Stealthy Imitation: Reward-guided Environment-free Policy Stealing
2405.07004
0
0
🛸
Abstract
Deep reinforcement learning policies, which are integral to modern control systems, represent valuable intellectual property. The development of these policies demands considerable resources, such as domain expertise, simulation fidelity, and real-world validation. These policies are potentially vulnerable to model stealing attacks, which aim to replicate their functionality using only black-box access. In this paper, we propose Stealthy Imitation, the first attack designed to steal policies without access to the environment or knowledge of the input range. This setup has not been considered by previous model stealing methods. Lacking access to the victim's input states distribution, Stealthy Imitation fits a reward model that allows to approximate it. We show that the victim policy is harder to imitate when the distribution of the attack queries matches that of the victim. We evaluate our approach across diverse, high-dimensional control tasks and consistently outperform prior data-free approaches adapted for policy stealing. Lastly, we propose a countermeasure that significantly diminishes the effectiveness of the attack.
Create account to get full access
Overview
- Deep reinforcement learning policies are valuable intellectual property that power modern control systems.
- Developing these policies requires significant resources, such as domain expertise, simulation fidelity, and real-world validation.
- Policies are vulnerable to model stealing attacks, which aim to replicate their functionality using only black-box access.
- This paper proposes "Stealthy Imitation," a novel attack designed to steal policies without access to the environment or knowledge of the input range.
Plain English Explanation
Deep reinforcement learning policies are a key component of many advanced control systems, such as those used in robotics or autonomous vehicles. These policies represent significant intellectual property, as they are the result of considerable development efforts involving domain expertise, realistic simulations, and real-world testing.
However, these valuable policies are at risk of being stolen through "model stealing" attacks. In a model stealing attack, an attacker tries to replicate the functionality of a policy by only having access to the policy's outputs, without knowing the details of how the policy was developed or the range of inputs it expects.
This paper introduces a new attack called "Stealthy Imitation" that is designed to steal policies even in situations where the attacker doesn't have access to the environment the policy was trained in or knowledge of the expected input range. To do this, the attack fits a reward model that allows it to approximate the distribution of the victim policy's input states.
The key insight is that the victim policy is harder to imitate when the distribution of the attacker's queries matches the distribution of the victim's input states. This paper shows that Stealthy Imitation outperforms previous data-free approaches to policy stealing across a variety of high-dimensional control tasks.
Lastly, the paper proposes a countermeasure that can significantly reduce the effectiveness of the Stealthy Imitation attack.
Technical Explanation
The paper proposes a novel model stealing attack called "Stealthy Imitation" that is designed to steal deep reinforcement learning policies without access to the environment or knowledge of the input range.
Previous model stealing methods have assumed the attacker has access to the environment or the input distribution of the victim policy. In contrast, Stealthy Imitation addresses a more challenging setup where the attacker lacks this information.
To overcome this, Stealthy Imitation fits a reward model that allows it to approximate the distribution of the victim policy's input states. The key insight is that the victim policy is harder to imitate when the distribution of the attacker's queries matches the distribution of the victim's input states.
The paper evaluates Stealthy Imitation across diverse, high-dimensional control tasks and shows that it consistently outperforms prior data-free approaches adapted for policy stealing. This includes imitation learning and adversarial inverse reinforcement learning techniques.
Finally, the paper proposes a countermeasure that can significantly diminish the effectiveness of the Stealthy Imitation attack. This countermeasure is designed to reduce the risk of assistive reinforcement learning policies by making it harder for an attacker to match the distribution of the victim's input states.
Critical Analysis
The paper presents a novel and technically sophisticated attack on deep reinforcement learning policies, which are an important component of many modern control systems. The authors demonstrate the effectiveness of their Stealthy Imitation approach across a range of challenging control tasks, outperforming previous data-free policy stealing methods.
One potential limitation of the research is that it assumes the attacker has black-box access to the victim policy, which may not always be the case in real-world scenarios. Additionally, the proposed countermeasure, while effective, may have its own limitations or unintended consequences that are not fully explored in the paper.
It would also be valuable to see the authors address potential ethical concerns around the misuse of model stealing attacks, and to discuss the implications of this work for the broader challenge of securing valuable AI-powered systems against malicious actors.
Overall, this paper makes an important contribution to the growing body of research on model stealing and the security of deep reinforcement learning systems. However, as with any powerful technique, there are valid concerns about its potential for abuse that warrant further discussion and mitigation strategies.
