A Systematic Investigation of Distilling Large Language Models into Cross-Encoders for Passage Re-ranking

0
💬
Sign in to get full access
Overview
- Large language models are highly effective for information retrieval tasks, but are computationally expensive.
- The researchers investigate whether insights from fine-tuning cross-encoders on manually labeled data can be used to distill large language models into more efficient cross-encoder models.
- They introduce a new dataset, Rank-DistiLLM, to explore techniques like hard-negative sampling, deep sampling, and listwise loss functions for language model distillation.
Plain English Explanation
Large language models like BERT and GPT-3 are incredibly powerful for tasks like text generation and information retrieval. However, these models are also very computationally expensive, making them difficult to use in real-world applications with limited resources.
The researchers in this paper explore a way to "distill" the knowledge from these large language models into a smaller, more efficient cross-encoder model. Cross-encoders are models that can take two pieces of text (like a query and a document) and score how well they match. The researchers find that cross-encoders distilled from large language models are more effective at this re-ranking task than cross-encoders that are directly fine-tuned on manually labeled data.
However, the distilled models still don't quite reach the same level of effectiveness as the original large language models. To address this, the researchers create a new dataset called Rank-DistiLLM, which they use to train cross-encoders. This dataset incorporates techniques like "hard-negative sampling" and "deep sampling" that have been shown to be effective for fine-tuning cross-encoders. The goal is to see if these insights from manual fine-tuning can also be applied to distilling large language models.
The researchers find that the cross-encoders trained on the Rank-DistiLLM dataset are able to reach the effectiveness of the large language models, while still being much more efficient to run. This could make it practical to deploy powerful information retrieval systems in real-world applications with limited compute resources.
Technical Explanation
The researchers start by observing that cross-encoders distilled from large language models are more effective as re-rankers than cross-encoders fine-tuned directly on manually labeled data. However, these distilled models still do not match the performance of the original large language models.
To investigate whether insights from manual fine-tuning can improve language model distillation, the researchers construct a new dataset called Rank-DistiLLM. This dataset incorporates techniques like:
- Hard-negative sampling: Selecting "hard" negative examples (i.e., documents that are very similar to the relevant document but not actually relevant) to improve the model's ability to distinguish relevant from near-relevant content.
- Deep sampling: Sampling from a deep retrieval system to get a wider range of hard negatives, rather than just relying on the top results from a simple retrieval system.
- Listwise loss functions: Using loss functions that consider the ranking of all documents in a result set, rather than just pairwise comparisons.
The researchers then use this Rank-DistiLLM dataset to train cross-encoder models and find that they are able to match the effectiveness of the original large language models, while being orders of magnitude more efficient to run. This suggests that the insights from manual fine-tuning of cross-encoders can indeed be transferred to the language model distillation process.
The researchers release the Rank-DistiLLM dataset and their code to the public, enabling other researchers to build on their work and further explore efficient approaches to distilling large language models for real-world applications.
Critical Analysis
The researchers have made a compelling case for the value of their Rank-DistiLLM dataset and the techniques they used to train cross-encoder models that can match the effectiveness of large language models. However, there are a few potential limitations and areas for further exploration:
-
The researchers only evaluated their models on the MS-MARCO passage ranking task. It would be valuable to see how the Rank-DistiLLM-trained cross-encoders perform on a wider range of information retrieval benchmarks, including full-document retrieval and other domains.
-
The paper does not provide much insight into the specific trade-offs between the efficiency and effectiveness of the distilled cross-encoders compared to the original large language models. A more detailed analysis of inference speed, model size, and other relevant metrics would help users understand the practical implications of this work.
-
While the researchers show that the Rank-DistiLLM-trained cross-encoders can match the performance of large language models, it's unclear whether this approach would generalize to distilling multiple different large language models. Further research is needed to understand the broader applicability of these techniques.
Overall, this is a well-designed study that makes a valuable contribution to the field of efficient information retrieval systems. The open-sourcing of the Rank-DistiLLM dataset and code will undoubtedly spur further research and innovation in this area.
Conclusion
The researchers in this paper have demonstrated an effective approach for distilling large language models into smaller, more efficient cross-encoder models for information retrieval tasks. By creating a new dataset, Rank-DistiLLM, and incorporating techniques like hard-negative sampling and listwise loss functions, they were able to train cross-encoders that matched the effectiveness of the original large language models.
