Suvach -- Generated Hindi QA benchmark
2404.19254
0
0
🌀
Abstract
Current evaluation benchmarks for question answering (QA) in Indic languages often rely on machine translation of existing English datasets. This approach suffers from bias and inaccuracies inherent in machine translation, leading to datasets that may not reflect the true capabilities of EQA models for Indic languages. This paper proposes a new benchmark specifically designed for evaluating Hindi EQA models and discusses the methodology to do the same for any task. This method leverages large language models (LLMs) to generate a high-quality dataset in an extractive setting, ensuring its relevance for the target language. We believe this new resource will foster advancements in Hindi NLP research by providing a more accurate and reliable evaluation tool.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper highlights issues with current question answering (QA) benchmarks for Indic languages, which often rely on machine translation of English datasets.
- This approach suffers from biases and inaccuracies inherent in machine translation, leading to datasets that may not reflect the true capabilities of Indic language QA models.
- The paper proposes a new benchmark specifically designed for evaluating Hindi QA models, leveraging large language models (LLMs) to generate a high-quality dataset in an extractive setting.
- The authors believe this new resource will foster advancements in Hindi NLP research by providing a more accurate and reliable evaluation tool.
Plain English Explanation
The paper discusses a problem with how researchers currently test and measure the performance of question-answering models for Indic languages like Hindi. Typically, they take existing English datasets and translate them into Indic languages using machine translation. However, this approach has some issues.
Machine translation can introduce biases and inaccuracies, which means the resulting datasets may not accurately reflect the true capabilities of Indic language question-answering models. In other words, the test may not be a fair or reliable way to evaluate these models.
To address this, the researchers propose a new benchmark specifically designed for evaluating Hindi question-answering models. They use large language models (LLMs) to generate a high-quality dataset in Hindi, focusing on an extractive setting where the model has to find the relevant information in a given passage.
The authors believe this new resource will help advance Hindi natural language processing (NLP) research by providing a more accurate and trustworthy way to evaluate the performance of question-answering models in this language. This could lead to better models and applications that work well for Hindi speakers.
Technical Explanation
The paper identifies limitations in the current approach to evaluating question-answering (QA) models for Indic languages. Existing benchmarks often rely on machine translation of English datasets, such as SamaYik and IndiBias, which can introduce biases and inaccuracies.
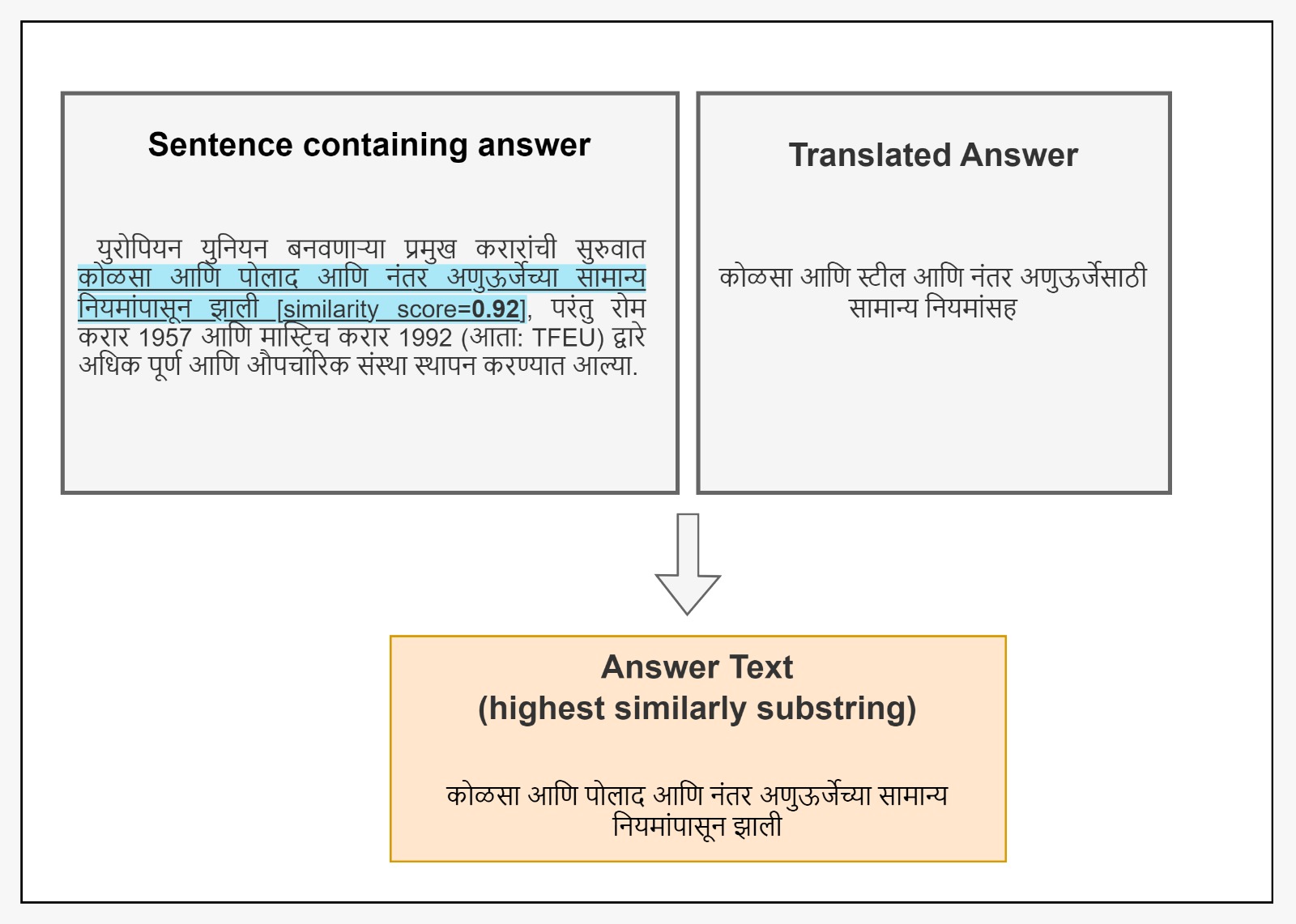
To address this, the researchers propose a new benchmark specifically designed for evaluating Hindi QA models. They leverage large language models (LLMs) to generate a high-quality dataset in an extractive QA setting, where the model must identify the relevant information within a given passage to answer the question.
The authors describe the methodology for creating this new benchmark, which involves using an LLM to generate questions and answers based on passages of Hindi text. They then filter and curate the dataset to ensure high quality and relevance for evaluating Hindi QA models.
This approach aims to provide a more accurate and reliable evaluation tool, as the dataset is natively generated in Hindi rather than translated from another language. The authors believe this new resource will foster advancements in Hindi NLP research by enabling better assessment of model capabilities in this language.
