Synergistic Global-space Camera and Human Reconstruction from Videos

0
🤿
Sign in to get full access
Overview
- This paper introduces a new method called Synergistic Camera and Human Reconstruction (SynCHMR) that combines camera and human reconstruction from monocular video.
- Most existing methods can only reconstruct either camera trajectories and scene structure or human meshes, but not both together in a consistent way.
- SynCHMR aims to address this by jointly reconstructing camera poses, scene point clouds, and human meshes in a common world frame.
Plain English Explanation
SynCHMR is a new approach that allows us to reconstruct both the camera's movement and the people in a video at the same time, in a consistent way. Typically, methods can either figure out the camera's path and the general scene, or they can reconstruct the shape of the people, but not both together seamlessly.
SynCHMR tries to marry the best of both worlds. It uses the information about the people in the video as a strong prior to help reconstruct the camera's motion and the overall 3D scene. And it then uses that reconstructed 3D scene to further enhance the reconstruction of the people's shapes.
By doing this jointly, SynCHMR can produce consistent reconstructions of the camera, the people, and the overall 3D environment, all in the same common coordinate frame. This could be very useful for applications like human mesh recovery from arbitrary views, 3D human scanning from moving event cameras, or dynamic 3D scene reconstruction.
Technical Explanation
The key innovation of SynCHMR is that it jointly optimizes for camera poses, scene point clouds, and human meshes, all in a common world coordinate frame. This is achieved through two main components:
-
Human-aware Metric SLAM: This module uses the human mesh reconstructions as a strong prior to help recover the true metric scale of the camera poses and scene structure, addressing common ambiguities in monocular SLAM. It leverages techniques like incremental joint learning of depth, pose, and implicit scene to achieve this.
-
Scene-aware SMPL Denoiser: Conditioning on the dense scene point clouds recovered by the SLAM module, this component learns to enhance the human mesh reconstructions by incorporating spatio-temporal coherency and dynamic scene constraints. This helps resolve issues like PhotoSLAM where the human meshes may not fully align with the reconstructed environment.
By tightly coupling these two components, SynCHMR is able to produce consistent reconstructions of camera, humans, and scene in a common world coordinate system. This overcomes the limitations of previous methods that treated these problems independently.
Critical Analysis
The authors acknowledge that SynCHMR relies on accurate initial human mesh reconstructions, which can be challenging in practice. Further research is needed to make the human mesh estimation more robust, especially in complex scenes with occlusions or unusual poses.
Additionally, the current implementation of SynCHMR is computationally expensive, requiring significant processing power. Optimizing the efficiency of the system would be an important area for future work to enable real-time or near-real-time applications.
While the paper demonstrates promising results, more thorough evaluation on diverse datasets and real-world scenarios would be beneficial to further validate the generalization and robustness of the approach. Comparisons to other state-of-the-art methods in both camera-centric and human-centric reconstruction would also help contextualize the contributions of SynCHMR.
Conclusion
The SynCHMR method presented in this paper represents an important step towards integrating camera and human reconstruction in a synergistic manner. By jointly optimizing for camera poses, scene structure, and human meshes, it can produce consistent 3D reconstructions that have the potential to enable a wide range of applications, from immersive virtual experiences to advanced human-computer interaction. While the current implementation has some limitations, the core ideas behind SynCHMR point to exciting future directions in the field of 3D computer vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Synergistic Global-space Camera and Human Reconstruction from Videos
Yizhou Zhao, Tuanfeng Y. Wang, Bhiksha Raj, Min Xu, Jimei Yang, Chun-Hao Paul Huang
Remarkable strides have been made in reconstructing static scenes or human bodies from monocular videos. Yet, the two problems have largely been approached independently, without much synergy. Most visual SLAM methods can only reconstruct camera trajectories and scene structures up to scale, while most HMR methods reconstruct human meshes in metric scale but fall short in reasoning with cameras and scenes. This work introduces Synergistic Camera and Human Reconstruction (SynCHMR) to marry the best of both worlds. Specifically, we design Human-aware Metric SLAM to reconstruct metric-scale camera poses and scene point clouds using camera-frame HMR as a strong prior, addressing depth, scale, and dynamic ambiguities. Conditioning on the dense scene recovered, we further learn a Scene-aware SMPL Denoiser to enhance world-frame HMR by incorporating spatio-temporal coherency and dynamic scene constraints. Together, they lead to consistent reconstructions of camera trajectories, human meshes, and dense scene point clouds in a common world frame. Project page: https://paulchhuang.github.io/synchmr
Read more5/24/2024

