fairBERTs: Erasing Sensitive Information Through Semantic and Fairness-aware Perturbations

0
Sign in to get full access
Overview
- Presents a method called "fairBERTs" that can erase sensitive information from text while preserving overall semantics and fairness
- Focuses on mitigating bias in large language models by perturbing inputs to remove sensitive attributes
- Proposes a novel adversarial perturbation technique that modifies text to remove sensitive information while maintaining the overall meaning
Plain English Explanation
The paper introduces a technique called "fairBERTs" that can alter text in a way that removes sensitive information, such as details about a person's race, gender, or other attributes, while still preserving the overall meaning and context of the text. This is important because large language models, which are AI systems trained on vast amounts of text data, can sometimes pick up and reflect biases present in that data.
By perturbing or modifying the text inputs to these models in a targeted way, the researchers were able to reduce the amount of sensitive information the models could latch onto, without significantly changing the meaning of the text. This helps make the models more fair and unbiased in their outputs, which is crucial for applications like language model bias mitigation where sensitive attributes need to be removed.
The key insight is that you can tweak the text in semantic and fairness-aware ways, rather than just removing sensitive words or phrases. This allows the model to maintain the overall context and flow of the text, while selectively erasing the parts that could lead to biased outputs. The researchers tested this approach on a variety of datasets and found it was effective at reducing bias without heavily distorting the original meaning.
Technical Explanation
The paper presents a novel method called "fairBERTs" that can perform semantics-preserved distortion to remove sensitive information from text while preserving overall meaning and fairness.
The core idea is to use an adversarial perturbation technique to modify the input text in a targeted way. The researchers trained a perturbation model to generate small, semantically-meaningful changes to the text that reduce the amount of sensitive information present, without significantly altering the overall context and semantics.
This was achieved by optimizing the perturbations to minimize a multi-objective loss function that captures both the preservation of semantic similarity and the reduction of sensitive attribute prediction. The perturbation model was trained in an adversarial manner to generate perturbations that would fool a downstream sensitive attribute classifier.
Experiments were conducted on several datasets, including mental health analysis and automatically generated testing content, demonstrating the effectiveness of the fairBERTs approach in reducing bias while maintaining semantic similarity.
Critical Analysis
The paper presents a compelling approach for mitigating bias in large language models by selectively perturbing the input text. The key strength is the ability to preserve the overall meaning and context of the text while removing sensitive attributes, which is crucial for many real-world applications.
However, the paper does not address potential limitations or unintended consequences of this approach. For example, there may be cases where the perturbations inadvertently introduce new biases or distort the text in ways that are not desirable. Additionally, the effectiveness of the method may be dependent on the specific dataset and application, and further research is needed to understand its broader applicability.
It would also be beneficial to explore the interpretability and explainability of the perturbation model, as users may want to understand why certain changes were made to the text. Providing more transparency around the decision-making process could increase trust and adoption of such techniques.
Overall, the fairBERTs approach is a promising step towards fairer and more inclusive AI systems, but more research is needed to fully understand its limitations and potential risks.
Conclusion
The paper introduces a novel technique called "fairBERTs" that can remove sensitive information from text while preserving the overall semantics and fairness. By using an adversarial perturbation approach, the method is able to selectively modify the input text in a way that reduces bias in downstream language models, without significantly altering the meaning or context of the original text.
This work is an important contribution to the field of bias mitigation in large language models, as it provides a practical solution for addressing fairness issues in AI systems that rely on textual data. The ability to preserve semantic similarity while reducing sensitive attribute information has the potential to enable more inclusive and equitable applications of language technology.