Critical Analysis
The paper makes a compelling case for the need to develop more targeted evaluation benchmarks for Indic languages like Hindi, as the current reliance on machine-translated English datasets can lead to biased and inaccurate assessments.
The proposed methodology of leveraging LLMs to generate a high-quality Hindi QA dataset seems promising, as it can help capture the nuances and complexities of the language more effectively than translation-based approaches. However, the authors acknowledge that further research is needed to optimize the dataset generation and curation processes to ensure the dataset's reliability and representativeness.
Additionally, while the focus on an extractive QA setting is a reasonable starting point, it would be interesting to see the authors expand the benchmark to include other QA paradigms, such as abstractive or multi-hop reasoning, to provide a more comprehensive evaluation of Hindi QA models.
Overall, the paper makes a valuable contribution to the field of Indic language NLP by highlighting the limitations of current benchmarks and proposing a novel approach to address them. The successful development and adoption of this new Hindi QA benchmark could significantly advance research in this area and lead to more accurate and impactful NLP applications for Hindi speakers.
Conclusion
This paper identifies a critical issue with current evaluation benchmarks for question-answering (QA) models in Indic languages like Hindi. The reliance on machine-translated English datasets can introduce biases and inaccuracies, resulting in tests that may not accurately reflect the true capabilities of Indic language QA models.
To address this, the researchers propose a new benchmark specifically designed for evaluating Hindi QA models. By leveraging large language models to generate a high-quality dataset in an extractive QA setting, the authors aim to provide a more reliable and representative evaluation tool for this language.
The successful implementation of this new benchmark has the potential to foster significant advancements in Hindi natural language processing research, leading to more accurate and impactful NLP applications for Hindi speakers. This work highlights the importance of developing tailored evaluation resources for underrepresented languages to ensure fair and meaningful assessments of model performance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
MahaSQuAD: Bridging Linguistic Divides in Marathi Question-Answering
Ruturaj Ghatage, Aditya Kulkarni, Rajlaxmi Patil, Sharvi Endait, Raviraj Joshi
0
0
Question-answering systems have revolutionized information retrieval, but linguistic and cultural boundaries limit their widespread accessibility. This research endeavors to bridge the gap of the absence of efficient QnA datasets in low-resource languages by translating the English Question Answering Dataset (SQuAD) using a robust data curation approach. We introduce MahaSQuAD, the first-ever full SQuAD dataset for the Indic language Marathi, consisting of 118,516 training, 11,873 validation, and 11,803 test samples. We also present a gold test set of manually verified 500 examples. Challenges in maintaining context and handling linguistic nuances are addressed, ensuring accurate translations. Moreover, as a QnA dataset cannot be simply converted into any low-resource language using translation, we need a robust method to map the answer translation to its span in the translated passage. Hence, to address this challenge, we also present a generic approach for translating SQuAD into any low-resource language. Thus, we offer a scalable approach to bridge linguistic and cultural gaps present in low-resource languages, in the realm of question-answering systems. The datasets and models are shared publicly at https://github.com/l3cube-pune/MarathiNLP .
