TexShape: Information Theoretic Sentence Embedding for Language Models

0

Sign in to get full access
Overview
- The paper introduces TexShape, a new method for learning sentence embeddings that aims to preserve information theoretic properties while achieving compression.
- The key goals are to develop sentence embeddings that are more privacy-preserving, fair, and efficient compared to existing approaches.
- The authors explore the tradeoffs between information preservation, compression, and other desirable properties of sentence embeddings.
Plain English Explanation
Sentence embeddings are a way of representing the meaning of a sentence as a compact numerical vector. This is useful for many language processing tasks, like summarizing text or finding similar sentences. However, existing sentence embedding methods can have issues with privacy, fairness, and efficiency.
The TexShape approach proposed in this paper tries to address these problems. The key idea is to learn sentence embeddings that preserve the most important information from the original text, while also being more compact and protecting sensitive details.
The authors use information theory concepts to rigorously define what "important information" means and how to best balance the tradeoffs involved. For example, they want the embeddings to retain the core meaning of each sentence while removing personal details that could compromise privacy.
Overall, TexShape aims to produce sentence embeddings that are more privacy-preserving, fair across different demographic groups, and efficient to store and compute, without sacrificing too much of the original sentence meaning. The technical details involve complex optimization problems, but the high-level goal is to make sentence embedding technology more robust and beneficial.
Technical Explanation
The paper first provides background on sentence embeddings and information theory. It then formulates the problem of learning compressed, privacy-preserving, and fair sentence embeddings as an optimization problem.
The key idea is to learn a mapping from sentences to a compact vector representation that maximizes the mutual information between the original sentence and the embedding, subject to constraints on compression, fairness, and privacy. This is achieved through a novel objective function and training procedure.
The authors evaluate TexShape on several benchmark datasets and compare it to state-of-the-art sentence embedding methods. The results show that TexShape can achieve significant compression (up to 16x) while maintaining high performance on downstream tasks and improving fairness and privacy metrics.
Importantly, the TexShape approach is model-agnostic, meaning it can be applied to enhance the embeddings produced by any base language model, like BERT or GPT. This makes it a flexible and widely applicable technique for improving the robustness and ethical alignment of sentence embedding systems.
Critical Analysis
The paper makes a compelling case for the importance of developing sentence embedding methods that prioritize properties like privacy and fairness, in addition to performance. The TexShape approach represents a thoughtful attempt to rigorously formulate and optimize these tradeoffs.
However, the authors acknowledge several limitations and areas for future work. For example, the current formulation assumes access to sensitive attributes like gender and race, which may not always be available in real-world settings. Additionally, the fairness constraints could potentially introduce new biases or unintended consequences that require further investigation.
More broadly, the reliance on mutual information as the key objective raises questions about whether this is the most appropriate or meaningful way to capture the desired properties of sentence embeddings. Alternative information-theoretic or machine learning-based approaches may be worth exploring.
Overall, the TexShape work represents an important step towards developing more robust and ethical sentence embedding technologies. However, as with any research in this domain, it is crucial to continue scrutinizing the assumptions, methods, and potential impacts to ensure these systems are deployed responsibly.
Conclusion
The TexShape paper proposes a new method for learning sentence embeddings that aims to balance the competing goals of information preservation, compression, privacy, and fairness. By framing this as an optimization problem grounded in information theory, the authors develop a flexible and principled approach that can be applied to enhance the embeddings produced by any base language model.
The results demonstrate the potential of TexShape to achieve significant compression while maintaining performance and improving key ethical properties. This work highlights the importance of proactively addressing issues like privacy and fairness in the development of language technologies, and provides a valuable framework for continued research in this direction.