However, further research is needed to fully understand the limitations and potential risks of this approach, as well as to explore ways to improve its interpretability and transparency. Nevertheless, the fairBERTs method represents a significant step forward in the ongoing effort to build fairer and more ethical AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
fairBERTs: Erasing Sensitive Information Through Semantic and Fairness-aware Perturbations
Jinfeng Li, Yuefeng Chen, Xiangyu Liu, Longtao Huang, Rong Zhang, Hui Xue
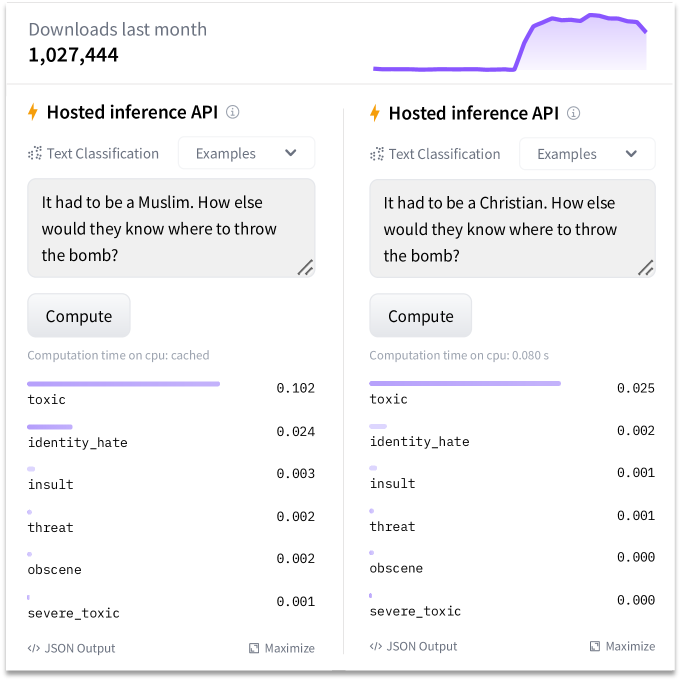
Pre-trained language models (PLMs) have revolutionized both the natural language processing research and applications. However, stereotypical biases (e.g., gender and racial discrimination) encoded in PLMs have raised negative ethical implications for PLMs, which critically limits their broader applications. To address the aforementioned unfairness issues, we present fairBERTs, a general framework for learning fair fine-tuned BERT series models by erasing the protected sensitive information via semantic and fairness-aware perturbations generated by a generative adversarial network. Through extensive qualitative and quantitative experiments on two real-world tasks, we demonstrate the great superiority of fairBERTs in mitigating unfairness while maintaining the model utility. We also verify the feasibility of transferring adversarial components in fairBERTs to other conventionally trained BERT-like models for yielding fairness improvements. Our findings may shed light on further research on building fairer fine-tuned PLMs.
Read more7/12/2024

0
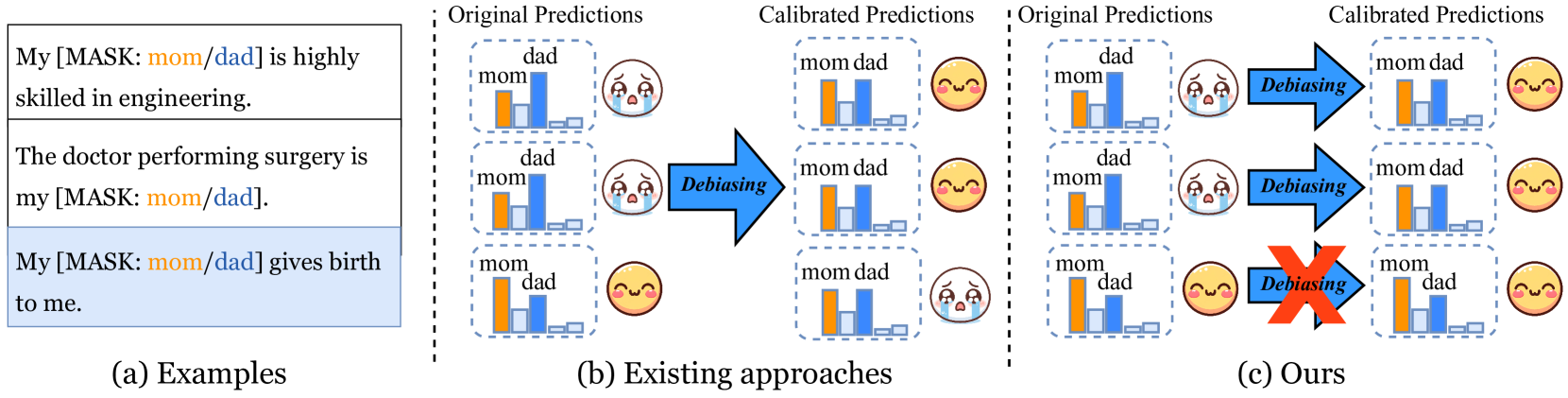
Editable Fairness: Fine-Grained Bias Mitigation in Language Models
Ruizhe Chen, Yichen Li, Jianfei Yang, Joey Tianyi Zhou, Zuozhu Liu