Conclusion
This paper introduces Stealthy Imitation, a novel model stealing attack designed to steal deep reinforcement learning policies without access to the environment or knowledge of the input range. The attack outperforms previous data-free approaches by fitting a reward model to approximate the distribution of the victim policy's input states.
The research highlights the vulnerability of valuable intellectual property represented by deep reinforcement learning policies, and the need for robust countermeasures to protect these critical components of modern control systems. While the proposed attack is technically sophisticated, the authors also present a countermeasure that can significantly reduce its effectiveness.
As AI systems become increasingly integral to essential technologies, ensuring their security against malicious attacks will be crucial. This paper contributes valuable insights to this important challenge, but also raises ethical questions about the responsible development and deployment of these powerful techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Behavior-Targeted Attack on Reinforcement Learning with Limited Access to Victim's Policy
Shojiro Yamabe, Kazuto Fukuchi, Ryoma Senda, Jun Sakuma
0
0
This study considers the attack on reinforcement learning agents where the adversary aims to control the victim's behavior as specified by the adversary by adding adversarial modifications to the victim's state observation. While some attack methods reported success in manipulating the victim agent's behavior, these methods often rely on environment-specific heuristics. In addition, all existing attack methods require white-box access to the victim's policy. In this study, we propose a novel method for manipulating the victim agent in the black-box (i.e., the adversary is allowed to observe the victim's state and action only) and no-box (i.e., the adversary is allowed to observe the victim's state only) setting without requiring environment-specific heuristics. Our attack method is formulated as a bi-level optimization problem that is reduced to a distribution matching problem and can be solved by an existing imitation learning algorithm in the black-box and no-box settings. Empirical evaluations on several reinforcement learning benchmarks show that our proposed method has superior attack performance to baselines.
6/7/2024

EvIL: Evolution Strategies for Generalisable Imitation Learning
Silvia Sapora, Gokul Swamy, Chris Lu, Yee Whye Teh, Jakob Nicolaus Foerster
0
0
Often times in imitation learning (IL), the environment we collect expert demonstrations in and the environment we want to deploy our learned policy in aren't exactly the same (e.g. demonstrations collected in simulation but deployment in the real world). Compared to policy-centric approaches to IL like behavioural cloning, reward-centric approaches like inverse reinforcement learning (IRL) often better replicate expert behaviour in new environments. This transfer is usually performed by optimising the recovered reward under the dynamics of the target environment. However, (a) we find that modern deep IL algorithms frequently recover rewards which induce policies far weaker than the expert, even in the same environment the demonstrations were collected in. Furthermore, (b) these rewards are often quite poorly shaped, necessitating extensive environment interaction to optimise effectively. We provide simple and scalable fixes to both of these concerns. For (a), we find that reward model ensembles combined with a slightly different training objective significantly improves re-training and transfer performance. For (b), we propose a novel evolution-strategies based method EvIL to optimise for a reward-shaping term that speeds up re-training in the target environment, closing a gap left open by the classical theory of IRL. On a suite of continuous control tasks, we are able to re-train policies in target (and source) environments more interaction-efficiently than prior work.
6/19/2024
🌀
Efficient Imitation Learning with Conservative World Models
Victor Kolev, Rafael Rafailov, Kyle Hatch, Jiajun Wu, Chelsea Finn
0
0
We tackle the problem of policy learning from expert demonstrations without a reward function. A central challenge in this space is that these policies fail upon deployment due to issues of distributional shift, environment stochasticity, or compounding errors. Adversarial imitation learning alleviates this issue but requires additional on-policy training samples for stability, which presents a challenge in realistic domains due to inefficient learning and high sample complexity. One approach to this issue is to learn a world model of the environment, and use synthetic data for policy training. While successful in prior works, we argue that this is sub-optimal due to additional distribution shifts between the learned model and the real environment. Instead, we re-frame imitation learning as a fine-tuning problem, rather than a pure reinforcement learning one. Drawing theoretical connections to offline RL and fine-tuning algorithms, we argue that standard online world model algorithms are not well suited to the imitation learning problem. We derive a principled conservative optimization bound and demonstrate empirically that it leads to improved performance on two very challenging manipulation environments from high-dimensional raw pixel observations. We set a new state-of-the-art performance on the Franka Kitchen environment from images, requiring only 10 demos on no reward labels, as well as solving a complex dexterity manipulation task.
