TaCo: Targeted Concept Removal in Output Embeddings for NLP via Information Theory and Explainability

0

Sign in to get full access
Overview
- The paper "TaCo: Targeted Concept Removal in Output Embeddings for NLP via Information Theory and Explainability" proposes a method to selectively remove specific concepts from language model output embeddings.
- The goal is to address issues like gender bias in natural language processing (NLP) models by identifying and removing problematic concepts from the model's internal representations.
- The method leverages information theory and explainability techniques to identify and remove target concepts in a controlled and transparent manner.
Plain English Explanation
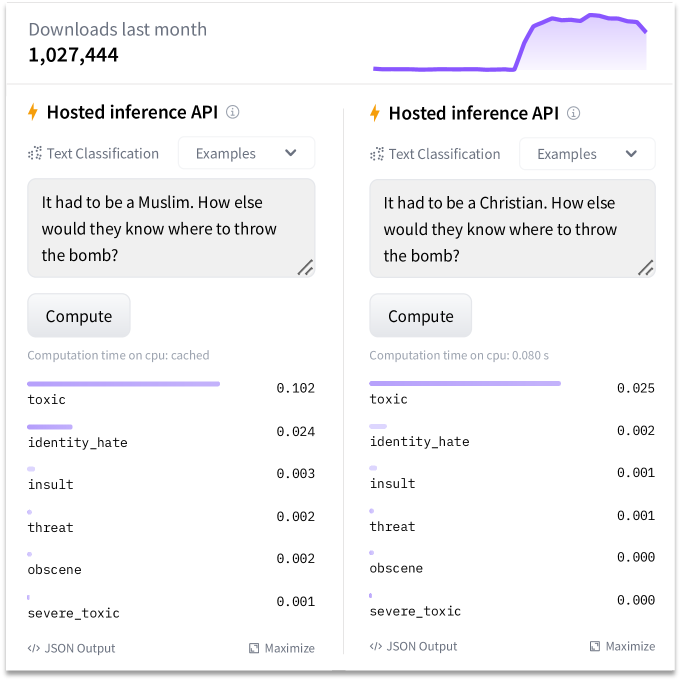
Language models, the underlying technology behind many modern NLP applications, can sometimes exhibit undesirable biases, like associating certain words or concepts with specific genders. The paper on robust concept erasure and the work on inference-time rule erasing have addressed this issue in the past.
The researchers behind "TaCo" have developed a new approach to tackle this problem. Their key insight is that by understanding which specific concepts are driving these biases in the language model, they can selectively remove those concepts from the model's internal representations, called embeddings. This allows them to "de-bias" the model without losing its overall capabilities.
The method works by first identifying the target concepts to be removed, such as gender associations. It then uses information theory techniques to quantify the importance of these concepts in the model's outputs. Finally, it applies an "erasure" process to remove the identified concepts from the model's embeddings in a controlled way.
By making the process transparent and targeted, the researchers aim to provide a more interpretable and less disruptive approach to addressing bias in language models, compared to more blunt techniques like simply retraining the entire model. This could help unlock the full potential of these powerful AI systems while ensuring they behave in a more ethical and inclusive manner.
Technical Explanation
The key technical contributions of the "TaCo" paper are:
-
Targeted Concept Identification: The researchers develop a method to identify the specific concepts in a language model's output embeddings that are driving undesirable biases, such as gender associations. This is done using information theory techniques like mutual information to quantify the importance of different concepts.
-
Concept Erasure: Once the target concepts have been identified, the researchers apply an "erasure" process to remove them from the model's output embeddings. This is done in a controlled and interpretable way, preserving the overall capabilities of the language model while selectively removing the problematic concepts.
-
Evaluation: The researchers evaluate their approach on several NLP tasks, demonstrating that they can effectively remove specific concepts (like gender associations) from the language model's outputs without significantly degrading its overall performance.
The technical details of the concept identification and erasure processes are quite complex, involving information theory, explainability techniques, and constrained optimization. However, the key insight is that by targeting and removing only the specific problematic concepts, rather than retraining the entire model, the researchers can achieve more nuanced and interpretable de-biasing of language models.
This work builds on previous efforts, like the paper on language-informed visual concept learning and the research on semantic stealth attacks, to better understand and control the internal representations of language models.
Critical Analysis
The "TaCo" paper presents a promising approach to addressing bias in language models, but it also raises some important questions and caveats:
-
Generalizability: The paper focuses on removing gender associations, but it's unclear how well the method would generalize to other types of biases or concepts that may be more complex or less well-defined.
-
Interpretability Limitations: While the researchers aim to make the process more interpretable, the technical details of the concept identification and erasure processes are still quite complex. More work may be needed to truly democratize the understanding of these methods.
-
Potential Unintended Consequences: Removing specific concepts from language model embeddings could have unforeseen consequences for the model's behavior and performance. Careful evaluation and monitoring would be crucial to ensure the approach does not introduce new issues.
-
Scope of Application: The paper focuses on de-biasing the language model's output embeddings, but it's unclear how this would translate to real-world applications where the model is integrated into larger systems and workflows.
Despite these caveats, the "TaCo" paper represents an important step forward in addressing bias in language models through a targeted and interpretable approach. As the field of AI ethics and responsible development continues to evolve, techniques like this will be crucial for unlocking the full potential of these powerful technologies while ensuring they are deployed in a fair and inclusive manner.
Conclusion
The "TaCo" paper presents a novel method for selectively removing problematic concepts, such as gender associations, from the output embeddings of language models. By leveraging information theory and explainability techniques, the researchers have developed a more targeted and interpretable approach to addressing bias in NLP systems.
