Synergizing Unsupervised and Supervised Learning: A Hybrid Approach for Accurate Natural Language Task Modeling

0
🤷
Sign in to get full access
Overview
• This paper presents a novel hybrid approach that combines unsupervised and supervised learning techniques to improve the performance of natural language processing (NLP) tasks.
• Supervised learning models have shown strong performance in NLP, but they require large labeled datasets, which can be costly and time-consuming to obtain.
• Unsupervised learning techniques can leverage abundant unlabeled text data to learn rich representations, but they do not directly optimize for specific NLP tasks.
• The proposed hybrid approach integrates an unsupervised module that learns representations from unlabeled corpora (e.g., language models, word embeddings) and a supervised module that leverages these representations to enhance task-specific models.
Plain English Explanation
• Machine learning models trained on labeled data (supervised learning) have achieved impressive results in various NLP tasks, such as text classification and named entity recognition (NER). However, obtaining large labeled datasets can be challenging and expensive.
• On the other hand, unsupervised learning techniques can learn useful representations from abundant unlabeled text data, but they don't directly optimize for specific NLP tasks.
• The researchers in this paper combined the strengths of supervised and unsupervised learning to create a hybrid approach that can achieve better performance on NLP tasks with less labeled data.
• For text classification, the hybrid approach uses contextual word embeddings from a pretrained language model to initialize a recurrent or transformer-based classifier.
• For NER, the hybrid approach uses word embeddings to initialize a BiLSTM sequence labeler.
• By integrating unsupervised and supervised learning, this hybrid approach can achieve state-of-the-art results on benchmark datasets, potentially leading to more data-efficient and robust NLP systems.
Technical Explanation
• The paper presents a hybrid approach that combines unsupervised and supervised learning for NLP tasks.
• The unsupervised module learns rich representations from unlabeled text data, such as language models or word embeddings. These representations are then used to initialize and enhance the supervised module, which is trained on task-specific labeled data.
• For text classification, the researchers use contextual word embeddings from a pretrained language model to initialize a recurrent or transformer-based classifier. This allows the classifier to benefit from the semantic and syntactic knowledge captured by the language model, even with limited labeled data.
• For NER, the researchers use word embeddings to initialize a BiLSTM sequence labeler. This helps the model better understand the language patterns and relationships between words, leading to improved performance on the NER task.
• The paper evaluates the hybrid approach on text classification and NER tasks, demonstrating consistent performance gains over supervised baselines.
• The researchers attribute the success of their hybrid approach to the synergy between the unsupervised and supervised modules, which allows for more data-efficient and robust NLP systems.
Critical Analysis
• The paper does not provide a detailed comparison of the hybrid approach with other semi-supervised or transfer learning techniques, such as augmenting NER datasets with LLMs or cross-lingual transfer learning. A more comprehensive analysis could help readers understand the unique strengths and limitations of the proposed approach.
• The paper focuses on only two NLP tasks (text classification and NER) and does not explore the broader applicability of the hybrid approach to other NLP tasks. Further research is needed to assess its generalizability.
• The paper does not provide detailed information about the specific unsupervised and supervised models used in the experiments, nor the hyperparameters and training procedures. This makes it difficult to reproduce the results or understand the technical nuances of the implementation.
• The paper does not discuss potential issues or challenges with the hybrid approach, such as the potential for negative transfer from the unsupervised module or the computational overhead of maintaining both modules.
Conclusion
• The paper presents a novel hybrid approach that combines unsupervised and supervised learning techniques to improve the performance of NLP tasks, such as text classification and named entity recognition.
• By leveraging the strengths of both unsupervised and supervised learning, the hybrid approach can achieve state-of-the-art results on benchmark datasets, potentially leading to more data-efficient and robust NLP systems.
