Text-Video Retrieval with Global-Local Semantic Consistent Learning

0
🔎
Sign in to get full access
Overview
- The paper presents a new method called Global-Local Semantic Consistent Learning (GLSCL) for text-video retrieval.
- GLSCL aims to address the high computational cost and inefficiency of existing approaches that rely on transferring text-video pairs to a common embedding space and leveraging cross-modal interactions.
- The key innovations of GLSCL include a parameter-free global interaction module for coarse-grained alignment and a shared local interaction module for fine-grained alignment.
- The method also introduces an Inter-Consistency Loss (ICL) and an Intra-Diversity Loss (IDL) to further improve the semantic alignment between visual and textual queries.
Plain English Explanation
Video-Sentence Grounding with Temporally Global Textual Knowledge and other state-of-the-art text-video retrieval methods rely on computationally expensive techniques to align text and video data. GLSCL provides a simpler and more efficient approach to this problem.
The core idea is to explore the inherent semantic connections between text and video, rather than forcing them into a common embedding space. GLSCL does this in two ways:
- Global Interaction: A parameter-free module that identifies coarse-grained alignments between the overall content of the text and video.
- Local Interaction: A learnable module that captures fine-grained semantic concepts shared between specific parts of the text and video.
By focusing on these shared semantics, GLSCL can perform text-video retrieval more efficiently than existing methods, while still achieving comparable performance.
GLSCL also uses additional loss functions to further strengthen the alignment between the visual and textual queries, making the retrieved results more accurate and coherent.
Technical Explanation
The paper introduces a new method called Global-Local Semantic Consistent Learning (GLSCL) for efficient text-video retrieval. Unlike existing approaches that rely on computationally expensive techniques to transfer text-video pairs to a common embedding space, GLSCL capitalizes on the latent shared semantics across modalities.
Specifically, GLSCL includes two key components:
- Global Interaction Module: This parameter-free module explores the coarse-grained alignment between the overall content of the text and video, without the need for complex cross-modal interactions.
- Shared Local Interaction Module: This learnable module employs several queries to capture the fine-grained latent semantic concepts shared between specific parts of the text and video.
Furthermore, the authors introduce two additional loss functions:
- Inter-Consistency Loss (ICL): This loss ensures concept alignment between the visual query and the corresponding textual query.
- Intra-Diversity Loss (IDL): This loss encourages the distribution of visual (textual) queries to be more discriminative, generating more distinct semantic concepts.
The paper presents extensive experiments on five widely used benchmarks, including MSR-VTT, MSVD, DiDeMo, LSMDC, and ActivityNet. The results show that GLSCL not only achieves comparable performance to state-of-the-art methods, but is also nearly 220 times faster in terms of computational cost.
Critical Analysis
The paper presents a compelling approach to address the high computational cost and inefficiency of existing text-video retrieval methods. By focusing on the inherent semantic connections between text and video, rather than forcing them into a common embedding space, GLSCL offers a simpler and more efficient solution.
However, the paper does not provide a detailed analysis of the limitations or potential issues with the proposed method. For example, it is unclear how GLSCL would perform on more complex video-language tasks that require a deeper understanding of the semantic relationships between text and video.
Additionally, the paper could have explored the interpretability of the learned semantic concepts, as this could be important for applications where transparency and explainability are critical.
Overall, the paper presents a promising approach, but further research is needed to better understand the strengths, weaknesses, and broader applicability of GLSCL.
Conclusion
The paper introduces a new method called Global-Local Semantic Consistent Learning (GLSCL) that addresses the high computational cost and inefficiency of existing text-video retrieval approaches. By focusing on the latent shared semantics across modalities, GLSCL achieves comparable performance to state-of-the-art methods while being significantly faster.
The key innovations of GLSCL include a parameter-free global interaction module for coarse-grained alignment and a shared local interaction module for fine-grained alignment. The method also employs additional loss functions to further strengthen the semantic alignment between visual and textual queries.
While the paper presents a promising approach, further research is needed to explore the limitations and broader applicability of GLSCL, particularly in the context of more complex video-language tasks and the interpretability of the learned semantic concepts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Text-Video Retrieval with Global-Local Semantic Consistent Learning
Haonan Zhang, Pengpeng Zeng, Lianli Gao, Jingkuan Song, Yihang Duan, Xinyu Lyu, Hengtao Shen
Adapting large-scale image-text pre-training models, e.g., CLIP, to the video domain represents the current state-of-the-art for text-video retrieval. The primary approaches involve transferring text-video pairs to a common embedding space and leveraging cross-modal interactions on specific entities for semantic alignment. Though effective, these paradigms entail prohibitive computational costs, leading to inefficient retrieval. To address this, we propose a simple yet effective method, Global-Local Semantic Consistent Learning (GLSCL), which capitalizes on latent shared semantics across modalities for text-video retrieval. Specifically, we introduce a parameter-free global interaction module to explore coarse-grained alignment. Then, we devise a shared local interaction module that employs several learnable queries to capture latent semantic concepts for learning fine-grained alignment. Furthermore, an Inter-Consistency Loss (ICL) is devised to accomplish the concept alignment between the visual query and corresponding textual query, and an Intra-Diversity Loss (IDL) is developed to repulse the distribution within visual (textual) queries to generate more discriminative concepts. Extensive experiments on five widely used benchmarks (i.e., MSR-VTT, MSVD, DiDeMo, LSMDC, and ActivityNet) substantiate the superior effectiveness and efficiency of the proposed method. Remarkably, our method achieves comparable performance with SOTA as well as being nearly 220 times faster in terms of computational cost. Code is available at: https://github.com/zchoi/GLSCL.
