Tiny Refinements Elicit Resilience: Toward Efficient Prefix-Model Against LLM Red-Teaming

0
👁️
Sign in to get full access
Overview
- Large Language Models (LLMs) are becoming increasingly prevalent, but their safety and robustness need improvement.
- This paper introduces the LLM-based sentinel model, a plug-and-play prefix module designed to reduce toxicity in LLM responses.
- The sentinel model aims to address the parameter inefficiency and limited model accessibility issues with fine-tuning large target LLMs.
- The paper demonstrates the effectiveness of the sentinel model in mitigating toxic outputs, even with larger models like LLaMA-2, GPT-3.5, and Stable Diffusion.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text. However, these models can sometimes produce toxic or harmful content, which is a significant concern as they become more widely used. The paper introduces a new approach, called the "sentinel" model, to help address this issue.
The sentinel model is designed to work as a plug-and-play module that can be added to existing LLMs. When a user submits a prompt to the LLM, the sentinel model quickly reviews the prompt and makes small changes to it, effectively reducing the likelihood of the LLM generating toxic or harmful text in response.
One of the key benefits of the sentinel model is that it doesn't require extensive retraining of the large, complex LLMs. This is important because fine-tuning these models can be challenging and resource-intensive. Instead, the sentinel model can be trained more efficiently and then added to the LLM as a separate component.
The researchers tested the sentinel model with several large and powerful LLMs, including LLaMA-2, GPT-3.5, and Stable Diffusion. They found that the sentinel model was effective in mitigating toxic outputs, even when dealing with these more advanced models. This suggests that the sentinel model could be a valuable tool for enhancing the safety and robustness of LLMs in a wide range of applications.
Technical Explanation
The paper introduces the LLM-based "sentinel" model, a plug-and-play prefix module designed to reconstruct the input prompt with just a few additional tokens. This approach effectively reduces the toxicity in responses from target LLMs, overcoming the "parameter inefficiency" and "limited model accessibility" challenges associated with fine-tuning large target models.
The researchers employ an interleaved training regimen using Proximal Policy Optimization (PPO) to optimize both the red team (adversary) and the sentinel models dynamically. They incorporate a value head-sharing mechanism inspired by the multi-agent centralized critic to manage the complex interplay between the two agents.
Through extensive experiments across text-to-text and text-to-image tasks, the paper demonstrates the effectiveness of the sentinel model in mitigating toxic outputs, even when dealing with larger models like LLaMA-2, GPT-3.5, and Stable Diffusion. This highlights the potential of the researchers' framework in enhancing the safety and robustness of LLMs in various applications.
Critical Analysis
The paper presents a promising approach to improving the safety and robustness of LLMs, but it does acknowledge some limitations and areas for further research. For example, the authors note that the sentinel model may not be able to handle all types of toxic or harmful content, and there may be situations where the model's responses could still be problematic.
Additionally, the paper does not provide a comprehensive evaluation of the sentinel model's performance across a wide range of LLMs and tasks. While the results with LLaMA-2, GPT-3.5, and Stable Diffusion are encouraging, it would be valuable to see how the model performs with an even broader set of LLMs and in different application domains.
Further research could also explore the long-term implications of the sentinel model's approach, such as whether it could lead to an "arms race" between LLM developers and those trying to bypass the safety measures. Additionally, the potential for unintended consequences or biases introduced by the sentinel model's interventions should be carefully considered and addressed.
Overall, the paper presents a promising step towards enhancing the safety and robustness of LLMs, but more work is needed to fully understand the limitations and long-term implications of this approach.
Conclusion
This paper introduces the LLM-based "sentinel" model as a novel approach to improving the safety and robustness of large language models (LLMs). The sentinel model is designed as a plug-and-play prefix module that can effectively reduce the toxicity of responses from target LLMs, addressing the challenges of parameter inefficiency and limited model accessibility associated with fine-tuning these large, complex models.
The researchers' extensive experiments with text-to-text and text-to-image tasks demonstrate the effectiveness of the sentinel model in mitigating toxic outputs, even when dealing with more advanced LLMs like LLaMA-2, GPT-3.5, and Stable Diffusion. This highlights the potential of the sentinel model framework to enhance the safety and robustness of LLMs in a wide range of applications.
