Supportiveness-based Knowledge Rewriting for Retrieval-augmented Language Modeling

0

Sign in to get full access
Overview
- This research paper proposes a novel approach called "Supportiveness-based Knowledge Rewriting" to enhance retrieval-augmented language modeling.
- The key idea is to leverage supportive knowledge from external sources to rewrite and enrich the language model's output, aiming to improve its performance on various tasks.
- The method involves retrieving relevant knowledge from a knowledge base, assessing the supportiveness of the retrieved information, and then rewriting the language model's output accordingly.
Plain English Explanation
Enhancing Question Answering with Enterprise Knowledge Bases Using is a technique that can help language models, like the ones used in chatbots or virtual assistants, become more knowledgeable and accurate.
The main idea is to go beyond just using the language model's own training data. Instead, the model can also access and use information from external knowledge sources, like databases or encyclopedias. This extra knowledge can then be used to improve the model's responses, making them more informative and relevant.
The specific approach described in this paper is called "Supportiveness-based Knowledge Rewriting." The key steps are:
- Retrieve relevant information from the external knowledge sources.
- Assess how well this information supports or complements the language model's original output.
- Use the supportive information to rewrite or enhance the language model's response, making it more comprehensive and useful.
By incorporating this external knowledge in a thoughtful way, the language model can provide better answers, explanations, or information to the user. This can be particularly helpful for tasks like question answering, where having access to broad knowledge can make a big difference.
Technical Explanation
The paper introduces a novel method called "Supportiveness-based Knowledge Rewriting" to enhance retrieval-augmented language modeling. The core idea is to leverage supportive knowledge from external sources to rewrite and enrich the language model's output, with the goal of improving its performance on various tasks.
The approach works as follows:
-
Retrieval-Augmented Language Modeling: The language model is first used to generate an initial output, which is then augmented with relevant knowledge retrieved from an external source, such as a knowledge base or Wikipedia.
-
Supportiveness Assessment: The retrieved knowledge is evaluated for its supportiveness, i.e., how well it complements or enhances the language model's original output. This is done using a separate supportiveness assessment model.
-
Knowledge Rewriting: Based on the supportiveness scores, the language model's output is rewritten to incorporate the most supportive retrieved knowledge. This helps to enrich the final response with additional relevant information.
The authors evaluate their approach on various language understanding and generation tasks, demonstrating its effectiveness in improving the language model's performance compared to baseline methods. The results suggest that the Supportiveness-based Knowledge Rewriting approach can be a valuable tool for enhancing the capabilities of large language models.
Critical Analysis
The research presented in this paper offers a promising direction for improving the performance of retrieval-augmented language models. The key strength of the Supportiveness-based Knowledge Rewriting approach is its ability to selectively incorporate external knowledge in a way that enhances the language model's output, rather than simply appending the retrieved information.
However, the paper does not address certain limitations and potential issues that could be explored further:
-
The supportiveness assessment model is a critical component, and its performance could significantly impact the overall effectiveness of the approach. More analysis on the robustness and generalization of this model would be valuable.
-
Enhanced Prompt-based LLM Reasoning Scheme via could also be a useful direction to explore, as it may provide additional insights into how to effectively integrate external knowledge with language model reasoning.
-
The evaluation is limited to a few specific tasks, and it would be interesting to see how the approach performs on a wider range of applications, including more open-ended and real-world scenarios.
Overall, the Supportiveness-based Knowledge Rewriting method represents a promising step towards enhancing the capabilities of retrieval-augmented language models. Further research and refinement of the approach could lead to even more significant improvements in language understanding and generation tasks.
Conclusion
This research paper presents a novel technique called "Supportiveness-based Knowledge Rewriting" that aims to improve the performance of retrieval-augmented language models. The key idea is to leverage supportive knowledge from external sources to enrich the language model's output, making it more informative and relevant.
The approach involves retrieving relevant knowledge, assessing its supportiveness, and then rewriting the language model's output accordingly. The authors demonstrate the effectiveness of this method on various language understanding and generation tasks, suggesting that it can be a valuable tool for enhancing the capabilities of large language models.
