TICKing All the Boxes: Generated Checklists Improve LLM Evaluation and Generation

10
Sign in to get full access
Overview
- The paper introduces a new approach to evaluating and generating checklists for large language models (LLMs).
- The proposed approach, called TICK (Transparent, Interpretable, and Customizable Checklists), generates customized checklists to assess the capabilities of LLMs.
- TICK checklists are designed to be transparent, interpretable, and customizable, allowing for more comprehensive and targeted model evaluation.
Plain English Explanation
The paper describes a new way to test and improve large language models (LLMs), which are AI systems that can generate human-like text. The researchers developed a method called TICK (Transparent, Interpretable, and Customizable Checklists) that creates custom checklists to assess the capabilities of LLMs.
Traditionally, evaluating LLMs has been challenging because they can produce a wide range of outputs, making it difficult to comprehensively test their abilities. The TICK approach aims to address this by generating customized checklists that are transparent, interpretable, and customizable. This allows researchers and developers to more thoroughly test the models and identify their strengths and weaknesses.
The key innovation of TICK is its ability to automatically generate these specialized checklists, which can cover a wide range of capabilities, from factual knowledge to reasoning and language generation. By using TICK, researchers can more effectively evaluate and improve the performance of LLMs, ultimately leading to more capable and trustworthy AI systems.
Technical Explanation
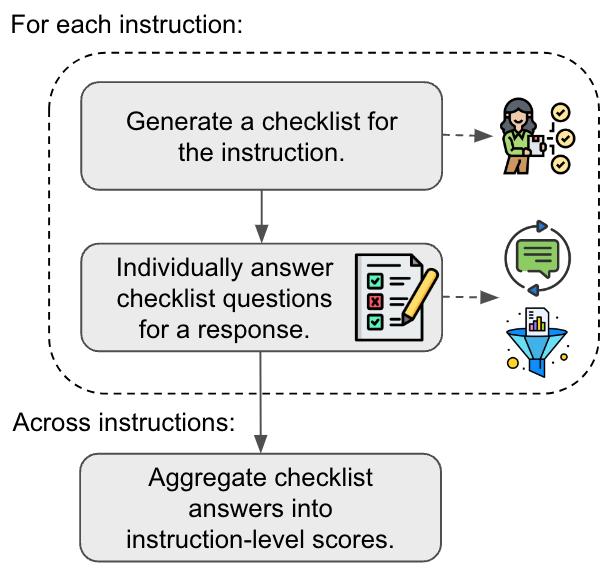
The paper introduces a new approach called TICK (Transparent, Interpretable, and Customizable Checklists) for evaluating and generating checklists for large language models (LLMs). The TICK method aims to address the challenges of comprehensively assessing the capabilities of LLMs, which can produce a wide range of outputs.
The TICK approach generates customized checklists that are designed to be transparent, interpretable, and customizable. This allows for more targeted and effective evaluation of LLMs. The checklists cover a broad range of capabilities, including factual knowledge, reasoning, and language generation.
The key technical components of the TICK approach are:
-
Checklist Generation: The system uses a combination of expert-curated prompts and language model-based generation to automatically create the checklists. This ensures the checklists are tailored to the specific LLM being evaluated.
-
Transparency and Interpretability: The checklists are designed to be transparent in their construction and interpretable in their outputs. This allows researchers and developers to understand the reasoning behind the checklist items and the model's performance on them.
-
Customization: The TICK system enables users to customize the checklists by adding, removing, or modifying checklist items to suit their specific needs and goals.
The paper presents several case studies demonstrating the effectiveness of the TICK approach in evaluating and improving the performance of LLMs on a variety of tasks. The results show that the TICK-generated checklists can provide a more comprehensive and insightful assessment of LLM capabilities compared to traditional evaluation methods.
Critical Analysis
The paper presents a compelling approach to evaluating and improving large language models (LLMs) through the use of customized checklists. The TICK method addresses several key limitations of existing evaluation techniques, such as the difficulty of comprehensively assessing the broad capabilities of LLMs.
One potential limitation of the TICK approach is the potential for bias in the expert-curated prompts used to generate the checklists. While the customization capabilities allow users to adjust the checklists, there may be inherent biases in the initial prompt selection that could influence the evaluation results. The authors acknowledge this issue and suggest further research to address it.
Another area for potential improvement is the interpretability of the checklist generation process. While the paper emphasizes the transparency and interpretability of the checklists themselves, the details of the generation algorithm could be further explained to enhance the overall understanding of the approach.
Despite these minor limitations, the TICK method represents a significant step forward in LLM evaluation and generation. By providing a more comprehensive and customizable assessment framework, the approach has the potential to drive the development of more capable and trustworthy AI systems.
Conclusion
The paper introduces a novel approach called TICK (Transparent, Interpretable, and Customizable Checklists) for evaluating and generating checklists to assess the capabilities of large language models (LLMs). The TICK method addresses the challenges of comprehensively evaluating LLMs by automatically creating customized checklists that are transparent, interpretable, and tailored to the specific model being tested.
The key contributions of the TICK approach include its ability to generate targeted checklists that cover a wide range of LLM capabilities, its emphasis on transparency and interpretability, and its customization features that allow researchers and developers to adapt the checklists to their specific needs.
By providing a more effective and comprehensive evaluation framework for LLMs, the TICK method has the potential to drive significant advancements in the development of more capable and trustworthy AI systems. The paper's case studies demonstrate the practical applications of the approach, paving the way for further research and adoption in the field of language model evaluation and improvement.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
10
New!TICKing All the Boxes: Generated Checklists Improve LLM Evaluation and Generation
Jonathan Cook, Tim Rocktaschel, Jakob Foerster, Dennis Aumiller, Alex Wang
Given the widespread adoption and usage of Large Language Models (LLMs), it is crucial to have flexible and interpretable evaluations of their instruction-following ability. Preference judgments between model outputs have become the de facto evaluation standard, despite distilling complex, multi-faceted preferences into a single ranking. Furthermore, as human annotation is slow and costly, LLMs are increasingly used to make these judgments, at the expense of reliability and interpretability. In this work, we propose TICK (Targeted Instruct-evaluation with ChecKlists), a fully automated, interpretable evaluation protocol that structures evaluations with LLM-generated, instruction-specific checklists. We first show that, given an instruction, LLMs can reliably produce high-quality, tailored evaluation checklists that decompose the instruction into a series of YES/NO questions. Each question asks whether a candidate response meets a specific requirement of the instruction. We demonstrate that using TICK leads to a significant increase (46.4% $to$ 52.2%) in the frequency of exact agreements between LLM judgements and human preferences, as compared to having an LLM directly score an output. We then show that STICK (Self-TICK) can be used to improve generation quality across multiple benchmarks via self-refinement and Best-of-N selection. STICK self-refinement on LiveBench reasoning tasks leads to an absolute gain of $+$7.8%, whilst Best-of-N selection with STICK attains $+$6.3% absolute improvement on the real-world instruction dataset, WildBench. In light of this, structured, multi-faceted self-improvement is shown to be a promising way to further advance LLM capabilities. Finally, by providing LLM-generated checklists to human evaluators tasked with directly scoring LLM responses to WildBench instructions, we notably increase inter-annotator agreement (0.194 $to$ 0.256).
Read more10/7/2024