While the technical details are complex, the core insight of the paper – that it's possible to surgically remove specific undesirable concepts from a language model's internal representations without significantly degrading its overall capabilities – is a significant advance in the field of AI ethics and responsible development.
As language models become increasingly ubiquitous in a wide range of applications, techniques like "TaCo" will be crucial for ensuring these powerful AI systems are deployed in a fair and inclusive manner, unlocking their full potential while mitigating unintended biases and harms. The paper's contributions lay the groundwork for a more nuanced and transparent approach to bias mitigation in NLP, with important implications for the future of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TaCo: Targeted Concept Removal in Output Embeddings for NLP via Information Theory and Explainability
Fanny Jourdan, Louis B'ethune, Agustin Picard, Laurent Risser, Nicholas Asher
The fairness of Natural Language Processing (NLP) models has emerged as a crucial concern. Information theory indicates that to achieve fairness, a model should not be able to predict sensitive variables, such as gender, ethnicity, and age. However, information related to these variables often appears implicitly in language, posing a challenge in identifying and mitigating biases effectively. To tackle this issue, we present a novel approach that operates at the embedding level of an NLP model, independent of the specific architecture. Our method leverages insights from recent advances in XAI techniques and employs an embedding transformation to eliminate implicit information from a selected variable. By directly manipulating the embeddings in the final layer, our approach enables a seamless integration into existing models without requiring significant modifications or retraining. In evaluation, we show that the proposed post-hoc approach significantly reduces gender-related associations in NLP models while preserving the overall performance and functionality of the models. An implementation of our method is available: https://github.com/fanny-jourdan/TaCo
Read more4/15/2024
0
fairBERTs: Erasing Sensitive Information Through Semantic and Fairness-aware Perturbations
Jinfeng Li, Yuefeng Chen, Xiangyu Liu, Longtao Huang, Rong Zhang, Hui Xue
Pre-trained language models (PLMs) have revolutionized both the natural language processing research and applications. However, stereotypical biases (e.g., gender and racial discrimination) encoded in PLMs have raised negative ethical implications for PLMs, which critically limits their broader applications. To address the aforementioned unfairness issues, we present fairBERTs, a general framework for learning fair fine-tuned BERT series models by erasing the protected sensitive information via semantic and fairness-aware perturbations generated by a generative adversarial network. Through extensive qualitative and quantitative experiments on two real-world tasks, we demonstrate the great superiority of fairBERTs in mitigating unfairness while maintaining the model utility. We also verify the feasibility of transferring adversarial components in fairBERTs to other conventionally trained BERT-like models for yielding fairness improvements. Our findings may shed light on further research on building fairer fine-tuned PLMs.
Read more7/12/2024
🤖
0
Linear Adversarial Concept Erasure
Shauli Ravfogel, Michael Twiton, Yoav Goldberg, Ryan Cotterell
Modern neural models trained on textual data rely on pre-trained representations that emerge without direct supervision. As these representations are increasingly being used in real-world applications, the inability to emph{control} their content becomes an increasingly important problem. We formulate the problem of identifying and erasing a linear subspace that corresponds to a given concept, in order to prevent linear predictors from recovering the concept. We model this problem as a constrained, linear maximin game, and show that existing solutions are generally not optimal for this task. We derive a closed-form solution for certain objectives, and propose a convex relaxation, method, that works well for others. When evaluated in the context of binary gender removal, the method recovers a low-dimensional subspace whose removal mitigates bias by intrinsic and extrinsic evaluation. We show that the method is highly expressive, effectively mitigating bias in deep nonlinear classifiers while maintaining tractability and interpretability.
Read more9/14/2024

0
Privacy-oriented manipulation of speaker representations
Francisco Teixeira, Alberto Abad, Bhiksha Raj, Isabel Trancoso
Speaker embeddings are ubiquitous, with applications ranging from speaker recognition and diarization to speech synthesis and voice anonymisation. The amount of information held by these embeddings lends them versatility, but also raises privacy concerns. Speaker embeddings have been shown to contain information on age, sex, health and more, which speakers may want to keep private, especially when this information is not required for the target task. In this work, we propose a method for removing and manipulating private attributes from speaker embeddings that leverages a Vector-Quantized Variational Autoencoder architecture, combined with an adversarial classifier and a novel mutual information loss. We validate our model on two attributes, sex and age, and perform experiments with ignorant and fully-informed attackers, and with in-domain and out-of-domain data.
Read more9/12/2024