As natural language processing systems become increasingly ubiquitous, it is crucial that we prioritize the development of methods that are not only effective, but also align with important societal values. The TexShape paper represents an important contribution towards this goal, and serves as a model for how to thoughtfully navigate the complex tradeoffs involved in building more robust and responsible sentence embedding systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TexShape: Information Theoretic Sentence Embedding for Language Models
Kaan Kale, Homa Esfahanizadeh, Noel Elias, Oguzhan Baser, Muriel Medard, Sriram Vishwanath
With the exponential growth in data volume and the emergence of data-intensive applications, particularly in the field of machine learning, concerns related to resource utilization, privacy, and fairness have become paramount. This paper focuses on the textual domain of data and addresses challenges regarding encoding sentences to their optimized representations through the lens of information-theory. In particular, we use empirical estimates of mutual information, using the Donsker-Varadhan definition of Kullback-Leibler divergence. Our approach leverages this estimation to train an information-theoretic sentence embedding, called TexShape, for (task-based) data compression or for filtering out sensitive information, enhancing privacy and fairness. In this study, we employ a benchmark language model for initial text representation, complemented by neural networks for information-theoretic compression and mutual information estimations. Our experiments demonstrate significant advancements in preserving maximal targeted information and minimal sensitive information over adverse compression ratios, in terms of predictive accuracy of downstream models that are trained using the compressed data.
Read more5/14/2024

0
Tracking linguistic information in transformer-based sentence embeddings through targeted sparsification
Vivi Nastase, Paola Merlo
