TEaR: Improving LLM-based Machine Translation with Systematic Self-Refinement

0

Sign in to get full access
Overview
- This paper presents a systematic approach to improve the performance of large language models (LLMs) for machine translation tasks.
- The researchers introduce a novel technique called "Systematic Self-Correction" (SSC) that enables LLMs to iteratively refine their own translations by identifying and correcting errors.
- The paper demonstrates the effectiveness of this approach through experiments on various language pairs, showing significant improvements in translation quality compared to standard LLM-based translation models.
Plain English Explanation
The paper discusses a way to make large language models (LLMs) better at translating text from one language to another. LLMs are powerful AI systems that can understand and generate human-like text, but they can still make mistakes when used for tasks like machine translation.
The researchers developed a new technique called "Systematic Self-Correction" (SSC) that helps LLMs improve their own translations. The idea is that the LLM can analyze its own translations, identify any errors or areas for improvement, and then make corrections to produce a better translation. This self-correction process is repeated iteratively until the translation quality is optimized.
The researchers tested this approach on various language pairs, such as English to German and English to Chinese. The results showed that the LLMs using SSC were able to significantly outperform standard LLM-based translation models, producing more accurate and fluent translations.
This research is important because it demonstrates a way to make LLMs more reliable and effective for real-world translation tasks, which could have a wide range of applications, such as assisting human translators or enabling better communication across languages.
Technical Explanation
The paper introduces a novel technique called "Systematic Self-Correction" (SSC) to improve the performance of large language models (LLMs) for machine translation tasks. The SSC approach enables LLMs to iteratively refine their own translations by identifying and correcting errors.
The key components of the SSC technique are:
-
Translation Quality Estimation: The LLM is trained to assess the quality of its own translations using a metric called Translation Error Rate (TER). This allows the model to identify areas of its translations that need improvement.
-
Self-Correction: Based on the TER score, the LLM generates a new translation that aims to correct the identified errors. This self-correction process is repeated iteratively until the translation quality is optimized.
The researchers evaluated the SSC approach on various language pairs, including English to German, English to Chinese, and others. The experiments showed that LLMs using the SSC technique significantly outperformed standard LLM-based translation models in terms of translation quality, as measured by the BLEU and TER metrics.
The researchers also explored the impact of different training strategies, such as teaching the LLM to self-improve, on the effectiveness of the SSC approach. The results demonstrated the versatility and robustness of the proposed technique.
Critical Analysis
The paper presents a well-designed and thorough study, with a clear focus on improving the translation capabilities of large language models. The introduction of the Systematic Self-Correction (SSC) technique is a novel and promising approach that addresses a significant limitation of standard LLM-based translation models.
One potential limitation of the research is the reliance on the Translation Error Rate (TER) metric for quality estimation. While TER is a widely used metric, it may not capture all aspects of translation quality, such as fluency and naturalness. It would be interesting to see how the SSC approach performs when evaluated using other metrics or human judgments of translation quality.
Additionally, the paper does not explore the impact of the SSC technique on the computational complexity or efficiency of the translation process. As the iterative self-correction process adds additional steps, it would be valuable to understand the trade-offs in terms of runtime and memory usage compared to standard LLM-based translation.
Finally, the paper focuses on a limited set of language pairs, and it would be beneficial to see the SSC technique evaluated on a wider range of languages, including low-resource and more linguistically diverse language pairs, to assess its broader applicability and robustness.
Conclusion
The paper presents a promising approach to improve the performance of large language models (LLMs) for machine translation tasks. The Systematic Self-Correction (SSC) technique enables LLMs to iteratively refine their own translations by identifying and correcting errors, resulting in significant improvements in translation quality across various language pairs.