While the paper offers a promising direction for research, it also highlights the need for further exploration of the limitations and potential issues, such as the robustness of the supportiveness assessment model and the generalization of the approach to a wider range of applications. Continued advancements in this area could lead to significant improvements in the way language models can leverage external knowledge to provide more comprehensive and useful responses.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Supportiveness-based Knowledge Rewriting for Retrieval-augmented Language Modeling
Zile Qiao, Wei Ye, Yong Jiang, Tong Mo, Pengjun Xie, Weiping Li, Fei Huang, Shikun Zhang
Retrieval-augmented language models (RALMs) have recently shown great potential in mitigating the limitations of implicit knowledge in LLMs, such as untimely updating of the latest expertise and unreliable retention of long-tail knowledge. However, since the external knowledge base, as well as the retriever, can not guarantee reliability, potentially leading to the knowledge retrieved not being helpful or even misleading for LLM generation. In this paper, we introduce Supportiveness-based Knowledge Rewriting (SKR), a robust and pluggable knowledge rewriter inherently optimized for LLM generation. Specifically, we introduce the novel concept of supportiveness--which represents how effectively a knowledge piece facilitates downstream tasks--by considering the perplexity impact of augmented knowledge on the response text of a white-box LLM. Based on knowledge supportiveness, we first design a training data curation strategy for our rewriter model, effectively identifying and filtering out poor or irrelevant rewrites (e.g., with low supportiveness scores) to improve data efficacy. We then introduce the direct preference optimization (DPO) algorithm to align the generated rewrites to optimal supportiveness, guiding the rewriter model to summarize augmented content that better improves the final response. Comprehensive evaluations across six popular knowledge-intensive tasks and four LLMs have demonstrated the effectiveness and superiority of SKR. With only 7B parameters, SKR has shown better knowledge rewriting capability over GPT-4, the current state-of-the-art general-purpose LLM.
Read more6/13/2024
0
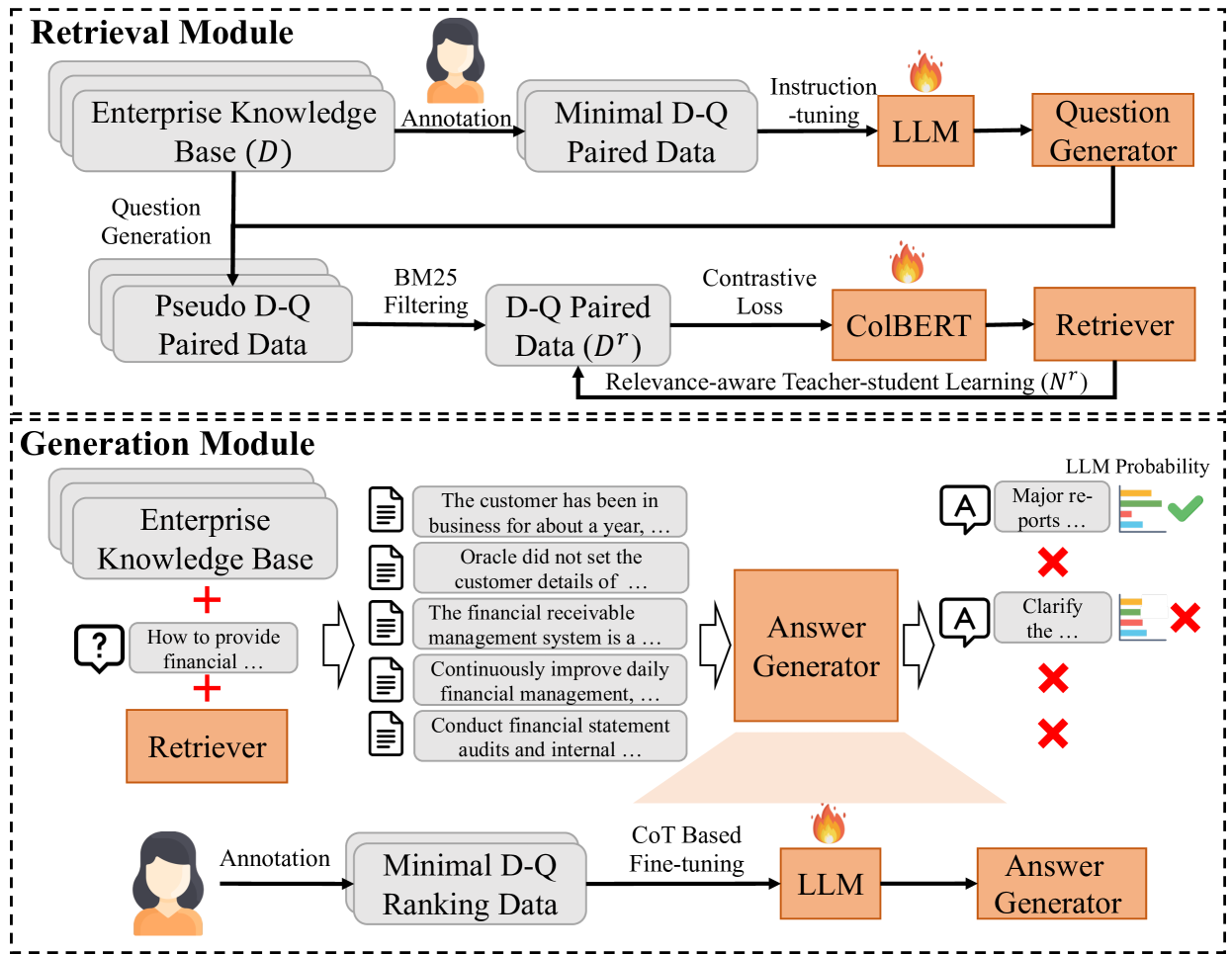
Enhancing Question Answering for Enterprise Knowledge Bases using Large Language Models
Feihu Jiang, Chuan Qin, Kaichun Yao, Chuyu Fang, Fuzhen Zhuang, Hengshu Zhu, Hui Xiong
Efficient knowledge management plays a pivotal role in augmenting both the operational efficiency and the innovative capacity of businesses and organizations. By indexing knowledge through vectorization, a variety of knowledge retrieval methods have emerged, significantly enhancing the efficacy of knowledge management systems. Recently, the rapid advancements in generative natural language processing technologies paved the way for generating precise and coherent answers after retrieving relevant documents tailored to user queries. However, for enterprise knowledge bases, assembling extensive training data from scratch for knowledge retrieval and generation is a formidable challenge due to the privacy and security policies of private data, frequently entailing substantial costs. To address the challenge above, in this paper, we propose EKRG, a novel Retrieval-Generation framework based on large language models (LLMs), expertly designed to enable question-answering for Enterprise Knowledge bases with limited annotation costs. Specifically, for the retrieval process, we first introduce an instruction-tuning method using an LLM to generate sufficient document-question pairs for training a knowledge retriever. This method, through carefully designed instructions, efficiently generates diverse questions for enterprise knowledge bases, encompassing both fact-oriented and solution-oriented knowledge. Additionally, we develop a relevance-aware teacher-student learning strategy to further enhance the efficiency of the training process. For the generation process, we propose a novel chain of thought (CoT) based fine-tuning method to empower the LLM-based generator to adeptly respond to user questions using retrieved documents. Finally, extensive experiments on real-world datasets have demonstrated the effectiveness of our proposed framework.