0
Check-Eval: A Checklist-based Approach for Evaluating Text Quality
Jayr Pereira, Andre Assumpcao, Roberto Lotufo
Evaluating the quality of text generated by large language models (LLMs) remains a significant challenge. Traditional metrics often fail to align well with human judgments, particularly in tasks requiring creativity and nuance. In this paper, we propose textsc{Check-Eval}, a novel evaluation framework leveraging LLMs to assess the quality of generated text through a checklist-based approach. textsc{Check-Eval} can be employed as both a reference-free and reference-dependent evaluation method, providing a structured and interpretable assessment of text quality. The framework consists of two main stages: checklist generation and checklist evaluation. We validate textsc{Check-Eval} on two benchmark datasets: Portuguese Legal Semantic Textual Similarity and textsc{SummEval}. Our results demonstrate that textsc{Check-Eval} achieves higher correlations with human judgments compared to existing metrics, such as textsc{G-Eval} and textsc{GPTScore}, underscoring its potential as a more reliable and effective evaluation framework for natural language generation tasks. The code for our experiments is available at url{https://anonymous.4open.science/r/check-eval-0DB4}
Read more9/11/2024
💬
0
Evaluating Large Language Models at Evaluating Instruction Following
Zhiyuan Zeng, Jiatong Yu, Tianyu Gao, Yu Meng, Tanya Goyal, Danqi Chen
As research in large language models (LLMs) continues to accelerate, LLM-based evaluation has emerged as a scalable and cost-effective alternative to human evaluations for comparing the ever increasing list of models. This paper investigates the efficacy of these ``LLM evaluators'', particularly in using them to assess instruction following, a metric that gauges how closely generated text adheres to the given instruction. We introduce a challenging meta-evaluation benchmark, LLMBar, designed to test the ability of an LLM evaluator in discerning instruction-following outputs. The authors manually curated 419 pairs of outputs, one adhering to instructions while the other diverging, yet may possess deceptive qualities that mislead an LLM evaluator, e.g., a more engaging tone. Contrary to existing meta-evaluation, we discover that different evaluators (i.e., combinations of LLMs and prompts) exhibit distinct performance on LLMBar and even the highest-scoring ones have substantial room for improvement. We also present a novel suite of prompting strategies that further close the gap between LLM and human evaluators. With LLMBar, we hope to offer more insight into LLM evaluators and foster future research in developing better instruction-following models.
Read more4/17/2024

0
MIA-Bench: Towards Better Instruction Following Evaluation of Multimodal LLMs
Yusu Qian, Hanrong Ye, Jean-Philippe Fauconnier, Peter Grasch, Yinfei Yang, Zhe Gan
We introduce MIA-Bench, a new benchmark designed to evaluate multimodal large language models (MLLMs) on their ability to strictly adhere to complex instructions. Our benchmark comprises a diverse set of 400 image-prompt pairs, each crafted to challenge the models' compliance with layered instructions in generating accurate responses that satisfy specific requested patterns. Evaluation results from a wide array of state-of-the-art MLLMs reveal significant variations in performance, highlighting areas for improvement in instruction fidelity. Additionally, we create extra training data and explore supervised fine-tuning to enhance the models' ability to strictly follow instructions without compromising performance on other tasks. We hope this benchmark not only serves as a tool for measuring MLLM adherence to instructions, but also guides future developments in MLLM training methods.
Read more7/29/2024