This work is significant because it opens the door to deploying powerful language-based information retrieval systems in real-world applications with limited computational resources. The researchers' findings suggest that the insights gained from manual fine-tuning of cross-encoders can be successfully applied to the language model distillation process, leading to a new class of high-performance, efficient models.
By making the Rank-DistiLLM dataset and their code publicly available, the researchers have laid the groundwork for further advancements in this area. Future work could explore the broader applicability of these techniques, as well as investigate additional ways to optimize the efficiency-effectiveness trade-off for language-based retrieval systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
A Systematic Investigation of Distilling Large Language Models into Cross-Encoders for Passage Re-ranking
Ferdinand Schlatt, Maik Frobe, Harrisen Scells, Shengyao Zhuang, Bevan Koopman, Guido Zuccon, Benno Stein, Martin Potthast, Matthias Hagen
Cross-encoders distilled from large language models (LLMs) are often more effective re-rankers than cross-encoders fine-tuned on manually labeled data. However, the distilled models usually do not reach their teacher LLM's effectiveness. To investigate whether best practices for fine-tuning cross-encoders on manually labeled data (e.g., hard-negative sampling, deep sampling, and listwise loss functions) can help to improve LLM ranker distillation, we construct and release a new distillation dataset: Rank-DistiLLM. In our experiments, cross-encoders trained on Rank-DistiLLM reach the effectiveness of LLMs while being orders of magnitude more efficient. Our code and data is available at https://github.com/webis-de/msmarco-llm-distillation.
Read more6/18/2024

0
How to Make Cross Encoder a Good Teacher for Efficient Image-Text Retrieval?
Yuxin Chen, Zongyang Ma, Ziqi Zhang, Zhongang Qi, Chunfeng Yuan, Bing Li, Junfu Pu, Ying Shan, Xiaojuan Qi, Weiming Hu
Dominant dual-encoder models enable efficient image-text retrieval but suffer from limited accuracy while the cross-encoder models offer higher accuracy at the expense of efficiency. Distilling cross-modality matching knowledge from cross-encoder to dual-encoder provides a natural approach to harness their strengths. Thus we investigate the following valuable question: how to make cross-encoder a good teacher for dual-encoder? Our findings are threefold:(1) Cross-modal similarity score distribution of cross-encoder is more concentrated while the result of dual-encoder is nearly normal making vanilla logit distillation less effective. However ranking distillation remains practical as it is not affected by the score distribution.(2) Only the relative order between hard negatives conveys valid knowledge while the order information between easy negatives has little significance.(3) Maintaining the coordination between distillation loss and dual-encoder training loss is beneficial for knowledge transfer. Based on these findings we propose a novel Contrastive Partial Ranking Distillation (CPRD) method which implements the objective of mimicking relative order between hard negative samples with contrastive learning. This approach coordinates with the training of the dual-encoder effectively transferring valid knowledge from the cross-encoder to the dual-encoder. Extensive experiments on image-text retrieval and ranking tasks show that our method surpasses other distillation methods and significantly improves the accuracy of dual-encoder.
Read more7/11/2024

0
Learning Effective Representations for Retrieval Using Self-Distillation with Adaptive Relevance Margins
Lukas Gienapp, Niklas Deckers, Martin Potthast, Harrisen Scells
Representation-based retrieval models, so-called biencoders, estimate the relevance of a document to a query by calculating the similarity of their respective embeddings. Current state-of-the-art biencoders are trained using an expensive training regime involving knowledge distillation from a teacher model and batch-sampling. Instead of relying on a teacher model, we contribute a novel parameter-free loss function for self-supervision that exploits the pre-trained language modeling capabilities of the encoder model as a training signal, eliminating the need for batch sampling by performing implicit hard negative mining. We investigate the capabilities of our proposed approach through extensive ablation studies, demonstrating that self-distillation can match the effectiveness of teacher distillation using only 13.5% of the data, while offering a speedup in training time between 3x and 15x compared to parametrized losses. Code and data is made openly available.
