A Survey of Robotic Language Grounding: Tradeoffs Between Symbols and Embeddings
2405.13245
0
0
💬
Abstract
With large language models, robots can understand language more flexibly and more capable than ever before. This survey reviews and situates recent literature into a spectrum with two poles: 1) mapping between language and some manually defined formal representation of meaning, and 2) mapping between language and high-dimensional vector spaces that translate directly to low-level robot policy. Using a formal representation allows the meaning of the language to be precisely represented, limits the size of the learning problem, and leads to a framework for interpretability and formal safety guarantees. Methods that embed language and perceptual data into high-dimensional spaces avoid this manually specified symbolic structure and thus have the potential to be more general when fed enough data but require more data and computing to train. We discuss the benefits and tradeoffs of each approach and finish by providing directions for future work that achieves the best of both worlds.
Create account to get full access
Overview
• This paper surveys recent research on using large language models to enable robots to understand language more flexibly and capably than ever before.
• It situates the research into a spectrum with two main approaches:
- Mapping language to a manually defined formal representation of meaning
- Mapping language directly to high-dimensional vector spaces that translate to low-level robot policies
• The formal representation approach allows precise meaning representation, limits the learning problem, and enables interpretability and safety guarantees.
• The high-dimensional vector space approach avoids manual symbolic structure and has potential for greater generalization, but requires more data and compute to train.
• The paper discusses the tradeoffs of each approach and suggests future directions that could combine the best of both.
Plain English Explanation
Large language models are revolutionizing how robots understand and interact with human language. This survey paper examines two main ways researchers are using these models to give robots more flexible and capable language skills.
The first approach maps language to a formal, manually-defined representation of meaning. This allows the robot to precisely understand the intent behind the language, which limits the learning problem and supports interpretability and safety. However, this formal structure can make the system less flexible.
The second approach skips the formal representation and instead maps language directly to high-dimensional vector spaces. These vector spaces then translate directly to the robot's low-level control policies. This avoids the manual symbolic structure, potentially making the system more general and adaptable. But it requires significantly more data and computing power to train.
The paper discusses the tradeoffs of these two approaches and suggests future research could find ways to combine their respective strengths. This could lead to language-enabled robots that are both highly capable and trustworthy.
Technical Explanation
The paper reviews recent research on using large language models to enable more flexible and capable language understanding in robotics. It situates the research into a spectrum with two main approaches:
-
Mapping language to a manually defined formal representation of meaning. This formal representation allows the meaning of the language to be precisely captured, which limits the size of the learning problem and provides a framework for interpretability and formal safety guarantees. However, this manually specified symbolic structure can make the system less adaptable.
-
Mapping language directly to high-dimensional vector spaces that then translate to low-level robot policies. This approach avoids the manually-specified symbolic structure, potentially enabling greater generalization when given enough training data. But it requires significantly more data and computing power to train effectively.
The paper discusses the benefits and tradeoffs of each approach. The formal representation allows for precise meaning capture and safety assurances, but may limit flexibility. The high-dimensional vector space mapping can be more general, but is more opaque and data-hungry.
The paper concludes by suggesting future research directions that could combine the strengths of both approaches, potentially leading to language-enabled robots that are both highly capable and trustworthy.
Critical Analysis
The paper provides a valuable high-level perspective on two major paradigms in using large language models for robot language understanding. However, it acknowledges several key limitations and areas for further research.
For example, the paper notes that the high-dimensional vector space approach "requires more data and computing to train" compared to the formal representation methods. This raises questions about the scalability and accessibility of such approaches, especially for resource-constrained real-world robot applications.
Additionally, while the paper highlights the potential for the formal representation approach to provide "interpretability and formal safety guarantees," it does not delve into the specific technical challenges of implementing such guarantees in practice. Further research may be needed to fully realize these benefits.
The paper also doesn't address potential biases or errors that could be introduced by large language models, and how these issues could be mitigated in safety-critical robot applications. This is an important consideration that future work should explore in depth.
Overall, the paper provides a thoughtful framework for understanding the tradeoffs in this active area of research. But continued technical advances and rigorous testing will be needed to develop truly robust, reliable, and trustworthy language-enabled robots.
