Is Next Token Prediction Sufficient for GPT? Exploration on Code Logic Comprehension
2404.08885
0
0
Abstract
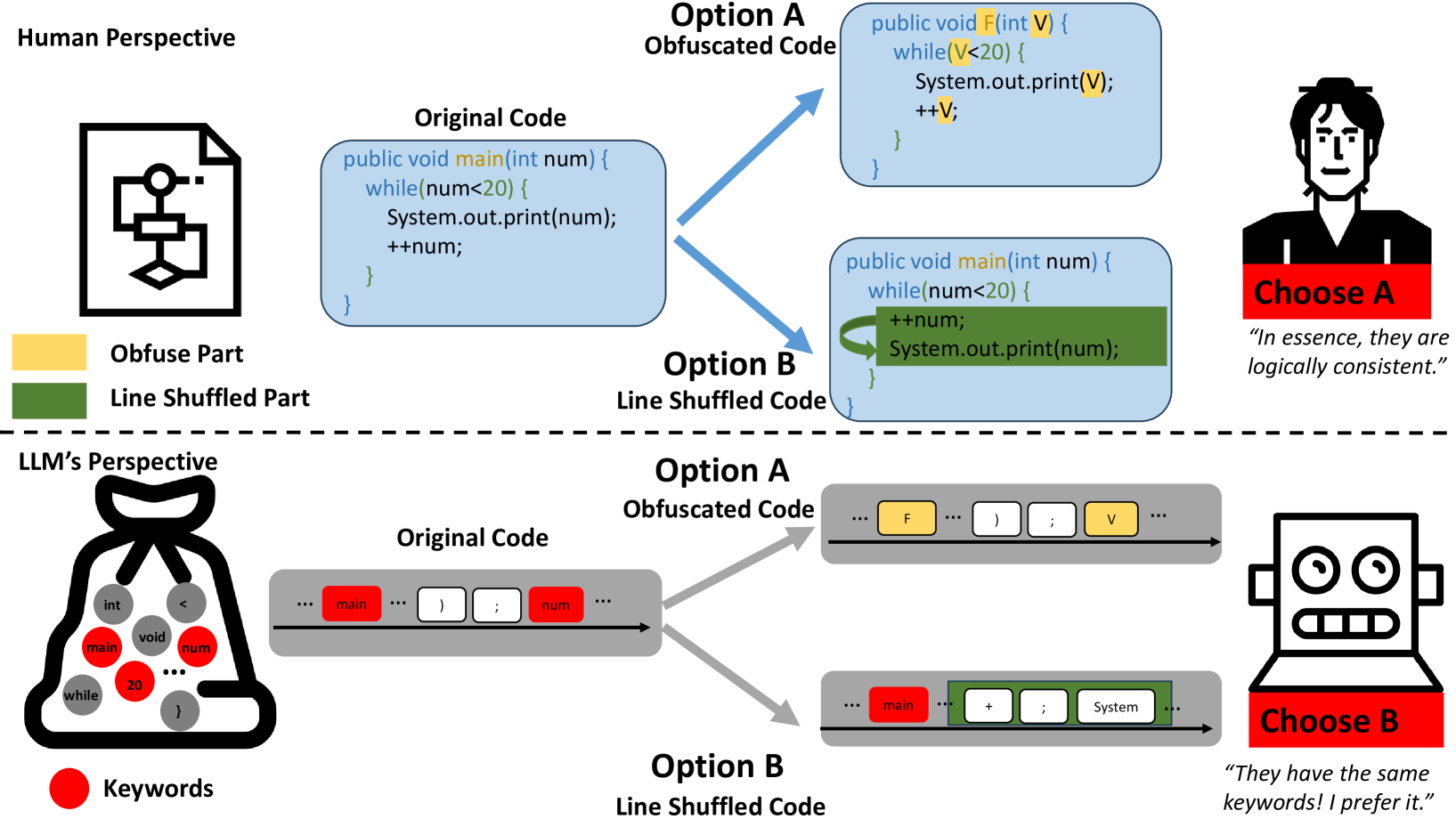
Large language models (LLMs) has experienced exponential growth, they demonstrate remarkable performance across various tasks. Notwithstanding, contemporary research primarily centers on enhancing the size and quality of pretraining data, still utilizing the next token prediction task on autoregressive transformer model structure. The efficacy of this task in truly facilitating the model's comprehension of code logic remains questionable, we speculate that it still interprets code as mere text, while human emphasizes the underlying logical knowledge. In order to prove it, we introduce a new task, Logically Equivalent Code Selection, which necessitates the selection of logically equivalent code from a candidate set, given a query code. Our experimental findings indicate that current LLMs underperform in this task, since they understand code by unordered bag of keywords. To ameliorate their performance, we propose an advanced pretraining task, Next Token Prediction+. This task aims to modify the sentence embedding distribution of the LLM without sacrificing its generative capabilities. Our experimental results reveal that following this pretraining, both Code Llama and StarCoder, the prevalent code domain pretraining models, display significant improvements on our logically equivalent code selection task and the code completion task.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores whether next token prediction is sufficient for language models like GPT to understand and reason about code logic.
