StoryImager: A Unified and Efficient Framework for Coherent Story Visualization and Completion
2404.05979
0
0

Abstract
Story visualization aims to generate a series of realistic and coherent images based on a storyline. Current models adopt a frame-by-frame architecture by transforming the pre-trained text-to-image model into an auto-regressive manner. Although these models have shown notable progress, there are still three flaws. 1) The unidirectional generation of auto-regressive manner restricts the usability in many scenarios. 2) The additional introduced story history encoders bring an extremely high computational cost. 3) The story visualization and continuation models are trained and inferred independently, which is not user-friendly. To these ends, we propose a bidirectional, unified, and efficient framework, namely StoryImager. The StoryImager enhances the storyboard generative ability inherited from the pre-trained text-to-image model for a bidirectional generation. Specifically, we introduce a Target Frame Masking Strategy to extend and unify different story image generation tasks. Furthermore, we propose a Frame-Story Cross Attention Module that decomposes the cross attention for local fidelity and global coherence. Moreover, we design a Contextual Feature Extractor to extract contextual information from the whole storyline. The extensive experimental results demonstrate the excellent performance of our StoryImager. The code is available at https://github.com/tobran/StoryImager.
Create account to get full access
Overview
- StoryImager is a framework that enables coherent story visualization and completion.
- It combines natural language processing, computer vision, and generative models to generate images and text that tell a cohesive narrative.
- The system can take textual descriptions as input and produce a series of related images, or alternatively, can generate text to continue a visual story.
Plain English Explanation
StoryImager is a tool that helps create visual stories. It can take a written description and turn it into a series of related images that tell a coherent narrative. Conversely, it can also generate text to continue a visual story.
The system uses a combination of natural language processing, computer vision, and generative models to achieve this. It's designed to produce images and text that flow logically and coherently, rather than just random pieces.
This could be useful for things like interactive storytelling, creative writing, or even generating visual content for games or movies. By automating the process of turning descriptions into visuals, and vice versa, StoryImager aims to make the process of crafting compelling narratives more efficient and accessible.
Technical Explanation
StoryImager uses a multi-modal transformer architecture to jointly model text and images. The model is trained on large datasets of text-image pairs, allowing it to learn the associations between language and visual concepts.
For story visualization, the system takes a textual description as input and generates a sequence of related images that depict the narrative. This is achieved through a conditional generative model that generates each image based on the preceding text and images.
Conversely, for story completion, the model is given an initial set of images and must generate coherent text to continue the visual story. This is done by using the images as conditioning information for a language model, which predicts the next logical sentence or paragraph.
The researchers evaluate StoryImager on a variety of benchmark datasets and show that it outperforms previous approaches in terms of coherence, realism, and story progression.
Critical Analysis
The authors acknowledge that StoryImager has some limitations. For example, the model may struggle with generating images or text that deviate significantly from the training data, and the system does not currently incorporate any explicit reasoning about the causal or temporal relationships between events in a story.
Additionally, while the results demonstrate the system's ability to generate coherent narratives, there may be concerns about bias or lack of diversity in the generated content, which are important considerations for real-world applications.
Further research could explore ways to make the system more flexible and adaptable, perhaps by incorporating more structured knowledge about narrative structure or by using reinforcement learning to fine-tune the model based on human feedback.
Conclusion
StoryImager represents an exciting advance in the field of generative storytelling, combining natural language processing, computer vision, and deep learning to enable the automated creation of coherent visual and textual narratives.
This technology could have a range of applications, from interactive entertainment to educational tools and beyond. As the field of AI-generated content continues to evolve, frameworks like StoryImager will likely play an increasingly important role in shaping how we create and consume stories in the digital age.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
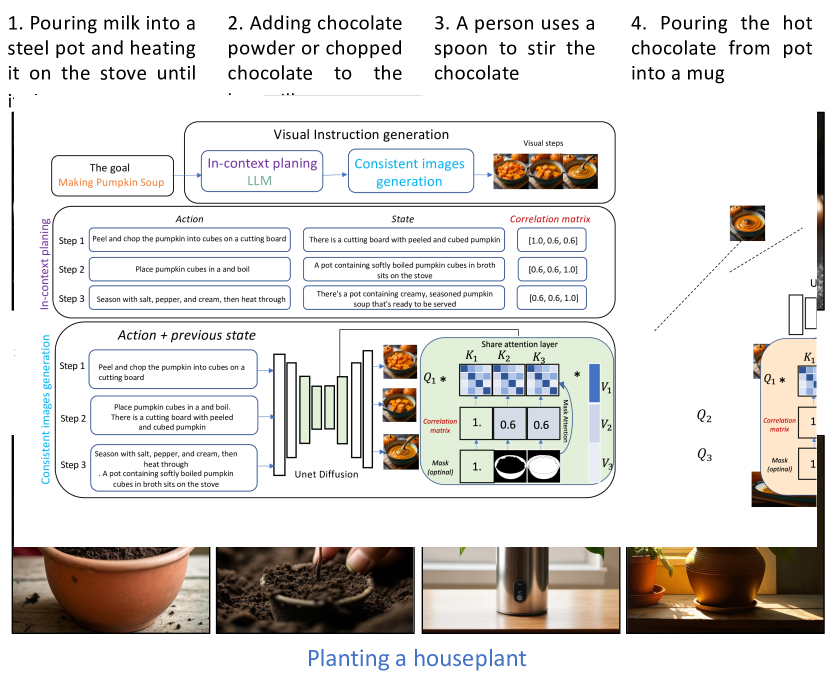
Coherent Zero-Shot Visual Instruction Generation
Quynh Phung, Songwei Ge, Jia-Bin Huang
0
0
Despite the advances in text-to-image synthesis, particularly with diffusion models, generating visual instructions that require consistent representation and smooth state transitions of objects across sequential steps remains a formidable challenge. This paper introduces a simple, training-free framework to tackle the issues, capitalizing on the advancements in diffusion models and large language models (LLMs). Our approach systematically integrates text comprehension and image generation to ensure visual instructions are visually appealing and maintain consistency and accuracy throughout the instruction sequence. We validate the effectiveness by testing multi-step instructions and comparing the text alignment and consistency with several baselines. Our experiments show that our approach can visualize coherent and visually pleasing instructions
6/11/2024