• The research highlights the potential of integrating different machine learning paradigms to overcome the limitations of individual approaches and advance the field of natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
0
Synergizing Unsupervised and Supervised Learning: A Hybrid Approach for Accurate Natural Language Task Modeling
Wrick Talukdar, Anjanava Biswas
While supervised learning models have shown remarkable performance in various natural language processing (NLP) tasks, their success heavily relies on the availability of large-scale labeled datasets, which can be costly and time-consuming to obtain. Conversely, unsupervised learning techniques can leverage abundant unlabeled text data to learn rich representations, but they do not directly optimize for specific NLP tasks. This paper presents a novel hybrid approach that synergizes unsupervised and supervised learning to improve the accuracy of NLP task modeling. While supervised models excel at specific tasks, they rely on large labeled datasets. Unsupervised techniques can learn rich representations from abundant unlabeled text but don't directly optimize for tasks. Our methodology integrates an unsupervised module that learns representations from unlabeled corpora (e.g., language models, word embeddings) and a supervised module that leverages these representations to enhance task-specific models. We evaluate our approach on text classification and named entity recognition (NER), demonstrating consistent performance gains over supervised baselines. For text classification, contextual word embeddings from a language model pretrain a recurrent or transformer-based classifier. For NER, word embeddings initialize a BiLSTM sequence labeler. By synergizing techniques, our hybrid approach achieves SOTA results on benchmark datasets, paving the way for more data-efficient and robust NLP systems.
Read more6/4/2024
0
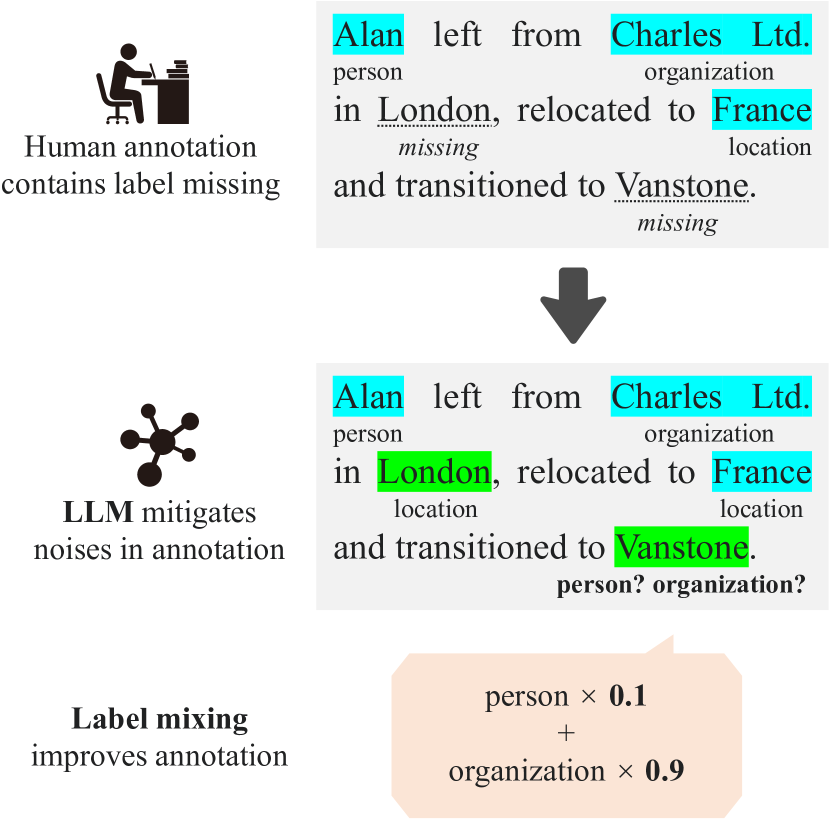
Augmenting NER Datasets with LLMs: Towards Automated and Refined Annotation
Yuji Naraki, Ryosuke Yamaki, Yoshikazu Ikeda, Takafumi Horie, Hiroki Naganuma
In the field of Natural Language Processing (NLP), Named Entity Recognition (NER) is recognized as a critical technology, employed across a wide array of applications. Traditional methodologies for annotating datasets for NER models are challenged by high costs and variations in dataset quality. This research introduces a novel hybrid annotation approach that synergizes human effort with the capabilities of Large Language Models (LLMs). This approach not only aims to ameliorate the noise inherent in manual annotations, such as omissions, thereby enhancing the performance of NER models, but also achieves this in a cost-effective manner. Additionally, by employing a label mixing strategy, it addresses the issue of class imbalance encountered in LLM-based annotations. Through an analysis across multiple datasets, this method has been consistently shown to provide superior performance compared to traditional annotation methods, even under constrained budget conditions. This study illuminates the potential of leveraging LLMs to improve dataset quality, introduces a novel technique to mitigate class imbalances, and demonstrates the feasibility of achieving high-performance NER in a cost-effective way.