This research is an important step towards making LLM-based machine translation more reliable and effective, with potential applications in areas such as assisting human translators, language learning, and cross-lingual communication. The insights from this work could also inform the development of more advanced self-improvement capabilities for language models, contributing to the broader goal of teaching language models to self-improve.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TEaR: Improving LLM-based Machine Translation with Systematic Self-Refinement
Zhaopeng Feng, Yan Zhang, Hao Li, Bei Wu, Jiayu Liao, Wenqiang Liu, Jun Lang, Yang Feng, Jian Wu, Zuozhu Liu
Large Language Models (LLMs) have achieved impressive results in Machine Translation (MT). However, careful evaluations by human reveal that the translations produced by LLMs still contain multiple errors. Importantly, feeding back such error information into the LLMs can lead to self-refinement and result in improved translation performance. Motivated by these insights, we introduce a systematic LLM-based self-refinement translation framework, named textbf{TEaR}, which stands for textbf{T}ranslate, textbf{E}stimate, textbf{a}nd textbf{R}efine, marking a significant step forward in this direction. Our findings demonstrate that 1) our self-refinement framework successfully assists LLMs in improving their translation quality across a wide range of languages, whether it's from high-resource languages to low-resource ones or whether it's English-centric or centered around other languages; 2) TEaR exhibits superior systematicity and interpretability; 3) different estimation strategies yield varied impacts, directly affecting the effectiveness of the final corrections. Additionally, traditional neural translation models and evaluation models operate separately, often focusing on singular tasks due to their limited capabilities, while general-purpose LLMs possess the capability to undertake both tasks simultaneously. We further conduct cross-model correction experiments to investigate the potential relationship between the translation and evaluation capabilities of general-purpose LLMs. Our code and data are available at https://github.com/fzp0424/self_correct_mt
Read more6/24/2024
0
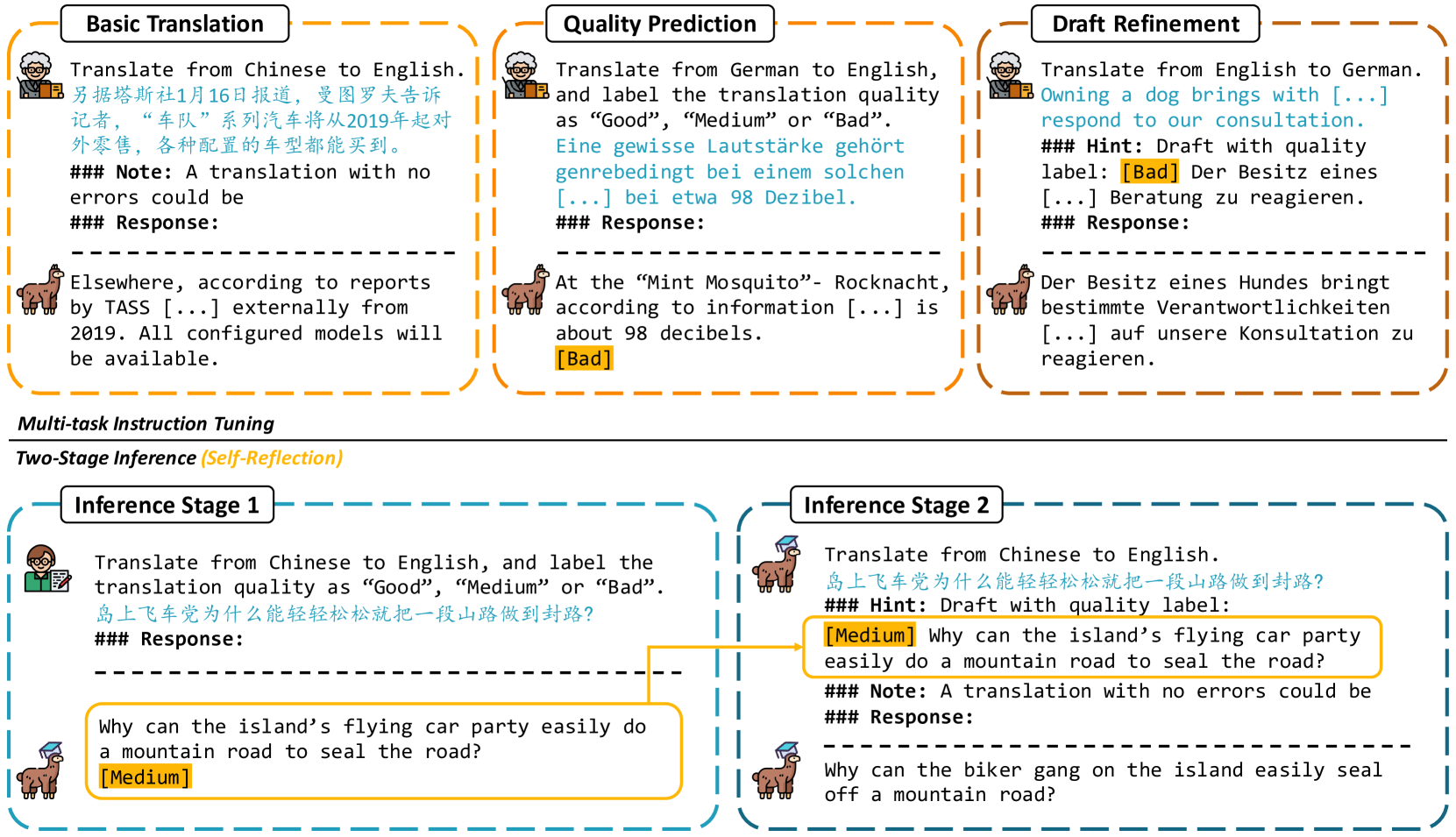
TasTe: Teaching Large Language Models to Translate through Self-Reflection