Read more7/17/2024
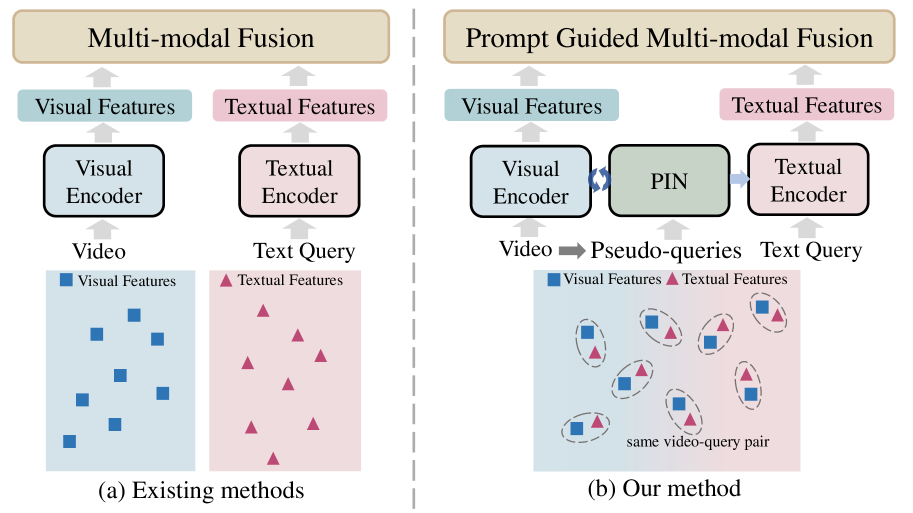
0
Video sentence grounding with temporally global textual knowledge
Cai Chen, Runzhong Zhang, Jianjun Gao, Kejun Wu, Kim-Hui Yap, Yi Wang
Temporal sentence grounding involves the retrieval of a video moment with a natural language query. Many existing works directly incorporate the given video and temporally localized query for temporal grounding, overlooking the inherent domain gap between different modalities. In this paper, we utilize pseudo-query features containing extensive temporally global textual knowledge sourced from the same video-query pair, to enhance the bridging of domain gaps and attain a heightened level of similarity between multi-modal features. Specifically, we propose a Pseudo-query Intermediary Network (PIN) to achieve an improved alignment of visual and comprehensive pseudo-query features within the feature space through contrastive learning. Subsequently, we utilize learnable prompts to encapsulate the knowledge of pseudo-queries, propagating them into the textual encoder and multi-modal fusion module, further enhancing the feature alignment between visual and language for better temporal grounding. Extensive experiments conducted on the Charades-STA and ActivityNet-Captions datasets demonstrate the effectiveness of our method.
Read more6/4/2024

0
Optimizing CLIP Models for Image Retrieval with Maintained Joint-Embedding Alignment
Konstantin Schall, Kai Uwe Barthel, Nico Hezel, Klaus Jung
Contrastive Language and Image Pairing (CLIP), a transformative method in multimedia retrieval, typically trains two neural networks concurrently to generate joint embeddings for text and image pairs. However, when applied directly, these models often struggle to differentiate between visually distinct images that have similar captions, resulting in suboptimal performance for image-based similarity searches. This paper addresses the challenge of optimizing CLIP models for various image-based similarity search scenarios, while maintaining their effectiveness in text-based search tasks such as text-to-image retrieval and zero-shot classification. We propose and evaluate two novel methods aimed at refining the retrieval capabilities of CLIP without compromising the alignment between text and image embeddings. The first method involves a sequential fine-tuning process: initially optimizing the image encoder for more precise image retrieval and subsequently realigning the text encoder to these optimized image embeddings. The second approach integrates pseudo-captions during the retrieval-optimization phase to foster direct alignment within the embedding space. Through comprehensive experiments, we demonstrate that these methods enhance CLIP's performance on various benchmarks, including image retrieval, k-NN classification, and zero-shot text-based classification, while maintaining robustness in text-to-image retrieval. Our optimized models permit maintaining a single embedding per image, significantly simplifying the infrastructure needed for large-scale multi-modal similarity search systems.
Read more9/4/2024
🌿
0
Structured Video-Language Modeling with Temporal Grouping and Spatial Grounding
Yuanhao Xiong, Long Zhao, Boqing Gong, Ming-Hsuan Yang, Florian Schroff, Ting Liu, Cho-Jui Hsieh, Liangzhe Yuan
Existing video-language pre-training methods primarily focus on instance-level alignment between video clips and captions via global contrastive learning but neglect rich fine-grained local information in both videos and text, which is of importance to downstream tasks requiring temporal localization and semantic reasoning. A powerful model is expected to be capable of capturing region-object correspondences and recognizing scene changes in a video clip, reflecting spatial and temporal granularity, respectively. To strengthen model's understanding into such fine-grained details, we propose a simple yet effective video-language modeling framework, S-ViLM, by exploiting the intrinsic structures of these two modalities. It includes two novel designs, inter-clip spatial grounding and intra-clip temporal grouping, to promote learning region-object alignment and temporal-aware features, simultaneously. Comprehensive evaluations demonstrate that S-ViLM performs favorably against existing approaches in learning more expressive representations. Specifically, S-ViLM surpasses the state-of-the-art methods substantially on four representative downstream tasks, covering text-video retrieval, video question answering, video action recognition, and temporal action localization.
Read more9/10/2024