Read more8/1/2024
0
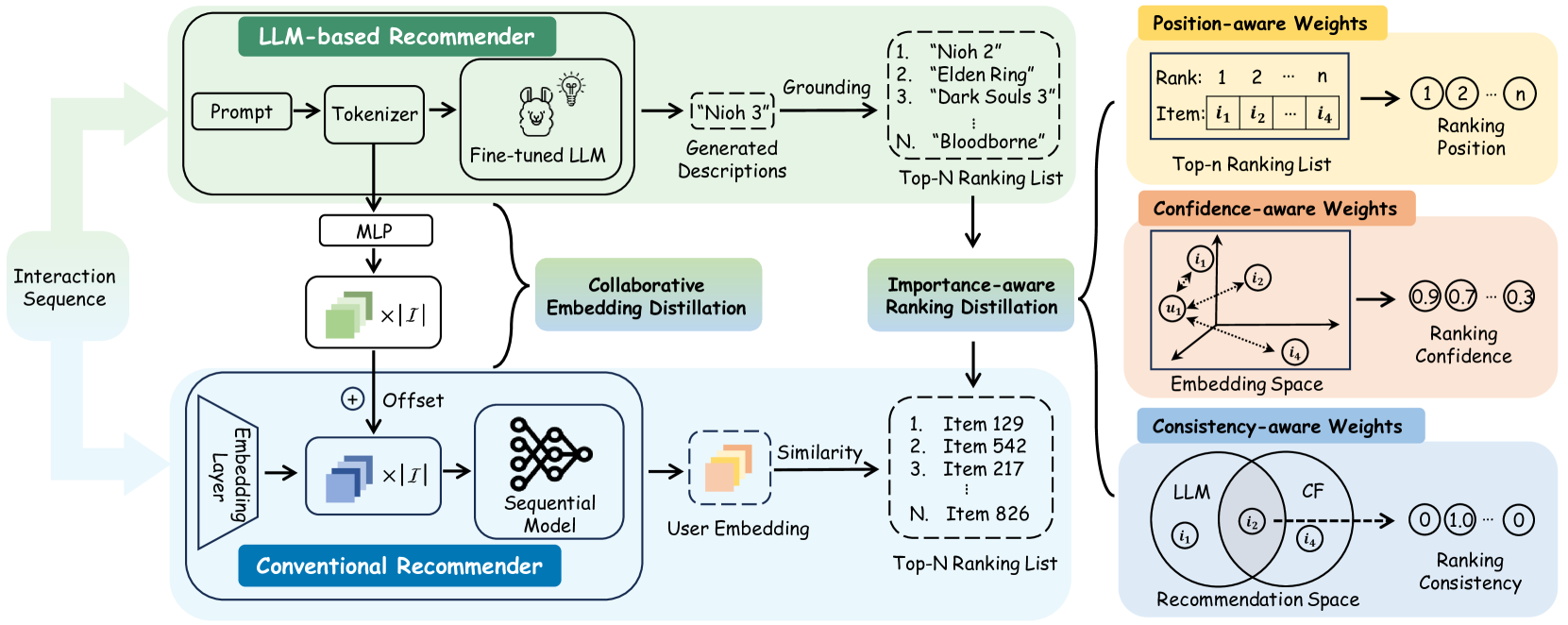
Distillation Matters: Empowering Sequential Recommenders to Match the Performance of Large Language Model
Yu Cui, Feng Liu, Pengbo Wang, Bohao Wang, Heng Tang, Yi Wan, Jun Wang, Jiawei Chen
Owing to their powerful semantic reasoning capabilities, Large Language Models (LLMs) have been effectively utilized as recommenders, achieving impressive performance. However, the high inference latency of LLMs significantly restricts their practical deployment. To address this issue, this work investigates knowledge distillation from cumbersome LLM-based recommendation models to lightweight conventional sequential models. It encounters three challenges: 1) the teacher's knowledge may not always be reliable; 2) the capacity gap between the teacher and student makes it difficult for the student to assimilate the teacher's knowledge; 3) divergence in semantic space poses a challenge to distill the knowledge from embeddings. To tackle these challenges, this work proposes a novel distillation strategy, DLLM2Rec, specifically tailored for knowledge distillation from LLM-based recommendation models to conventional sequential models. DLLM2Rec comprises: 1) Importance-aware ranking distillation, which filters reliable and student-friendly knowledge by weighting instances according to teacher confidence and student-teacher consistency; 2) Collaborative embedding distillation integrates knowledge from teacher embeddings with collaborative signals mined from the data. Extensive experiments demonstrate the effectiveness of the proposed DLLM2Rec, boosting three typical sequential models with an average improvement of 47.97%, even enabling them to surpass LLM-based recommenders in some cases.
Read more8/21/2024