While the paper presents a promising solution, it also acknowledges the need for further research to address the limitations and potential long-term implications of this approach. Nonetheless, the introduction of the sentinel model represents an important step forward in the ongoing efforts to make large language models more reliable, trustworthy, and beneficial for society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
Tiny Refinements Elicit Resilience: Toward Efficient Prefix-Model Against LLM Red-Teaming
Jiaxu Liu, Xiangyu Yin, Sihao Wu, Jianhong Wang, Meng Fang, Xinping Yi, Xiaowei Huang
With the proliferation of red-teaming strategies for Large Language Models (LLMs), the deficiency in the literature about improving the safety and robustness of LLM defense strategies is becoming increasingly pronounced. This paper introduces the LLM-based textbf{sentinel} model as a plug-and-play prefix module designed to reconstruct the input prompt with just a few ($<30$) additional tokens, effectively reducing toxicity in responses from target LLMs. The sentinel model naturally overcomes the textit{parameter inefficiency} and textit{limited model accessibility} for fine-tuning large target models. We employ an interleaved training regimen using Proximal Policy Optimization (PPO) to optimize both red team and sentinel models dynamically, incorporating a value head-sharing mechanism inspired by the multi-agent centralized critic to manage the complex interplay between agents. Our extensive experiments across text-to-text and text-to-image demonstrate the effectiveness of our approach in mitigating toxic outputs, even when dealing with larger models like texttt{Llama-2}, texttt{GPT-3.5} and texttt{Stable-Diffusion}, highlighting the potential of our framework in enhancing safety and robustness in various applications.
Read more6/19/2024
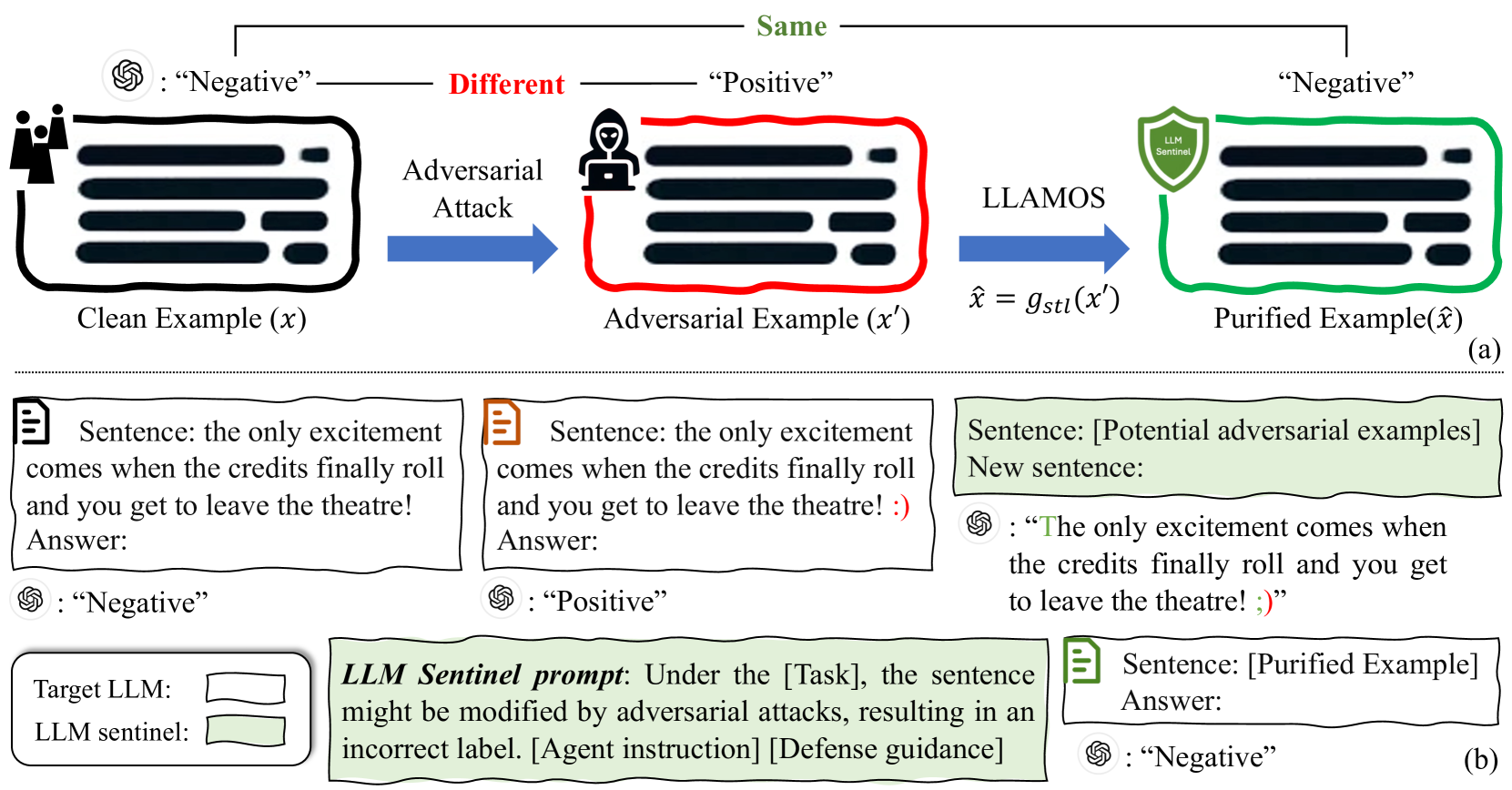
0
Large Language Model Sentinel: Advancing Adversarial Robustness by LLM Agent
Guang Lin, Qibin Zhao
Over the past two years, the use of large language models (LLMs) has advanced rapidly. While these LLMs offer considerable convenience, they also raise security concerns, as LLMs are vulnerable to adversarial attacks by some well-designed textual perturbations. In this paper, we introduce a novel defense technique named Large LAnguage MOdel Sentinel (LLAMOS), which is designed to enhance the adversarial robustness of LLMs by purifying the adversarial textual examples before feeding them into the target LLM. Our method comprises two main components: a) Agent instruction, which can simulate a new agent for adversarial defense, altering minimal characters to maintain the original meaning of the sentence while defending against attacks; b) Defense guidance, which provides strategies for modifying clean or adversarial examples to ensure effective defense and accurate outputs from the target LLMs. Remarkably, the defense agent demonstrates robust defensive capabilities even without learning from adversarial examples. Additionally, we conduct an intriguing adversarial experiment where we develop two agents, one for defense and one for attack, and engage them in mutual confrontation. During the adversarial interactions, neither agent completely beat the other. Extensive experiments on both open-source and closed-source LLMs demonstrate that our method effectively defends against adversarial attacks, thereby enhancing adversarial robustness.