Conclusion
This survey paper examines two main approaches to using large language models to enable more flexible and capable language understanding in robotics. The first approach maps language to a manually defined formal representation of meaning, while the second maps language directly to high-dimensional vector spaces that translate to robot control policies.
Each approach has its own set of benefits and drawbacks. The formal representation allows for precise meaning capture and safety guarantees, but may limit flexibility. The high-dimensional vector space mapping can be more general, but requires significantly more data and compute to train effectively.
The paper suggests that future research could find ways to combine the strengths of both approaches, potentially leading to language-enabled robots that are highly capable while also being trustworthy and interpretable. Addressing challenges around scalability, safety, and bias will be critical to realizing this vision and deploying such systems in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
Language, Environment, and Robotic Navigation
Johnathan E. Avery
0
0
This paper explores the integration of linguistic inputs within robotic navigation systems, drawing upon the symbol interdependency hypothesis to bridge the divide between symbolic and embodied cognition. It examines previous work incorporating language and semantics into Neural Network (NN) and Simultaneous Localization and Mapping (SLAM) approaches, highlighting how these integrations have advanced the field. By contrasting abstract symbol manipulation with sensory-motor grounding, we propose a unified framework where language functions both as an abstract communicative system and as a grounded representation of perceptual experiences. Our review of cognitive models of distributional semantics and their application to autonomous agents underscores the transformative potential of language-integrated systems.
4/5/2024

New!When Robots Get Chatty: Grounding Multimodal Human-Robot Conversation and Collaboration