4/23/2024
↗️
UQA: Corpus for Urdu Question Answering
Samee Arif, Sualeha Farid, Awais Athar, Agha Ali Raza
0
0
This paper introduces UQA, a novel dataset for question answering and text comprehension in Urdu, a low-resource language with over 70 million native speakers. UQA is generated by translating the Stanford Question Answering Dataset (SQuAD2.0), a large-scale English QA dataset, using a technique called EATS (Enclose to Anchor, Translate, Seek), which preserves the answer spans in the translated context paragraphs. The paper describes the process of selecting and evaluating the best translation model among two candidates: Google Translator and Seamless M4T. The paper also benchmarks several state-of-the-art multilingual QA models on UQA, including mBERT, XLM-RoBERTa, and mT5, and reports promising results. For XLM-RoBERTa-XL, we have an F1 score of 85.99 and 74.56 EM. UQA is a valuable resource for developing and testing multilingual NLP systems for Urdu and for enhancing the cross-lingual transferability of existing models. Further, the paper demonstrates the effectiveness of EATS for creating high-quality datasets for other languages and domains. The UQA dataset and the code are publicly available at www.github.com/sameearif/UQA.
5/3/2024
🔗
S={a}mayik: A Benchmark and Dataset for English-Sanskrit Translation
Ayush Maheshwari, Ashim Gupta, Amrith Krishna, Atul Kumar Singh, Ganesh Ramakrishnan, G. Anil Kumar, Jitin Singla
0
0
We release S={a}mayik, a dataset of around 53,000 parallel English-Sanskrit sentences, written in contemporary prose. Sanskrit is a classical language still in sustenance and has a rich documented heritage. However, due to the limited availability of digitized content, it still remains a low-resource language. Existing Sanskrit corpora, whether monolingual or bilingual, have predominantly focused on poetry and offer limited coverage of contemporary written materials. S={a}mayik is curated from a diverse range of domains, including language instruction material, textual teaching pedagogy, and online tutorials, among others. It stands out as a unique resource that specifically caters to the contemporary usage of Sanskrit, with a primary emphasis on prose writing. Translation models trained on our dataset demonstrate statistically significant improvements when translating out-of-domain contemporary corpora, outperforming models trained on older classical-era poetry datasets. Finally, we also release benchmark models by adapting four multilingual pre-trained models, three of them have not been previously exposed to Sanskrit for translating between English and Sanskrit while one of them is multi-lingual pre-trained translation model including English and Sanskrit. The dataset and source code is present at https://github.com/ayushbits/saamayik.
4/1/2024

IndiBias: A Benchmark Dataset to Measure Social Biases in Language Models for Indian Context
Nihar Ranjan Sahoo, Pranamya Prashant Kulkarni, Narjis Asad, Arif Ahmad, Tanu Goyal, Aparna Garimella, Pushpak Bhattacharyya
0
0
The pervasive influence of social biases in language data has sparked the need for benchmark datasets that capture and evaluate these biases in Large Language Models (LLMs). Existing efforts predominantly focus on English language and the Western context, leaving a void for a reliable dataset that encapsulates India's unique socio-cultural nuances. To bridge this gap, we introduce IndiBias, a comprehensive benchmarking dataset designed specifically for evaluating social biases in the Indian context. We filter and translate the existing CrowS-Pairs dataset to create a benchmark dataset suited to the Indian context in Hindi language. Additionally, we leverage LLMs including ChatGPT and InstructGPT to augment our dataset with diverse societal biases and stereotypes prevalent in India. The included bias dimensions encompass gender, religion, caste, age, region, physical appearance, and occupation. We also build a resource to address intersectional biases along three intersectional dimensions. Our dataset contains 800 sentence pairs and 300 tuples for bias measurement across different demographics. The dataset is available in English and Hindi, providing a size comparable to existing benchmark datasets. Furthermore, using IndiBias we compare ten different language models on multiple bias measurement metrics. We observed that the language models exhibit more bias across a majority of the intersectional groups.
4/4/2024