Analyses of transformer-based models have shown that they encode a variety of linguistic information from their textual input. While these analyses have shed a light on the relation between linguistic information on one side, and internal architecture and parameters on the other, a question remains unanswered: how is this linguistic information reflected in sentence embeddings? Using datasets consisting of sentences with known structure, we test to what degree information about chunks (in particular noun, verb or prepositional phrases), such as grammatical number, or semantic role, can be localized in sentence embeddings. Our results show that such information is not distributed over the entire sentence embedding, but rather it is encoded in specific regions. Understanding how the information from an input text is compressed into sentence embeddings helps understand current transformer models and help build future explainable neural models.
Read more7/26/2024
0
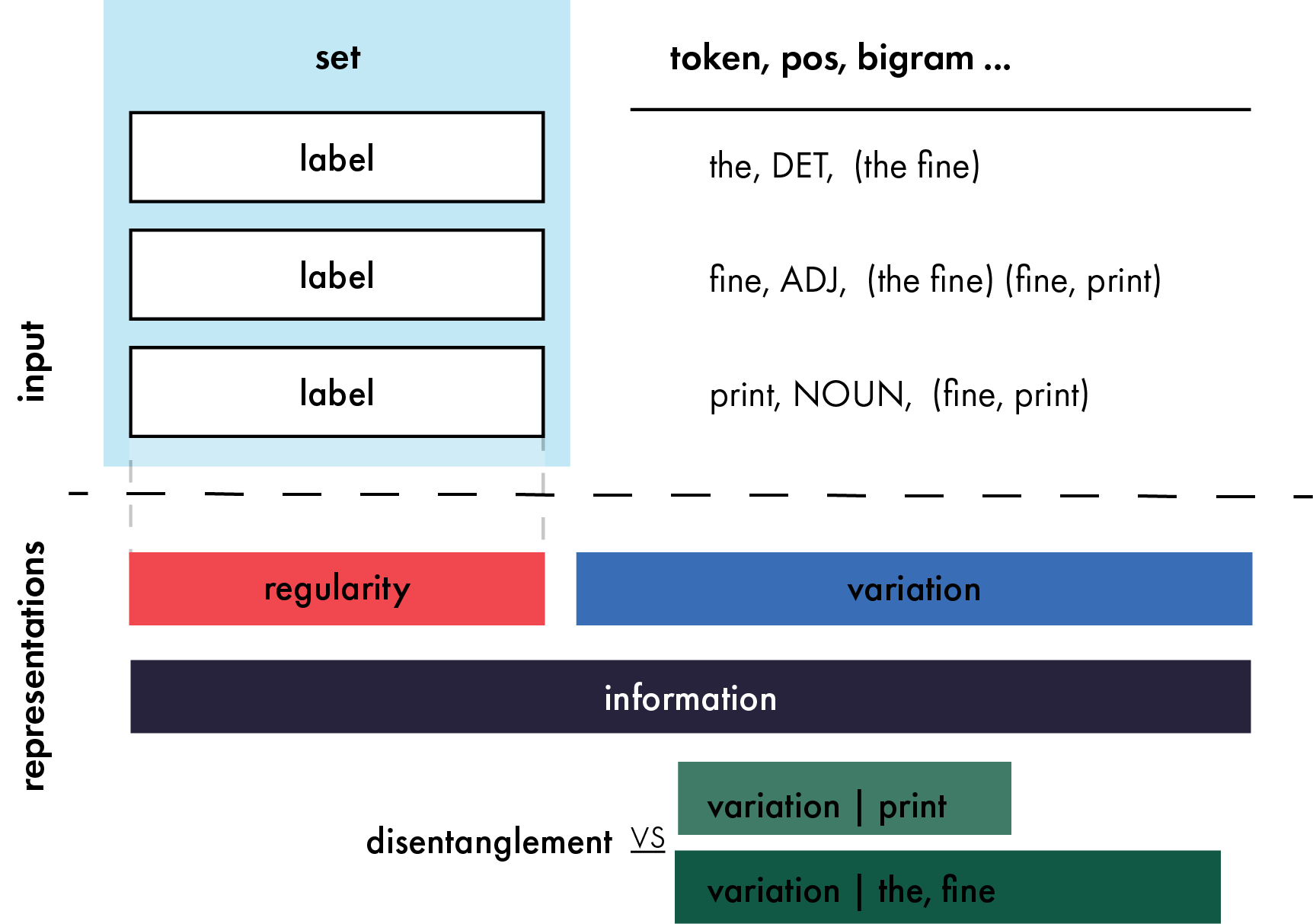
Representations as Language: An Information-Theoretic Framework for Interpretability
Henry Conklin, Kenny Smith
Large scale neural models show impressive performance across a wide array of linguistic tasks. Despite this they remain, largely, black-boxes - inducing vector-representations of their input that prove difficult to interpret. This limits our ability to understand what they learn, and when the learn it, or describe what kinds of representations generalise well out of distribution. To address this we introduce a novel approach to interpretability that looks at the mapping a model learns from sentences to representations as a kind of language in its own right. In doing so we introduce a set of information-theoretic measures that quantify how structured a model's representations are with respect to its input, and when during training that structure arises. Our measures are fast to compute, grounded in linguistic theory, and can predict which models will generalise best based on their representations. We use these measures to describe two distinct phases of training a transformer: an initial phase of in-distribution learning which reduces task loss, then a second stage where representations becoming robust to noise. Generalisation performance begins to increase during this second phase, drawing a link between generalisation and robustness to noise. Finally we look at how model size affects the structure of the representational space, showing that larger models ultimately compress their representations more than their smaller counterparts.
