Synthetic4Health: Generating Annotated Synthetic Clinical Letters

0

Sign in to get full access
Overview
- This paper describes a framework called "Synthetic4Health" for generating annotated synthetic clinical letters.
- The goal is to create realistic and diverse synthetic medical data to support AI training and healthcare research.
- The framework leverages large language models to generate synthetic clinical letters with relevant medical entities and annotations.
Plain English Explanation
The researchers developed a system called "Synthetic4Health" that can generate realistic, annotated synthetic clinical letters. These are fictional medical documents that mimic the content and structure of real clinical letters, but without using any private patient data.
The key idea is to use large language models - powerful AI systems trained on vast amounts of text data - to automatically produce these synthetic letters. The models can generate convincing medical text and also identify relevant medical entities like diagnoses, medications, and procedures.
This provides a way to create large datasets of synthetic clinical data that can be used to train and evaluate AI models in healthcare without compromising patient privacy. The annotated synthetic data can also support other types of medical research and analysis.
Technical Explanation
The Synthetic4Health framework has three main components:
-
Text Generation: A large language model is fine-tuned on a corpus of real clinical letters to learn the style and content of medical text. This model can then generate new, realistic-looking synthetic letters.
-
Entity Extraction: Another model is trained to identify and annotate key medical entities like diagnoses, medications, and procedures within the generated text. This provides a rich set of labels for the synthetic data.
-
Coherence Filtering: The synthetic letters are passed through a set of heuristics and classifiers to ensure they maintain logical coherence and clinical plausibility.
The researchers evaluated Synthetic4Health by having medical experts assess the realism and quality of the generated letters. They found the synthetic data was rated as highly realistic and the entity annotations were accurate. Downstream experiments also showed the synthetic data could effectively substitute for real clinical data in certain AI training tasks.
Critical Analysis
The paper presents a compelling approach for generating high-quality synthetic clinical data. By leveraging large language models, the system can create diverse and realistic-looking medical text at scale. The entity extraction and coherence filtering components also help ensure the synthetic data maintains clinical validity.
However, the authors acknowledge some limitations. The synthetic letters may not fully capture the complexity and variability of real-world clinical documentation. There are also open questions around how to best evaluate the realism and utility of synthetic data, beyond just expert assessment.
Additionally, while the system aims to protect patient privacy, there are still open questions around the potential risks of these techniques, especially as the models become more advanced. Careful governance and oversight will be critical as synthetic data generation becomes more widespread in healthcare.
Overall, the Synthetic4Health framework represents an important advance in the field of synthetic data generation for medical applications. As the authors note, this work has the potential to significantly accelerate AI-powered medical research and clinical decision support systems. However, the technology should be developed and deployed responsibly, with a keen eye towards maximizing the benefits while minimizing any unintended consequences.
Conclusion
The Synthetic4Health framework provides a robust approach for generating annotated, synthetic clinical letters that can substitute for real patient data in various healthcare applications. By leveraging large language models and targeted entity extraction, the system can create diverse and realistic-looking medical text without compromising patient privacy.
While there are still some limitations and open questions, this work represents an important step forward in the field of synthetic data generation for healthcare. As these techniques continue to evolve, they have the potential to dramatically accelerate AI-powered medical research and clinical decision support, ultimately leading to better outcomes for patients.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Synthetic4Health: Generating Annotated Synthetic Clinical Letters
Libo Ren, Samuel Belkadi, Lifeng Han, Warren Del-Pinto, Goran Nenadic
Since clinical letters contain sensitive information, clinical-related datasets can not be widely applied in model training, medical research, and teaching. This work aims to generate reliable, various, and de-identified synthetic clinical letters. To achieve this goal, we explored different pre-trained language models (PLMs) for masking and generating text. After that, we worked on Bio_ClinicalBERT, a high-performing model, and experimented with different masking strategies. Both qualitative and quantitative methods were used for evaluation. Additionally, a downstream task, Named Entity Recognition (NER), was also implemented to assess the usability of these synthetic letters. The results indicate that 1) encoder-only models outperform encoder-decoder models. 2) Among encoder-only models, those trained on general corpora perform comparably to those trained on clinical data when clinical information is preserved. 3) Additionally, preserving clinical entities and document structure better aligns with our objectives than simply fine-tuning the model. 4) Furthermore, different masking strategies can impact the quality of synthetic clinical letters. Masking stopwords has a positive impact, while masking nouns or verbs has a negative effect. 5) For evaluation, BERTScore should be the primary quantitative evaluation metric, with other metrics serving as supplementary references. 6) Contextual information does not significantly impact the models' understanding, so the synthetic clinical letters have the potential to replace the original ones in downstream tasks.