Unified Editing of Panorama, 3D Scenes, and Videos Through Disentangled Self-Attention Injection
Gihyun Kwon, Jangho Park, Jong Chul Ye
0
0
While text-to-image models have achieved impressive capabilities in image generation and editing, their application across various modalities often necessitates training separate models. Inspired by existing method of single image editing with self attention injection and video editing with shared attention, we propose a novel unified editing framework that combines the strengths of both approaches by utilizing only a basic 2D image text-to-image (T2I) diffusion model. Specifically, we design a sampling method that facilitates editing consecutive images while maintaining semantic consistency utilizing shared self-attention features during both reference and consecutive image sampling processes. Experimental results confirm that our method enables editing across diverse modalities including 3D scenes, videos, and panorama images.
5/28/2024

StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation
Yupeng Zhou, Daquan Zhou, Ming-Ming Cheng, Jiashi Feng, Qibin Hou
0
0
For recent diffusion-based generative models, maintaining consistent content across a series of generated images, especially those containing subjects and complex details, presents a significant challenge. In this paper, we propose a new way of self-attention calculation, termed Consistent Self-Attention, that significantly boosts the consistency between the generated images and augments prevalent pretrained diffusion-based text-to-image models in a zero-shot manner. To extend our method to long-range video generation, we further introduce a novel semantic space temporal motion prediction module, named Semantic Motion Predictor. It is trained to estimate the motion conditions between two provided images in the semantic spaces. This module converts the generated sequence of images into videos with smooth transitions and consistent subjects that are significantly more stable than the modules based on latent spaces only, especially in the context of long video generation. By merging these two novel components, our framework, referred to as StoryDiffusion, can describe a text-based story with consistent images or videos encompassing a rich variety of contents. The proposed StoryDiffusion encompasses pioneering explorations in visual story generation with the presentation of images and videos, which we hope could inspire more research from the aspect of architectural modifications. Our code is made publicly available at https://github.com/HVision-NKU/StoryDiffusion.
5/3/2024
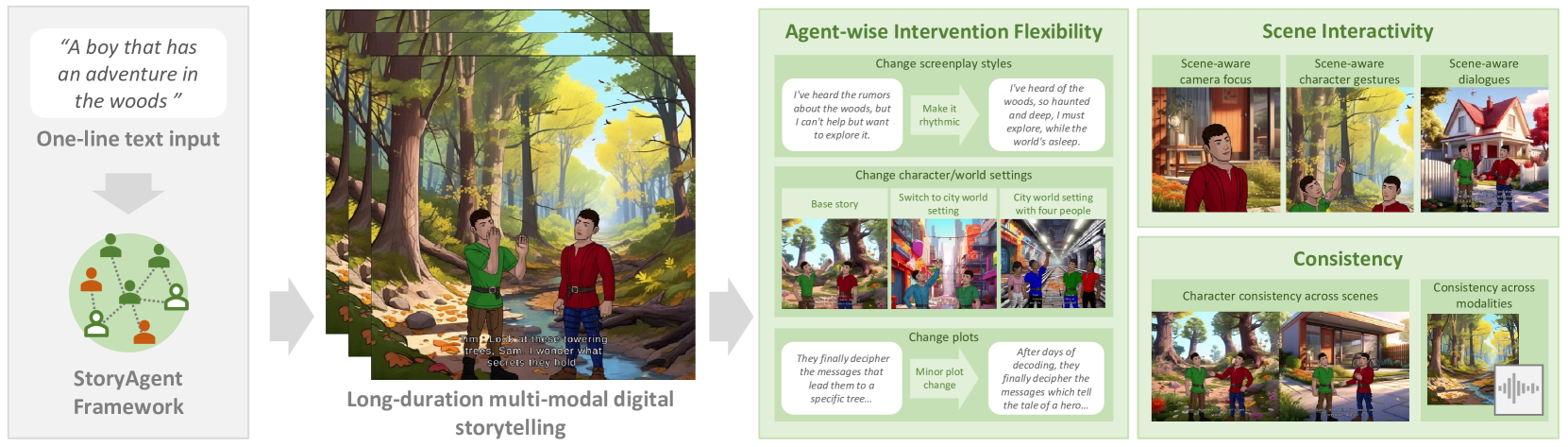
From Words to Worlds: Transforming One-line Prompt into Immersive Multi-modal Digital Stories with Communicative LLM Agent
Samuel S. Sohn, Danrui Li, Sen Zhang, Che-Jui Chang, Mubbasir Kapadia
0
0
Digital storytelling, essential in entertainment, education, and marketing, faces challenges in production scalability and flexibility. The StoryAgent framework, introduced in this paper, utilizes Large Language Models and generative tools to automate and refine digital storytelling. Employing a top-down story drafting and bottom-up asset generation approach, StoryAgent tackles key issues such as manual intervention, interactive scene orchestration, and narrative consistency. This framework enables efficient production of interactive and consistent narratives across multiple modalities, democratizing content creation and enhancing engagement. Our results demonstrate the framework's capability to produce coherent digital stories without reference videos, marking a significant advancement in automated digital storytelling.
6/24/2024