- The researchers design a set of code comprehension tasks to evaluate GPT's ability to understand code logic, going beyond just predicting the next token.
- The results suggest that GPT struggles with certain code logic tasks, indicating that next token prediction may not be enough for true code understanding.
Plain English Explanation
The paper explores whether language models like GPT, which are trained to predict the next word in a sequence, are actually able to understand the underlying logic and reasoning behind code. The researchers design a set of tests that go beyond just predicting the next token in code, and instead evaluate the model's ability to comprehend the overall logic and reasoning in the code.
The results suggest that while GPT is adept at predicting the next token in code, it struggles with certain tasks that require a deeper understanding of the code's logic and reasoning. This implies that relying solely on next token prediction may not be enough for language models to truly understand and reason about code. The researchers argue that additional approaches, beyond just next token prediction, may be needed for language models to achieve human-level code comprehension.
Technical Explanation
The paper investigates whether the next token prediction ability of large language models (LLMs) like GPT is sufficient for them to understand the underlying logic and reasoning in code. The researchers design a set of code evaluation tasks that go beyond just predicting the next token, and instead assess the model's ability to comprehend the overall logic and reasoning in the code.
The key components of the paper's technical approach include:
- Code Comprehension Tasks: The researchers create a suite of tasks that test different aspects of code logic understanding, such as variable usage, control flow, and program correctness.
- Evaluation on GPT: They evaluate the performance of GPT, a prominent LLM, on these code comprehension tasks to assess its ability to reason about code logic.
- Comparison to Next Token Prediction: The paper compares the model's performance on the code comprehension tasks to its ability to simply predict the next token in the code, to understand the limitations of next token prediction for true code understanding.
The results show that while GPT performs well on next token prediction, it struggles with certain code logic comprehension tasks, suggesting that next token prediction alone may not be sufficient for LLMs to achieve human-level code understanding. The paper's findings have implications for the development of language models that can better reason about code and the overall limitations of current LLM approaches.
Critical Analysis
The paper provides a valuable exploration of the limitations of next token prediction for language models like GPT when it comes to understanding code logic. The researchers have designed a thoughtful set of tasks that go beyond just predicting the next token, and their results suggest that current LLMs may struggle with certain aspects of code comprehension.
However, it's important to note that the paper only evaluates a single model, GPT, and the tasks are limited in scope. Further research is needed to understand how other LLMs and more diverse code comprehension tasks might affect the conclusions. Additionally, the paper does not delve into the potential reasons why LLMs may struggle with certain code logic tasks, which could provide valuable insights for improving model design and training.
Overall, the paper makes a compelling case that next token prediction may not be sufficient for true code understanding, and it highlights the need for more sophisticated approaches to develop language models that can reason about code at a deeper level.
Conclusion
This paper explores the limitations of using next token prediction as the sole basis for evaluating the code comprehension abilities of large language models like GPT. By designing a set of tasks that go beyond just predicting the next token, the researchers found that GPT struggles with certain aspects of understanding code logic and reasoning.
The findings suggest that relying solely on next token prediction may not be enough for language models to achieve human-level code comprehension. The paper highlights the need for more sophisticated approaches and additional research to develop models that can truly understand and reason about the underlying logic and reasoning in code.
These insights have important implications for the development of language models that can be effectively applied to code-related tasks, as well as the broader challenge of achieving artificial general intelligence (AGI) that can reason about the world at a deeper level.