Read more9/17/2024
0
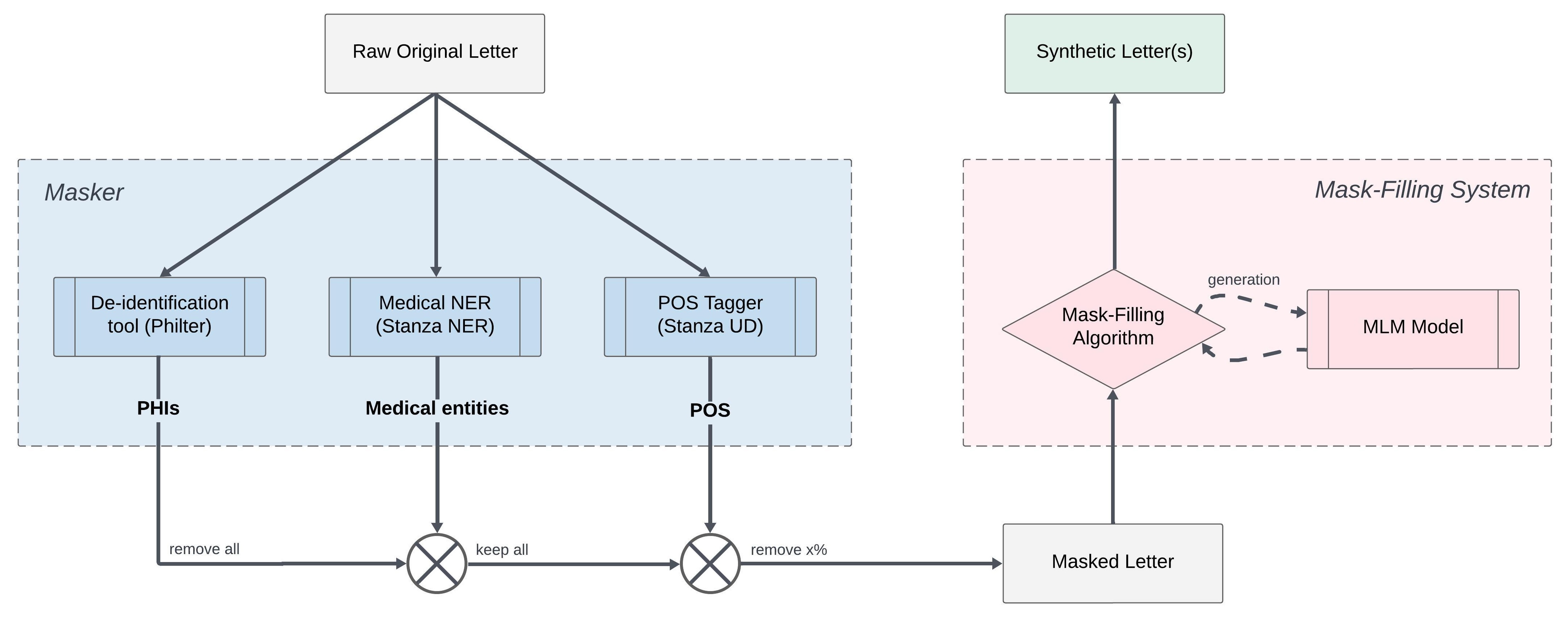
New!Generating Synthetic Free-text Medical Records with Low Re-identification Risk using Masked Language Modeling
Samuel Belkadi, Libo Ren, Nicolo Micheletti, Lifeng Han, Goran Nenadic
In this paper, we present a system that generates synthetic free-text medical records, such as discharge summaries, admission notes and doctor correspondences, using Masked Language Modeling (MLM). Our system is designed to preserve the critical information of the records while introducing significant diversity and minimizing re-identification risk. The system incorporates a de-identification component that uses Philter to mask Protected Health Information (PHI), followed by a Medical Entity Recognition (NER) model to retain key medical information. We explore various masking ratios and mask-filling techniques to balance the trade-off between diversity and fidelity in the synthetic outputs without affecting overall readability. Our results demonstrate that the system can produce high-quality synthetic data with significant diversity while achieving a HIPAA-compliant PHI recall rate of 0.96 and a low re-identification risk of 0.035. Furthermore, downstream evaluations using a NER task reveal that the synthetic data can be effectively used to train models with performance comparable to those trained on real data. The flexibility of the system allows it to be adapted for specific use cases, making it a valuable tool for privacy-preserving data generation in medical research and healthcare applications.
Read more9/18/2024
💬
0
Utilizing Large Language Models to Generate Synthetic Data to Increase the Performance of BERT-Based Neural Networks
Chancellor R. Woolsey, Prakash Bisht, Joshua Rothman, Gondy Leroy
An important issue impacting healthcare is a lack of available experts. Machine learning (ML) models could resolve this by aiding in diagnosing patients. However, creating datasets large enough to train these models is expensive. We evaluated large language models (LLMs) for data creation. Using Autism Spectrum Disorders (ASD), we prompted ChatGPT and GPT-Premium to generate 4,200 synthetic observations to augment existing medical data. Our goal is to label behaviors corresponding to autism criteria and improve model accuracy with synthetic training