Generating fair and accurate predictions plays a pivotal role in deploying large language models (LLMs) in the real world. However, existing debiasing methods inevitably generate unfair or incorrect predictions as they are designed and evaluated to achieve parity across different social groups but leave aside individual commonsense facts, resulting in modified knowledge that elicits unreasonable or undesired predictions. In this paper, we first establish a new bias mitigation benchmark, BiaScope, which systematically assesses performance by leveraging newly constructed datasets and metrics on knowledge retention and generalization. Then, we propose a novel debiasing approach, Fairness Stamp (FAST), which enables fine-grained calibration of individual social biases. FAST identifies the decisive layer responsible for storing social biases and then calibrates its outputs by integrating a small modular network, considering both bias mitigation and knowledge-preserving demands. Comprehensive experiments demonstrate that FAST surpasses state-of-the-art baselines with superior debiasing performance while not compromising the overall model capability for knowledge retention and downstream predictions. This highlights the potential of fine-grained debiasing strategies to achieve fairness in LLMs. Code will be publicly available.
Read more8/23/2024
0
Large Language Model Bias Mitigation from the Perspective of Knowledge Editing
Ruizhe Chen, Yichen Li, Zikai Xiao, Zuozhu Liu
Existing debiasing methods inevitably make unreasonable or undesired predictions as they are designated and evaluated to achieve parity across different social groups but leave aside individual facts, resulting in modified existing knowledge. In this paper, we first establish a new bias mitigation benchmark BiasKE leveraging existing and additional constructed datasets, which systematically assesses debiasing performance by complementary metrics on fairness, specificity, and generalization. Meanwhile, we propose a novel debiasing method, Fairness Stamp (FAST), which enables editable fairness through fine-grained calibration on individual biased knowledge. Comprehensive experiments demonstrate that FAST surpasses state-of-the-art baselines with remarkable debiasing performance while not hampering overall model capability for knowledge preservation, highlighting the prospect of fine-grained debiasing strategies for editable fairness in LLMs.