5/24/2024
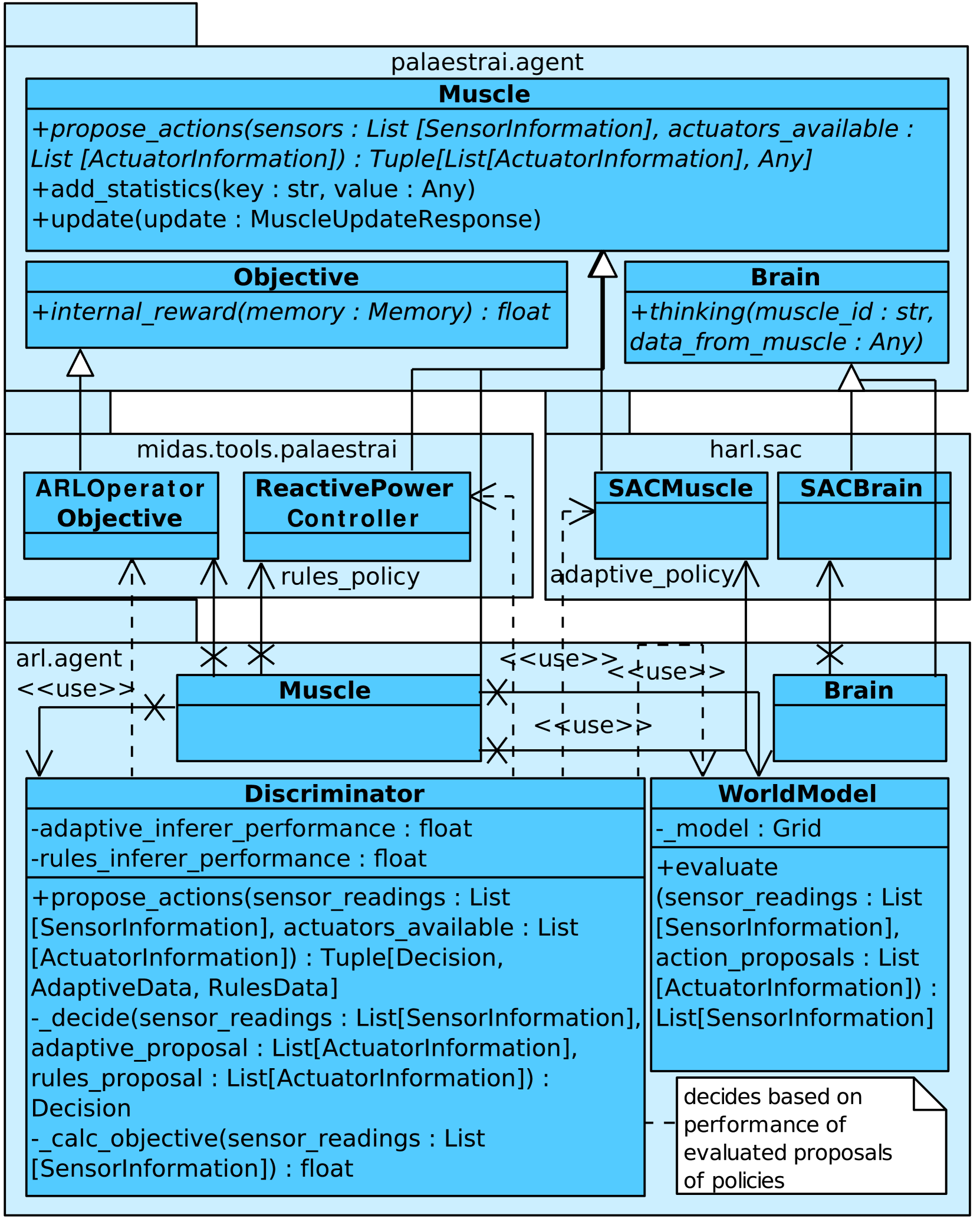
Imitation Game: A Model-based and Imitation Learning Deep Reinforcement Learning Hybrid
Eric MSP Veith, Torben Logemann, Aleksandr Berezin, Arlena Well{ss}ow, Stephan Balduin
0
0
Autonomous and learning systems based on Deep Reinforcement Learning have firmly established themselves as a foundation for approaches to creating resilient and efficient Cyber-Physical Energy Systems. However, most current approaches suffer from two distinct problems: Modern model-free algorithms such as Soft Actor Critic need a high number of samples to learn a meaningful policy, as well as a fallback to ward against concept drifts (e. g., catastrophic forgetting). In this paper, we present the work in progress towards a hybrid agent architecture that combines model-based Deep Reinforcement Learning with imitation learning to overcome both problems.
4/3/2024