Philipp Allgeuer, Hassan Ali, Stefan Wermter
0
0
We investigate the use of Large Language Models (LLMs) to equip neural robotic agents with human-like social and cognitive competencies, for the purpose of open-ended human-robot conversation and collaboration. We introduce a modular and extensible methodology for grounding an LLM with the sensory perceptions and capabilities of a physical robot, and integrate multiple deep learning models throughout the architecture in a form of system integration. The integrated models encompass various functions such as speech recognition, speech generation, open-vocabulary object detection, human pose estimation, and gesture detection, with the LLM serving as the central text-based coordinating unit. The qualitative and quantitative results demonstrate the huge potential of LLMs in providing emergent cognition and interactive language-oriented control of robots in a natural and social manner.
7/2/2024
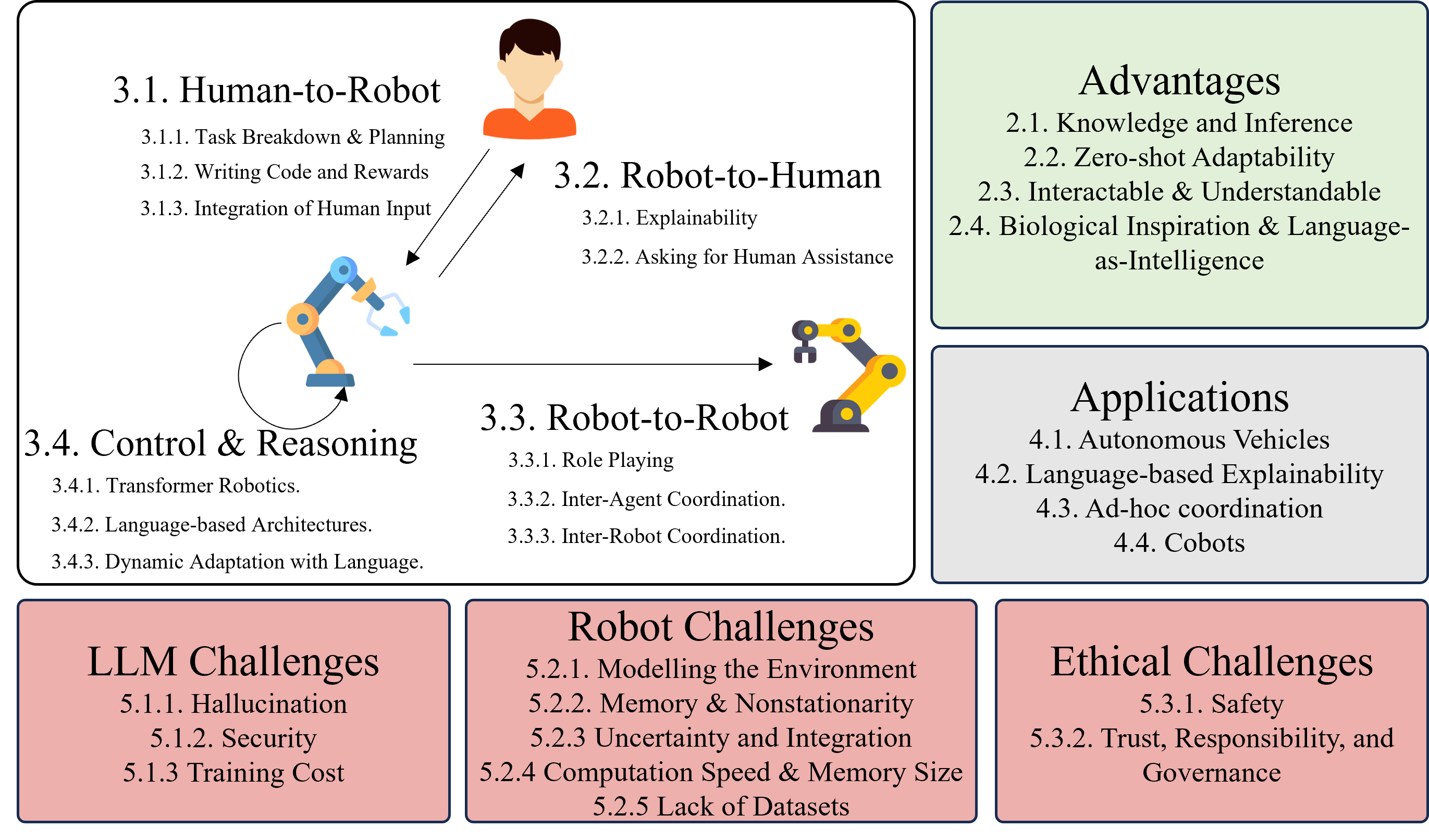
A Survey of Language-Based Communication in Robotics
William Hunt, Sarvapali D. Ramchurn, Mohammad D. Soorati
0
0
Embodied robots which can interact with their environment and neighbours are increasingly being used as a test case to develop Artificial Intelligence. This creates a need for multimodal robot controllers which can operate across different types of information including text. Large Language Models are able to process and generate textual as well as audiovisual data and, more recently, robot actions. Language Models are increasingly being applied to robotic systems; these Language-Based robots leverage the power of language models in a variety of ways. Additionally, the use of language opens up multiple forms of information exchange between members of a human-robot team. This survey motivates the use of language models in robotics, and then delineates works based on the part of the overall control flow in which language is incorporated. Language can be used by human to task a robot, by a robot to inform a human, between robots as a human-like communication