Read more4/23/2024

155
Improving Retrieval Augmented Language Model with Self-Reasoning
Yuan Xia, Jingbo Zhou, Zhenhui Shi, Jun Chen, Haifeng Huang
The Retrieval-Augmented Language Model (RALM) has shown remarkable performance on knowledge-intensive tasks by incorporating external knowledge during inference, which mitigates the factual hallucinations inherited in large language models (LLMs). Despite these advancements, challenges persist in the implementation of RALMs, particularly concerning their reliability and traceability. To be specific, the irrelevant document retrieval may result in unhelpful response generation or even deteriorate the performance of LLMs, while the lack of proper citations in generated outputs complicates efforts to verify the trustworthiness of the models. To this end, we propose a novel self-reasoning framework aimed at improving the reliability and traceability of RALMs, whose core idea is to leverage reasoning trajectories generated by the LLM itself. The framework involves constructing self-reason trajectories with three processes: a relevance-aware process, an evidence-aware selective process, and a trajectory analysis process. We have evaluated our framework across four public datasets (two short-form QA datasets, one long-form QA dataset, and one fact verification dataset) to demonstrate the superiority of our method, which can outperform existing state-of-art models and can achieve comparable performance with GPT-4, while only using 2,000 training samples.
Read more8/6/2024
0
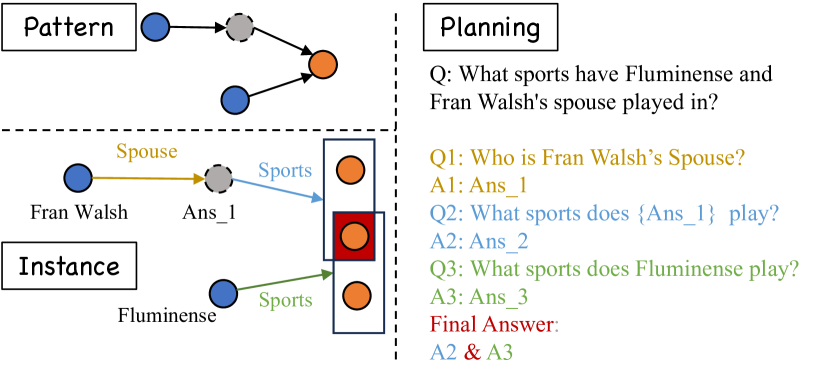
Learning to Plan for Retrieval-Augmented Large Language Models from Knowledge Graphs
Junjie Wang, Mingyang Chen, Binbin Hu, Dan Yang, Ziqi Liu, Yue Shen, Peng Wei, Zhiqiang Zhang, Jinjie Gu, Jun Zhou, Jeff Z. Pan, Wen Zhang, Huajun Chen
Improving the performance of large language models (LLMs) in complex question-answering (QA) scenarios has always been a research focal point. Recent studies have attempted to enhance LLMs' performance by combining step-wise planning with external retrieval. While effective for advanced models like GPT-3.5, smaller LLMs face challenges in decomposing complex questions, necessitating supervised fine-tuning. Previous work has relied on manual annotation and knowledge distillation from teacher LLMs, which are time-consuming and not accurate enough. In this paper, we introduce a novel framework for enhancing LLMs' planning capabilities by using planning data derived from knowledge graphs (KGs). LLMs fine-tuned with this data have improved planning capabilities, better equipping them to handle complex QA tasks that involve retrieval. Evaluations on multiple datasets, including our newly proposed benchmark, highlight the effectiveness of our framework and the benefits of KG-derived planning data.
Read more6/21/2024