Read more6/5/2024
0
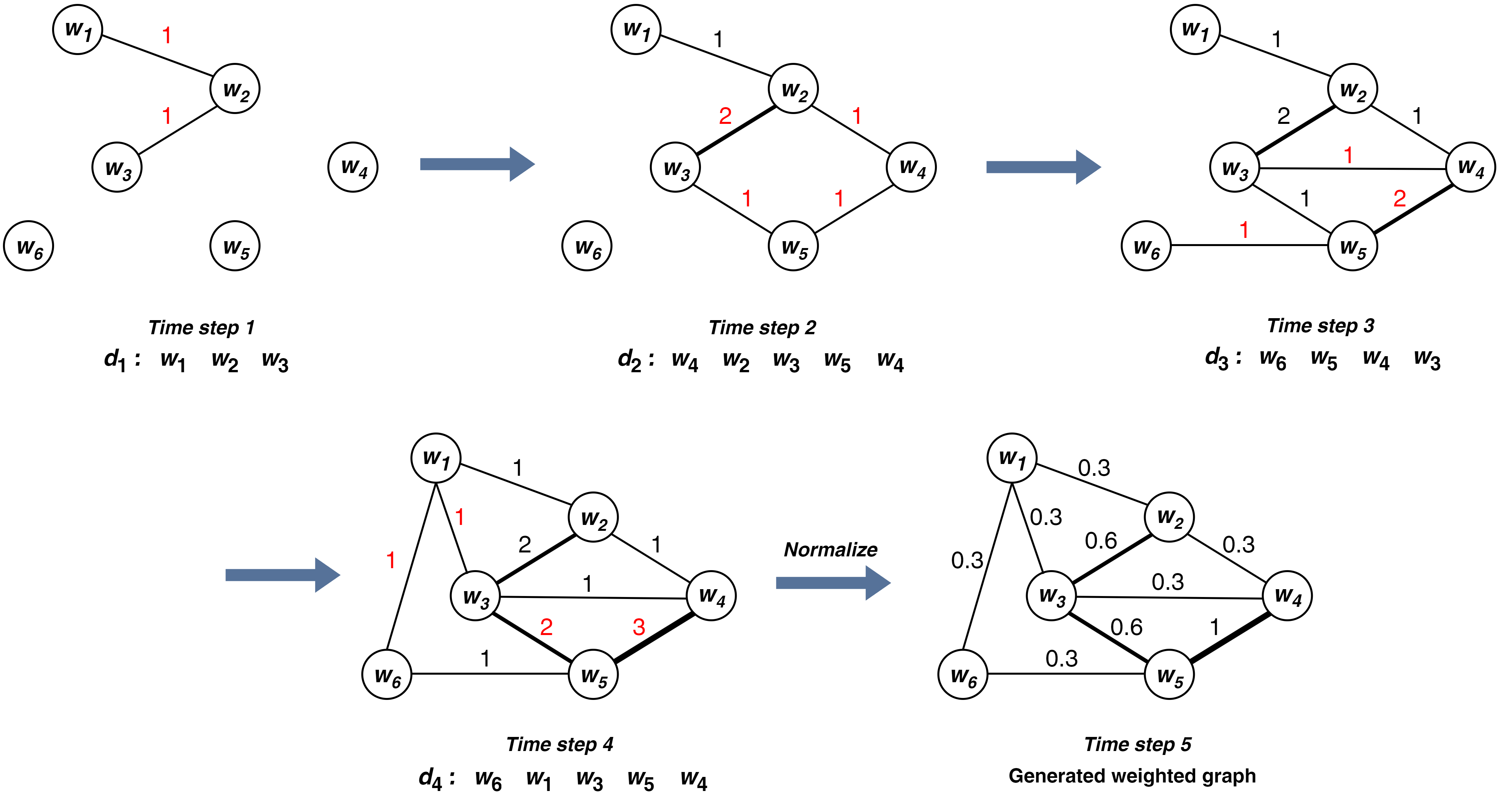
GuideWalk -- Heterogeneous Data Fusion for Enhanced Learning -- A Multiclass Document Classification Case
Sarmad N. Mohammed, Semra Gunduc{c}
One of the prime problems of computer science and machine learning is to extract information efficiently from large-scale, heterogeneous data. Text data, with its syntax, semantics, and even hidden information content, possesses an exceptional place among the data types in concern. The processing of the text data requires embedding, a method of translating the content of the text to numeric vectors. A correct embedding algorithm is the starting point for obtaining the full information content of the text data. In this work, a new text embedding approach, namely the Guided Transition Probability Matrix (GTPM) model is proposed. The model uses the graph structure of sentences to capture different types of information from text data, such as syntactic, semantic, and hidden content. Using random walks on a weighted word graph, GTPM calculates transition probabilities to derive text embedding vectors. The proposed method is tested with real-world data sets and eight well-known and successful embedding algorithms. GTPM shows significantly better classification performance for binary and multi-class datasets than well-known algorithms. Additionally, the proposed method demonstrates superior robustness, maintaining performance with limited (only $10%$) training data, showing an $8%$ decline compared to $15-20%$ for baseline methods.
Read more9/10/2024