data. We used a BERT classifier pre-trained on biomedical literature to assess differences in performance between models. A random sample (N=140) from the LLM-generated data was evaluated by a clinician and found to contain 83% correct example-label pairs. Augmenting data increased recall by 13% but decreased precision by 16%, correlating with higher quality and lower accuracy across pairs. Future work will analyze how different synthetic data traits affect ML outcomes.
Read more5/14/2024
🎯
0
Enhancing Clinical Documentation with Synthetic Data: Leveraging Generative Models for Improved Accuracy
Anjanava Biswas, Wrick Talukdar
Accurate and comprehensive clinical documentation is crucial for delivering high-quality healthcare, facilitating effective communication among providers, and ensuring compliance with regulatory requirements. However, manual transcription and data entry processes can be time-consuming, error-prone, and susceptible to inconsistencies, leading to incomplete or inaccurate medical records. This paper proposes a novel approach to augment clinical documentation by leveraging synthetic data generation techniques to generate realistic and diverse clinical transcripts. We present a methodology that combines state-of-the-art generative models, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), with real-world clinical transcript and other forms of clinical data to generate synthetic transcripts. These synthetic transcripts can then be used to supplement existing documentation workflows, providing additional training data for natural language processing models and enabling more accurate and efficient transcription processes. Through extensive experiments on a large dataset of anonymized clinical transcripts, we demonstrate the effectiveness of our approach in generating high-quality synthetic transcripts that closely resemble real-world data. Quantitative evaluation metrics, including perplexity scores and BLEU scores, as well as qualitative assessments by domain experts, validate the fidelity and utility of the generated synthetic transcripts. Our findings highlight synthetic data generation's potential to address clinical documentation challenges, improving patient care, reducing administrative burdens, and enhancing healthcare system efficiency.
Read more6/12/2024