
A data analysis pipeline is a structured sequence of processing steps that transforms raw data into meaningful insights by effectively integrating various analysis algorithms. In this paper, we propose a novel statistical test designed to assess the statistical significance of data analysis pipelines. Our approach allows for the systematic development of valid statistical tests applicable to any data analysis pipeline configuration composed of a set of data analysis components. We have developed this framework by adapting selective inference, which has gained recent attention as a new statistical inference technique for data-driven hypotheses. The proposed statistical test is theoretically designed to control the type I error at the desired significance level in finite samples. As examples, we consider a class of pipelines composed of three missing value imputation algorithms, three outlier detection algorithms, and three feature selection algorithms. We confirm the validity of our statistical test through experiments with both synthetic and real data for this class of data analysis pipelines. Additionally, we present an implementation framework that facilitates testing across any configuration of data analysis pipelines in this class without extra implementation costs.
Read more6/28/2024
📊
0
Towards Interactively Improving ML Data Preparation Code via Shadow Pipelines
Stefan Grafberger, Paul Groth, Sebastian Schelter
Data scientists develop ML pipelines in an iterative manner: they repeatedly screen a pipeline for potential issues, debug it, and then revise and improve its code according to their findings. However, this manual process is tedious and error-prone. Therefore, we propose to support data scientists during this development cycle with automatically derived interactive suggestions for pipeline improvements. We discuss our vision to generate these suggestions with so-called shadow pipelines, hidden variants of the original pipeline that modify it to auto-detect potential issues, try out modifications for improvements, and suggest and explain these modifications to the user. We envision to apply incremental view maintenance-based optimisations to ensure low-latency computation and maintenance of the shadow pipelines. We conduct preliminary experiments to showcase the feasibility of our envisioned approach and the potential benefits of our proposed optimisations.
Read more5/1/2024