0
OfCaM: Global Human Mesh Recovery via Optimization-free Camera Motion Scale Calibration
Fengyuan Yang, Kerui Gu, Ha Linh Nguyen, Angela Yao
Accurate camera motion estimation is critical to estimate human motion in the global space. A standard and widely used method for estimating camera motion is Simultaneous Localization and Mapping (SLAM). However, SLAM only provides a trajectory up to an unknown scale factor. Different from previous attempts that optimize the scale factor, this paper presents Optimization-free Camera Motion Scale Calibration (OfCaM), a novel framework that utilizes prior knowledge from human mesh recovery (HMR) models to directly calibrate the unknown scale factor. Specifically, OfCaM leverages the absolute depth of human-background contact joints from HMR predictions as a calibration reference, enabling the precise recovery of SLAM camera trajectory scale in global space. With this correctly scaled camera motion and HMR's local motion predictions, we achieve more accurate global human motion estimation. To compensate for scenes where we detect SLAM failure, we adopt a local-to-global motion mapping to fuse with previously derived motion to enhance robustness. Simple yet powerful, our method sets a new standard for global human mesh estimation tasks, reducing global human motion error by 60% over the prior SOTA while also demanding orders of magnitude less inference time compared with optimization-based methods.
Read more7/2/2024
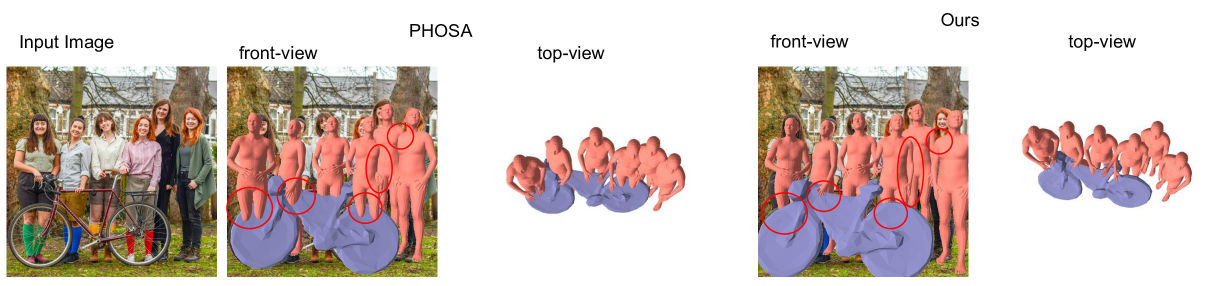
0
Single-image coherent reconstruction of objects and humans
Sarthak Batra, Partha P. Chakrabarti, Simon Hadfield, Armin Mustafa
Existing methods for reconstructing objects and humans from a monocular image suffer from severe mesh collisions and performance limitations for interacting occluding objects. This paper introduces a method to obtain a globally consistent 3D reconstruction of interacting objects and people from a single image. Our contributions include: 1) an optimization framework, featuring a collision loss, tailored to handle human-object and human-human interactions, ensuring spatially coherent scene reconstruction; and 2) a novel technique to robustly estimate 6 degrees of freedom (DOF) poses, specifically for heavily occluded objects, exploiting image inpainting. Notably, our proposed method operates effectively on images from real-world scenarios, without necessitating scene or object-level 3D supervision. Extensive qualitative and quantitative evaluation against existing methods demonstrates a significant reduction in collisions in the final reconstructions of scenes with multiple interacting humans and objects and a more coherent scene reconstruction.
Read more8/16/2024

0
Human Mesh Recovery from Arbitrary Multi-view Images
Xiaoben Li, Mancheng Meng, Ziyan Wu, Terrence Chen, Fan Yang, Dinggang Shen
Human mesh recovery from arbitrary multi-view images involves two characteristics: the arbitrary camera poses and arbitrary number of camera views. Because of the variability, designing a unified framework to tackle this task is challenging. The challenges can be summarized as the dilemma of being able to simultaneously estimate arbitrary camera poses and recover human mesh from arbitrary multi-view images while maintaining flexibility. To solve this dilemma, we propose a divide and conquer framework for Unified Human Mesh Recovery (U-HMR) from arbitrary multi-view images. In particular, U-HMR consists of a decoupled structure and two main components: camera and body decoupling (CBD), camera pose estimation (CPE), and arbitrary view fusion (AVF). As camera poses and human body mesh are independent of each other, CBD splits the estimation of them into two sub-tasks for two individual sub-networks (ie, CPE and AVF) to handle respectively, thus the two sub-tasks are disentangled. In CPE, since each camera pose is unrelated to the others, we adopt a shared MLP to process all views in a parallel way. In AVF, in order to fuse multi-view information and make the fusion operation independent of the number of views, we introduce a transformer decoder with a SMPL parameters query token to extract cross-view features for mesh recovery. To demonstrate the efficacy and flexibility of the proposed framework and effect of each component, we conduct extensive experiments on three public datasets: Human3.6M, MPI-INF-3DHP, and TotalCapture.
Read more6/18/2024