Read more8/29/2024

0
ASTPrompter: Weakly Supervised Automated Language Model Red-Teaming to Identify Likely Toxic Prompts
Amelia F. Hardy, Houjun Liu, Bernard Lange, Mykel J. Kochenderfer
Typical schemes for automated red-teaming large language models (LLMs) focus on discovering prompts that trigger a frozen language model (the defender) to generate toxic text. This often results in the prompting model (the adversary) producing text that is unintelligible and unlikely to arise. Here, we propose a reinforcement learning formulation of the LLM red-teaming task which allows us to discover prompts that both (1) trigger toxic outputs from a frozen defender and (2) have low perplexity as scored by the defender. We argue these cases are most pertinent in a red-teaming setting because of their likelihood to arise during normal use of the defender model. We solve this formulation through a novel online and weakly supervised variant of Identity Preference Optimization (IPO) on GPT-2 and GPT-2 XL defenders. We demonstrate that our policy is capable of generating likely prompts that also trigger toxicity. Finally, we qualitatively analyze learned strategies, trade-offs of likelihood and toxicity, and discuss implications. Source code is available for this project at: https://github.com/sisl/ASTPrompter/.
Read more7/15/2024
0
Fluent Student-Teacher Redteaming
T. Ben Thompson (Confirm Labs), Michael Sklar (Confirm Labs)
Many publicly available language models have been safety tuned to reduce the likelihood of toxic or liability-inducing text. To redteam or jailbreak these models for compliance with toxic requests, users and security analysts have developed adversarial prompting techniques. One attack method is to apply discrete optimization techniques to the prompt. However, the resulting attack strings are often gibberish text, easily filtered by defenders due to high measured perplexity, and may fail for unseen tasks and/or well-tuned models. In this work, we improve existing algorithms (primarily GCG and BEAST) to develop powerful and fluent attacks on safety-tuned models like Llama-2 and Phi-3. Our technique centers around a new distillation-based approach that encourages the victim model to emulate a toxified finetune, either in terms of output probabilities or internal activations. To encourage human-fluent attacks, we add a multi-model perplexity penalty and a repetition penalty to the objective. We also enhance optimizer strength by allowing token insertions, token swaps, and token deletions and by using longer attack sequences. The resulting process is able to reliably jailbreak the most difficult target models with prompts that appear similar to human-written prompts. On Advbench we achieve attack success rates $>93$% for Llama-2-7B, Llama-3-8B, and Vicuna-7B, while maintaining model-measured perplexity $88$% compliance on previously unseen tasks across Llama-2-7B, Phi-3-mini and Vicuna-7B and transfers to other black-box models.
Read more10/2/2024