medium, and internally for a robot's planning and control. Applications of language-based robots are explored, and finally numerous limitations and challenges are discussed to provide a summary of the development needed for language-based robotics moving forward. Links to each paper and, if available, source code are made available in the accompanying site at https://uos-haris.online/sooratilab/papers/WillSurvey/LangRobotSurvey.php
6/7/2024
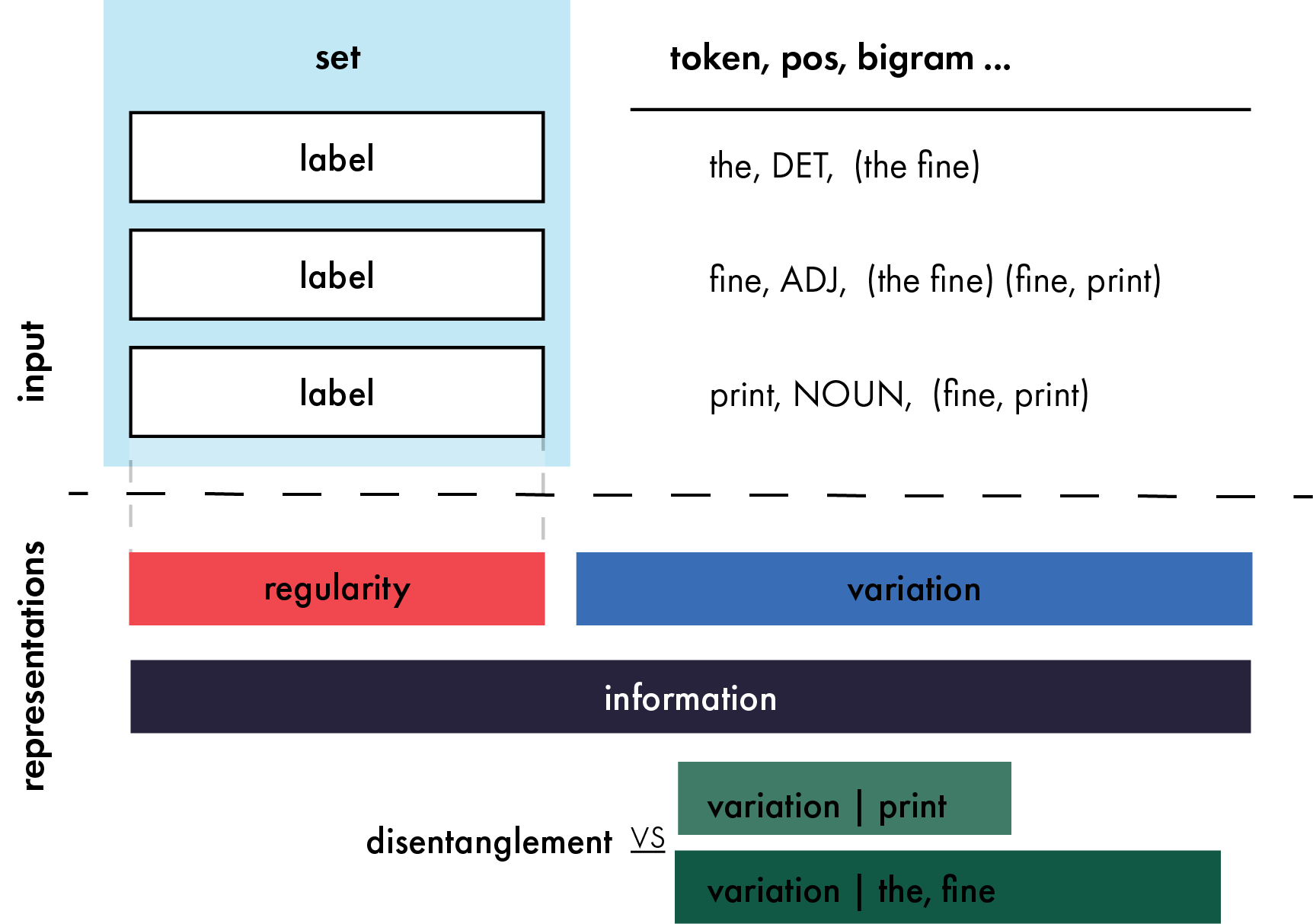
Representations as Language: An Information-Theoretic Framework for Interpretability
Henry Conklin, Kenny Smith
0
0
Large scale neural models show impressive performance across a wide array of linguistic tasks. Despite this they remain, largely, black-boxes - inducing vector-representations of their input that prove difficult to interpret. This limits our ability to understand what they learn, and when the learn it, or describe what kinds of representations generalise well out of distribution. To address this we introduce a novel approach to interpretability that looks at the mapping a model learns from sentences to representations as a kind of language in its own right. In doing so we introduce a set of information-theoretic measures that quantify how structured a model's representations are with respect to its input, and when during training that structure arises. Our measures are fast to compute, grounded in linguistic theory, and can predict which models will generalise best based on their representations. We use these measures to describe two distinct phases of training a transformer: an initial phase of in-distribution learning which reduces task loss, then a second stage where representations becoming robust to noise. Generalisation performance begins to increase during this second phase, drawing a link between generalisation and robustness to noise. Finally we look at how model size affects the structure of the representational space, showing that larger models ultimately compress their representations more than their smaller counterparts.
6/5/2024