Yutong Wang, Jiali Zeng, Xuebo Liu, Fandong Meng, Jie Zhou, Min Zhang
Large language models (LLMs) have exhibited remarkable performance in various natural language processing tasks. Techniques like instruction tuning have effectively enhanced the proficiency of LLMs in the downstream task of machine translation. However, the existing approaches fail to yield satisfactory translation outputs that match the quality of supervised neural machine translation (NMT) systems. One plausible explanation for this discrepancy is that the straightforward prompts employed in these methodologies are unable to fully exploit the acquired instruction-following capabilities. To this end, we propose the TasTe framework, which stands for translating through self-reflection. The self-reflection process includes two stages of inference. In the first stage, LLMs are instructed to generate preliminary translations and conduct self-assessments on these translations simultaneously. In the second stage, LLMs are tasked to refine these preliminary translations according to the evaluation results. The evaluation results in four language directions on the WMT22 benchmark reveal the effectiveness of our approach compared to existing methods. Our work presents a promising approach to unleash the potential of LLMs and enhance their capabilities in MT. The codes and datasets are open-sourced at https://github.com/YutongWang1216/ReflectionLLMMT.
Read more6/13/2024
💬
0
Iterative Translation Refinement with Large Language Models
Pinzhen Chen, Zhicheng Guo, Barry Haddow, Kenneth Heafield
We propose iteratively prompting a large language model to self-correct a translation, with inspiration from their strong language understanding and translation capability as well as a human-like translation approach. Interestingly, multi-turn querying reduces the output's string-based metric scores, but neural metrics suggest comparable or improved quality. Human evaluations indicate better fluency and naturalness compared to initial translations and even human references, all while maintaining quality. Ablation studies underscore the importance of anchoring the refinement to the source and a reasonable seed translation for quality considerations. We also discuss the challenges in evaluation and relation to human performance and translationese.