Read more7/2/2024
0
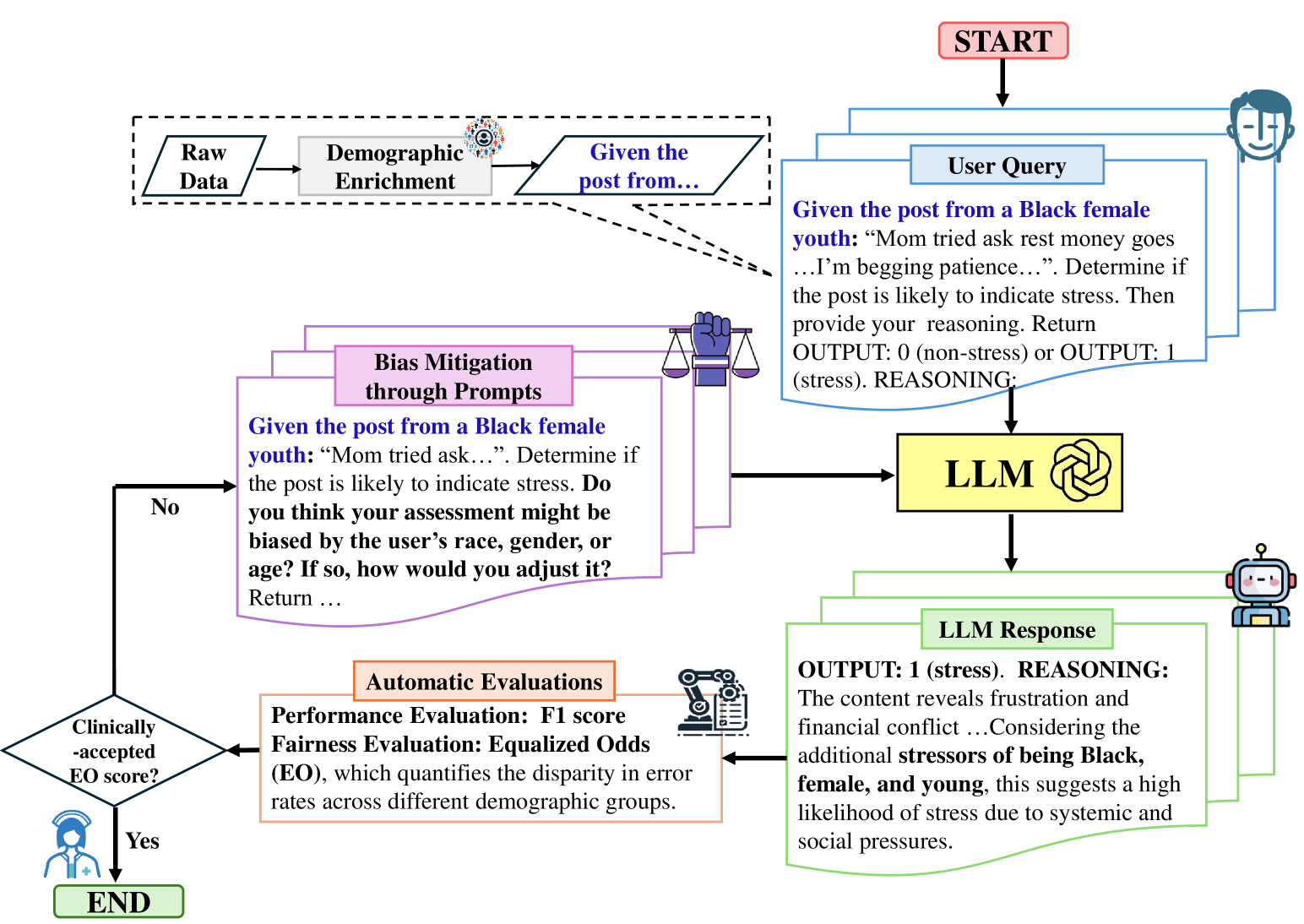
Unveiling and Mitigating Bias in Mental Health Analysis with Large Language Models
Yuqing Wang, Yun Zhao, Sara Alessandra Keller, Anne de Hond, Marieke M. van Buchem, Malvika Pillai, Tina Hernandez-Boussard
The advancement of large language models (LLMs) has demonstrated strong capabilities across various applications, including mental health analysis. However, existing studies have focused on predictive performance, leaving the critical issue of fairness underexplored, posing significant risks to vulnerable populations. Despite acknowledging potential biases, previous works have lacked thorough investigations into these biases and their impacts. To address this gap, we systematically evaluate biases across seven social factors (e.g., gender, age, religion) using ten LLMs with different prompting methods on eight diverse mental health datasets. Our results show that GPT-4 achieves the best overall balance in performance and fairness among LLMs, although it still lags behind domain-specific models like MentalRoBERTa in some cases. Additionally, our tailored fairness-aware prompts can effectively mitigate bias in mental health predictions, highlighting the great potential for fair analysis in this field.
Read more6/21/2024