Read more4/3/2024
💬
0
Leveraging Large Language Models for Knowledge-free Weak Supervision in Clinical Natural Language Processing
Enshuo Hsu, Kirk Roberts
The performance of deep learning-based natural language processing systems is based on large amounts of labeled training data which, in the clinical domain, are not easily available or affordable. Weak supervision and in-context learning offer partial solutions to this issue, particularly using large language models (LLMs), but their performance still trails traditional supervised methods with moderate amounts of gold-standard data. In particular, inferencing with LLMs is computationally heavy. We propose an approach leveraging fine-tuning LLMs and weak supervision with virtually no domain knowledge that still achieves consistently dominant performance. Using a prompt-based approach, the LLM is used to generate weakly-labeled data for training a downstream BERT model. The weakly supervised model is then further fine-tuned on small amounts of gold standard data. We evaluate this approach using Llama2 on three different n2c2 datasets. With no more than 10 gold standard notes, our final BERT models weakly supervised by fine-tuned Llama2-13B consistently outperformed out-of-the-box PubMedBERT by 4.7% to 47.9% in F1 scores. With only 50 gold standard notes, our models achieved close performance to fully fine-tuned systems.
Read more6/12/2024
0
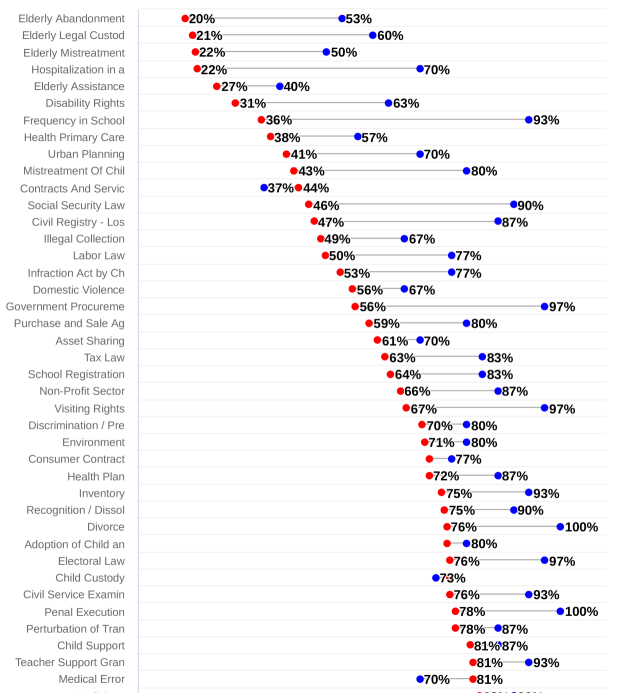
A Small Claims Court for the NLP: Judging Legal Text Classification Strategies With Small Datasets
Mariana Yukari Noguti, Edduardo Vellasques, Luiz Eduardo Soares Oliveira
Recent advances in language modelling has significantly decreased the need of labelled data in text classification tasks. Transformer-based models, pre-trained on unlabeled data, can outmatch the performance of models trained from scratch for each task. However, the amount of labelled data need to fine-tune such type of model is still considerably high for domains requiring expert-level annotators, like the legal domain. This paper investigates the best strategies for optimizing the use of a small labeled dataset and large amounts of unlabeled data and perform a classification task in the legal area with 50 predefined topics. More specifically, we use the records of demands to a Brazilian Public Prosecutor's Office aiming to assign the descriptions in one of the subjects, which currently demands deep legal knowledge for manual filling. The task of optimizing the performance of classifiers in this scenario is especially challenging, given the low amount of resources available regarding the Portuguese language, especially in the legal domain. Our results demonstrate that classic supervised models such as logistic regression and SVM and the ensembles random forest and gradient boosting achieve better performance along with embeddings extracted with word2vec when compared to BERT language model. The latter demonstrates superior performance in association with the architecture of the model itself as a classifier, having surpassed all previous models in that regard. The best result was obtained with Unsupervised Data Augmentation (UDA), which jointly uses BERT, data augmentation, and strategies of semi-supervised learning, with an accuracy of 80.7% in the aforementioned task.
Read more9/11/2024