Related Papers
💬
Better & Faster Large Language Models via Multi-token Prediction
Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozi`ere, David Lopez-Paz, Gabriel Synnaeve
0
0
Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results in higher sample efficiency. More specifically, at each position in the training corpus, we ask the model to predict the following n tokens using n independent output heads, operating on top of a shared model trunk. Considering multi-token prediction as an auxiliary training task, we measure improved downstream capabilities with no overhead in training time for both code and natural language models. The method is increasingly useful for larger model sizes, and keeps its appeal when training for multiple epochs. Gains are especially pronounced on generative benchmarks like coding, where our models consistently outperform strong baselines by several percentage points. Our 13B parameter models solves 12 % more problems on HumanEval and 17 % more on MBPP than comparable next-token models. Experiments on small algorithmic tasks demonstrate that multi-token prediction is favorable for the development of induction heads and algorithmic reasoning capabilities. As an additional benefit, models trained with 4-token prediction are up to 3 times faster at inference, even with large batch sizes.
5/1/2024
💬
NExT: Teaching Large Language Models to Reason about Code Execution
Ansong Ni, Miltiadis Allamanis, Arman Cohan, Yinlin Deng, Kensen Shi, Charles Sutton, Pengcheng Yin
0
0
A fundamental skill among human developers is the ability to understand and reason about program execution. As an example, a programmer can mentally simulate code execution in natural language to debug and repair code (aka. rubber duck debugging). However, large language models (LLMs) of code are typically trained on the surface textual form of programs, thus may lack a semantic understanding of how programs execute at run-time. To address this issue, we propose NExT, a method to teach LLMs to inspect the execution traces of programs (variable states of executed lines) and reason about their run-time behavior through chain-of-thought (CoT) rationales. Specifically, NExT uses self-training to bootstrap a synthetic training set of execution-aware rationales that lead to correct task solutions (e.g., fixed programs) without laborious manual annotation. Experiments on program repair tasks based on MBPP and HumanEval demonstrate that NExT improves the fix rate of a PaLM 2 model, by 26.1% and 14.3% absolute, respectively, with significantly improved rationale quality as verified by automated metrics and human raters. Our model can also generalize to scenarios where program traces are absent at test-time.
4/24/2024
Let's Ask AI About Their Programs: Exploring ChatGPT's Answers To Program Comprehension Questions
Teemu Lehtinen, Charles Koutcheme, Arto Hellas
0
0
Recent research has explored the creation of questions from code submitted by students. These Questions about Learners' Code (QLCs) are created through program analysis, exploring execution paths, and then creating code comprehension questions from these paths and the broader code structure. Responding to the questions requires reading and tracing the code, which is known to support students' learning. At the same time, computing education researchers have witnessed the emergence of Large Language Models (LLMs) that have taken the community by storm. Researchers have demonstrated the applicability of these models especially in the introductory programming context, outlining their performance in solving introductory programming problems and their utility in creating new learning resources. In this work, we explore the capability of the state-of-the-art LLMs (GPT-3.5 and GPT-4) in answering QLCs that are generated from code that the LLMs have created. Our results show that although the state-of-the-art LLMs can create programs and trace program execution when prompted, they easily succumb to similar errors that have previously been recorded for novice programmers. These results demonstrate the fallibility of these models and perhaps dampen the expectations fueled by the recent LLM hype. At the same time, we also highlight future research possibilities such as using LLMs to mimic students as their behavior can indeed be similar for some specific tasks.
4/19/2024
Can LLMs perform structured graph reasoning?
Palaash Agrawal, Shavak Vasania, Cheston Tan
0
0
Pretrained Large Language Models (LLMs) have demonstrated various reasoning capabilities through language-based prompts alone, particularly in unstructured task settings (tasks purely based on language semantics). However, LLMs often struggle with structured tasks, because of the inherent incompatibility of input representation. Reducing structured tasks to uni-dimensional language semantics often renders the problem trivial. Keeping the trade-off between LLM compatibility and structure complexity in mind, we design various graph reasoning tasks as a proxy to semi-structured tasks in this paper, in order to test the ability to navigate through representations beyond plain text in various LLMs. Particularly, we design 10 distinct problems of graph traversal, each representing increasing levels of complexity, and benchmark 5 different instruct-finetuned LLMs (GPT-4, GPT-3.5, Claude-2, Llama-2 and Palm-2) on the aforementioned tasks. Further, we analyse the performance of models across various settings such as varying sizes of graphs as well as different forms of k-shot prompting. We highlight various limitations, biases and properties of LLMs through this benchmarking process, such as an inverse relation to the average degrees of freedom of traversal per node in graphs, the overall negative impact of k-shot prompting on graph reasoning tasks, and a positive response bias which prevents LLMs from identifying the absence of a valid solution. Finally, we introduce a new prompting technique specially designed for graph traversal tasks (PathCompare), which demonstrates a notable increase in the performance of LLMs in comparison to standard prompting techniques such as Chain-of-Thought (CoT).
4/19/2024