Read more5/3/2024
0
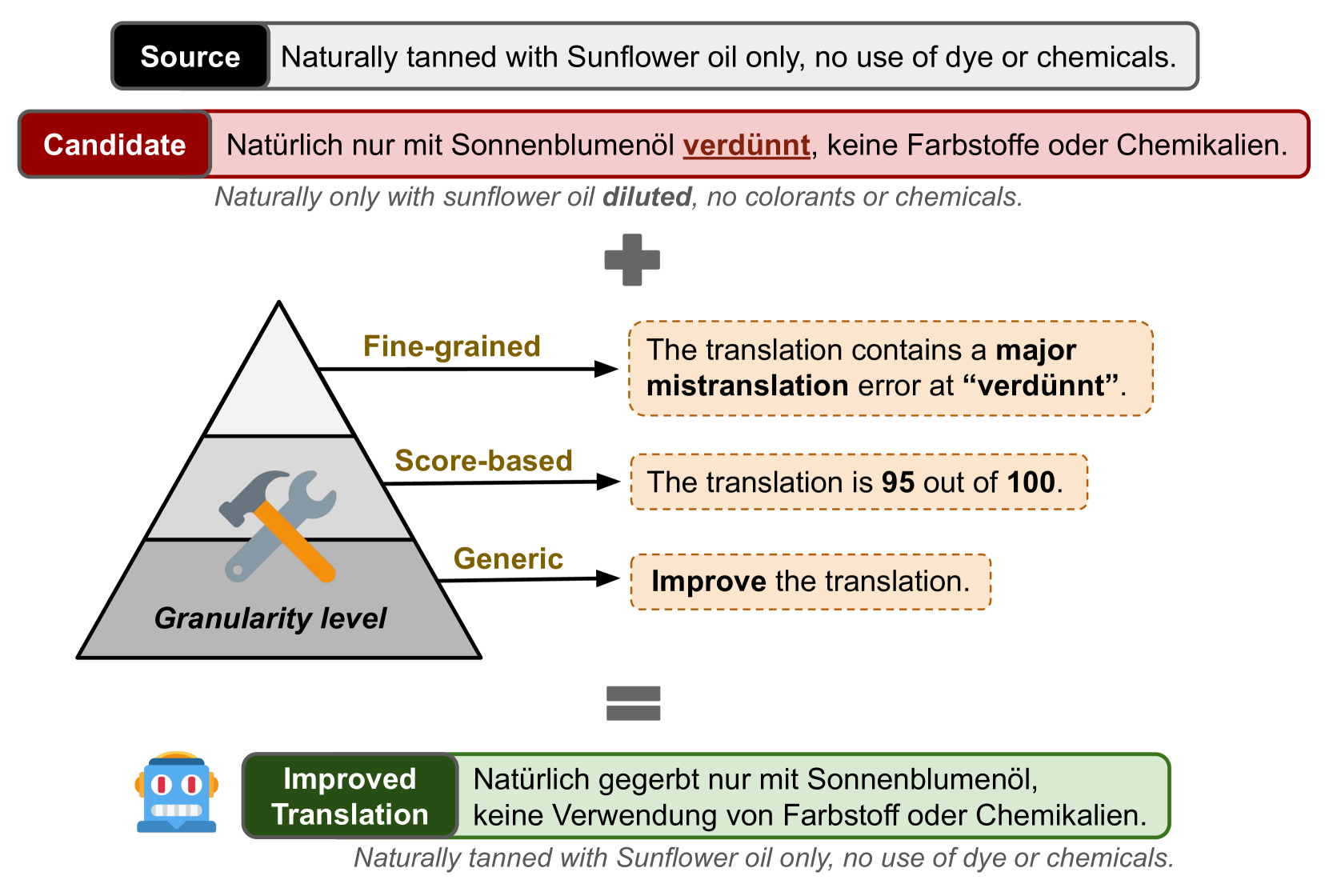
Guiding Large Language Models to Post-Edit Machine Translation with Error Annotations
Dayeon Ki, Marine Carpuat
Machine Translation (MT) remains one of the last NLP tasks where large language models (LLMs) have not yet replaced dedicated supervised systems. This work exploits the complementary strengths of LLMs and supervised MT by guiding LLMs to automatically post-edit MT with external feedback on its quality, derived from Multidimensional Quality Metric (MQM) annotations. Working with LLaMA-2 models, we consider prompting strategies varying the nature of feedback provided and then fine-tune the LLM to improve its ability to exploit the provided guidance. Through experiments on Chinese-English, English-German, and English-Russian MQM data, we demonstrate that prompting LLMs to post-edit MT improves TER, BLEU and COMET scores, although the benefits of fine-grained feedback are not clear. Fine-tuning helps integrate fine-grained feedback more effectively and further improves translation quality based on both automatic and human evaluation.
Read more4/12/2024